
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 금융문자분석경진대회
- 프로그래머스 파이썬
- Kaggle
- gs25
- 백준
- 데이콘
- Docker
- 코로나19
- SW Expert Academy
- Git
- github
- AI 경진대회
- 파이썬
- hackerrank
- ubuntu
- 더현대서울 맛집
- programmers
- leetcode
- 자연어처리
- PYTHON
- 캐치카페
- ChatGPT
- 우분투
- 편스토랑 우승상품
- 프로그래머스
- 편스토랑
- Baekjoon
- Real or Not? NLP with Disaster Tweets
- dacon
- 맥북
- Today
- Total
솜씨좋은장씨
[Kaggle DAY14]Real or Not? NLP with Disaster Tweets! 본문
[Kaggle DAY14]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 11. 21:33Kaggle 14회차!
오늘은 금융문자분석밋업때 수상자들이 사용했던 lightGBM모델을 활용해보았습니다.
Google Colab에 LightGBM설치
[Ensemble] Colab에서 LightGBM 사용하기!
원자력 발전소 상태판단 알고리즘을 도전해보면서 머신러닝을 공부하며 Gradient Boosing알고리즘 중의 하나인 LightGBM 알고리즘을 알게되었고 DACON KB 금융문자분석경진대회에서도 수상자들이 사용했다는 것을..
somjang.tistory.com
먼저 저는 Colab환경에서 진행하려고하여 위의 링크 방법대로 lightGBM을 설치해주었습니다.
!nvidia-smi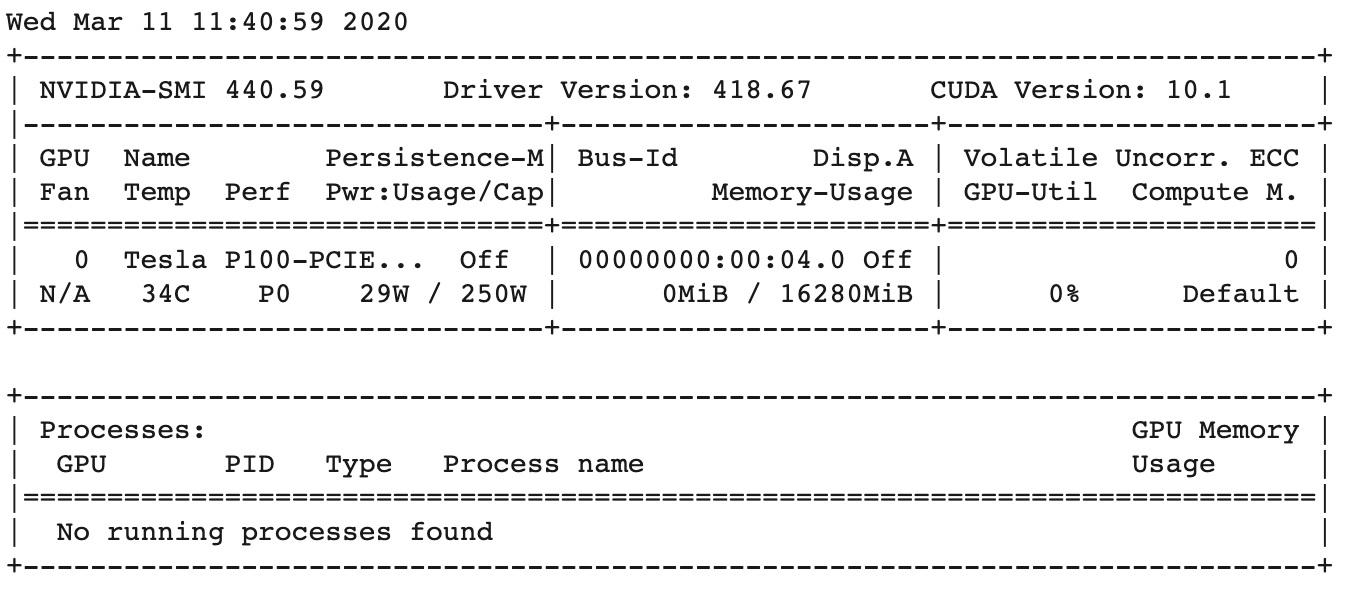
무료버전임에도 Tesla P100 GPU가 할당되어 놀랐습니다.
먼저 lightGBM모델을 사용하기위해서 데이터를 처리해주었습니다.
각각의 트윗에서
- 반복되는 알파벳 제거
- 예수님, 부처님, 알라신의 이름은 god로 통일
- https / http / ftp 주소 제거
- \n \t 문자 제거
- 숫자 제거
- 두글자 이상의 단어만 남기고 제거
- 불용어 제거
- porterstemmer로 stemming
- 특수문자 제거
import nltk
nltk.download("punkt")
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()import re
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
train_text_list = list(train['text'])
clear_text_list = []
for text in train_text_list:
text_list_corpus = text.lower()
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl=' ', string=text_list_corpus)
clear_text = clear_text.replace('\n', ' ').replace('\t', ' ')
clear_text = re.sub('[0-9]', ' ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
word_list = word_tokenize(clear_text)
word_list = [word for word in word_list if len(word) > 2]
word_list = [word for word in word_list if word not in stop_words]
word_list = [stemmer.stem(word) for word in word_list]
clear_text = ' '.join(word_list)
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', ' ', clear_text)
clear_text_list.append(clear_text)
train['clear_text'] = clear_text_list
train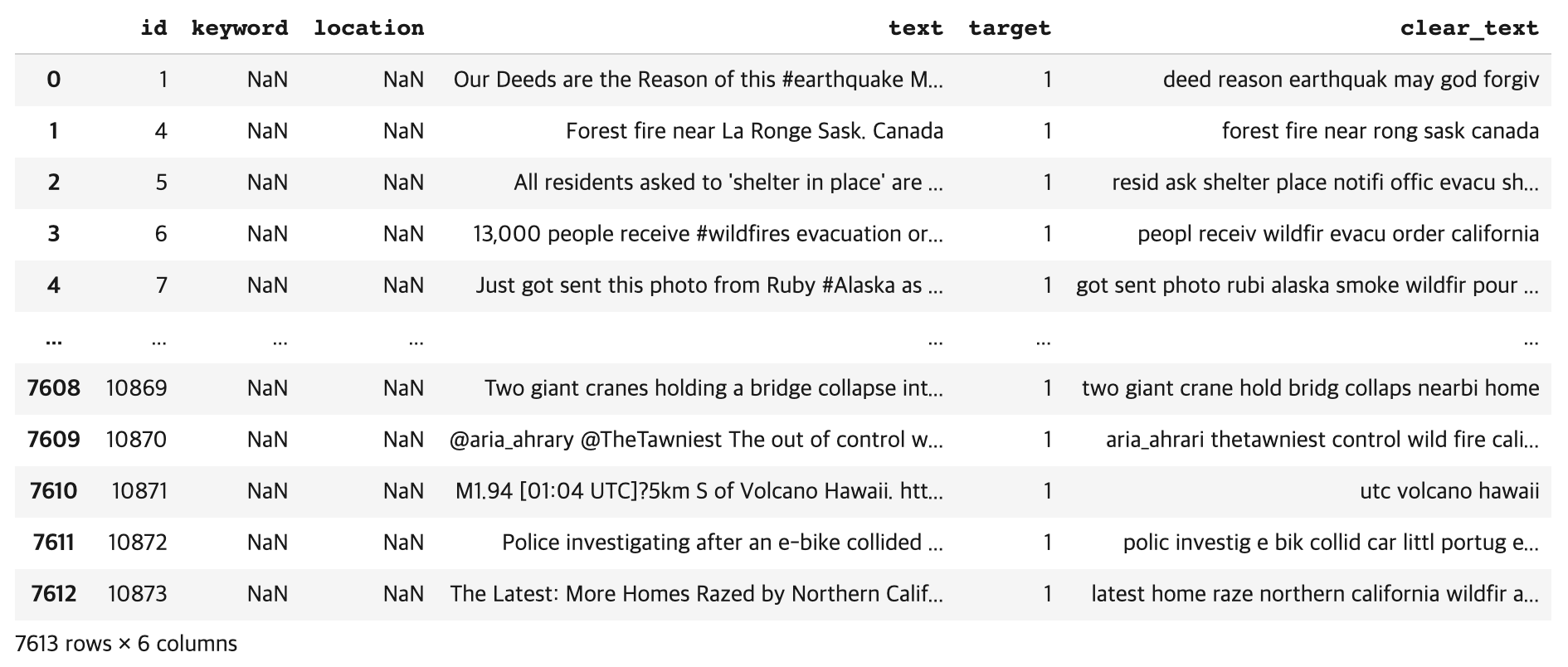
Bag of Words 만들기
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer = 'word', # 캐릭터 단위로 벡터화 할 수도 있습니다.
tokenizer = None, # 토크나이저를 따로 지정해 줄 수도 있습니다.
preprocessor = None, # 전처리 도구
stop_words = stop_words, # 불용어 nltk등의 도구를 사용할 수도 있습니다.
min_df = 2, # 토큰이 나타날 최소 문서 개수로 오타나 자주 나오지 않는 특수한 전문용어 제거에 좋다.
ngram_range=(1, 3), # BOW의 단위를 1~3개로 지정합니다.
max_features = 1721 # 만들 피처의 수, 단어의 수가 된다.
)
vectorizer
%%time
train_feature_vector = vectorizer.fit_transform(x_train['clear_text'])
train_feature_vector.shape
vocab = vectorizer.get_feature_names()
print(len(vocab))
vocab[:10]
import numpy as np
dist = np.sum(train_feature_vector, axis=0)
bog = pd.DataFrame(dist, columns=vocab)
TF-IDF 가중치 적용하기
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False)
transformer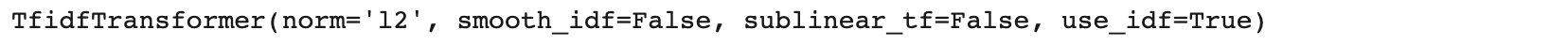
%%time
train_feature_tfidf = transformer.fit_transform(train_feature_vector)
train_feature_tfidf.shape
lightGBM으로 학습하고 결과 제출하기
y_label = x_train['target']import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import re
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import chi2_contingency
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
from subprocess import check_output
# print(check_output(["ls", "../input"]).decode("utf8"))
%matplotlib inlinefrom lightgbm import LGBMClassifier, plot_importance
lgb = LGBMClassifier()
첫번째 제출
먼저 이 기본모델을 가지고 제출해보았습니다.
%time lgb.fit(train_feature_tfidf, y_label)
%%time
test_vec = vectorizer.fit_transform(test['clear_text'])
test_vec.shape%%time
test_vec_tfidf = transformer.fit_transform(test_vec)
test_vec_tfidf.shapepred2 = lgb.predict_proba(test_vec_tfidf)
predict_labels = np.argmax(pred2, axis=1)
for i in range(len(predict_labels)):
predict_labels[i] = predict_labels[i]
ids = list(test['id'])
submission_dic = {"id":ids, "target":predict_labels}
submission_df = pd.DataFrame(submission_dic)
submission_df.to_csv('kaggle_day14.csv', index=False) #제출 파일 만들기결과

결과가 너무 나오지 않아 최적의 파라미터를 찾기위해서 GridSearchCV 방법을 사용해 보았습니다.
lgb_param_grid = {
'n_estimators' : [50, 100, 200, 300, 400],
'max_depth' : [5, 10, 15, 20]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid = GridSearchCV(lgb, param_grid=lgb_param_grid, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid.best_score_))
print("최고의 파라미터 : ", lgb_grid.best_params_)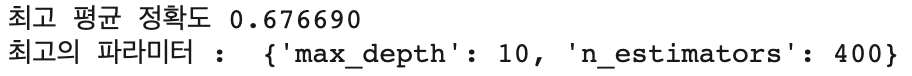
lgb_param_grid2 = {
'n_estimators' : [300, 400, 500, 600, 700, 800, 900, 1000],
'max_depth' : [10, 15, 20, 25, 30, 35]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid2 = GridSearchCV(lgb, param_grid=lgb_param_grid2, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid2.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid2.best_score_))
print("최고의 파라미터 : ", lgb_grid2.best_params_)
lgb_param_grid3 = {
'n_estimators' : [700, 800, 900, 1000, 1500, 2000, 2500, 3000, 3500, 4000],
'max_depth' : [10, 25, 30, 35, 40, 50, 60, 70]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid3 = GridSearchCV(lgb, param_grid=lgb_param_grid3, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid3.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid3.best_score_))
print("최고의 파라미터 : ", lgb_grid3.best_params_)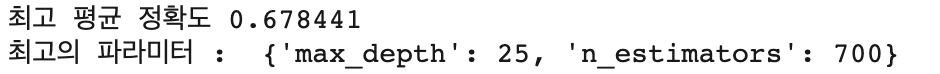
lgb_param_grid4 = {
'n_estimators' : [700, 800, 900, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 5000, 6000],
'max_depth' : [5, 10, 25]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid4 = GridSearchCV(lgb, param_grid=lgb_param_grid4, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid4.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid4.best_score_))
print("최고의 파라미터 : ", lgb_grid4.best_params_)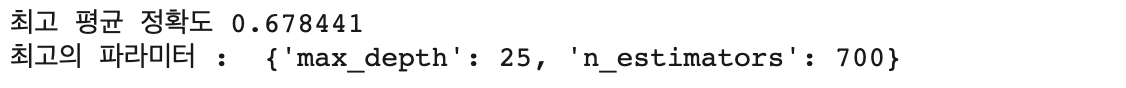
lgb_param_grid5 = {
'n_estimators' : [700, 710, 720, 730, 740, 750, 760, 770, 780, 790],
'max_depth' : [21, 22, 23, 24, 25, 26, 27, 28, 29, 30]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid5 = GridSearchCV(lgb, param_grid=lgb_param_grid5, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid5.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)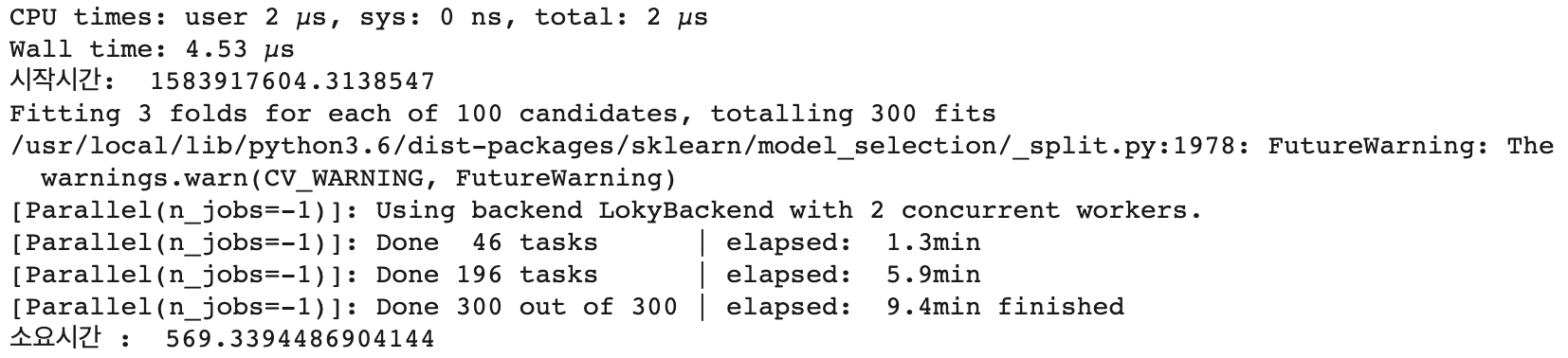
print("최고 평균 정확도 {0:4f}".format(lgb_grid5.best_score_))
print("최고의 파라미터 : ", lgb_grid5.best_params_)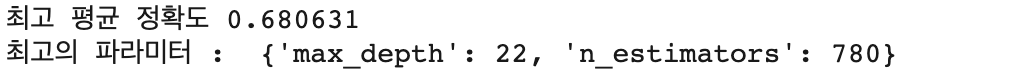
두번째 제출
lgb_best_params1 = LGBMClassifier(max_depth=22, n_estimators=780)
%time lgb_best_params1.fit(train_feature_tfidf, y_label)
결과

lgb_param_grid6 = {
'n_estimators' : [700, 800, 900, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 5000, 6000],
'max_depth' : [5, 10, 25],
'learning_rate' : [0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid6 = GridSearchCV(lgb, param_grid=lgb_param_grid6, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid6.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)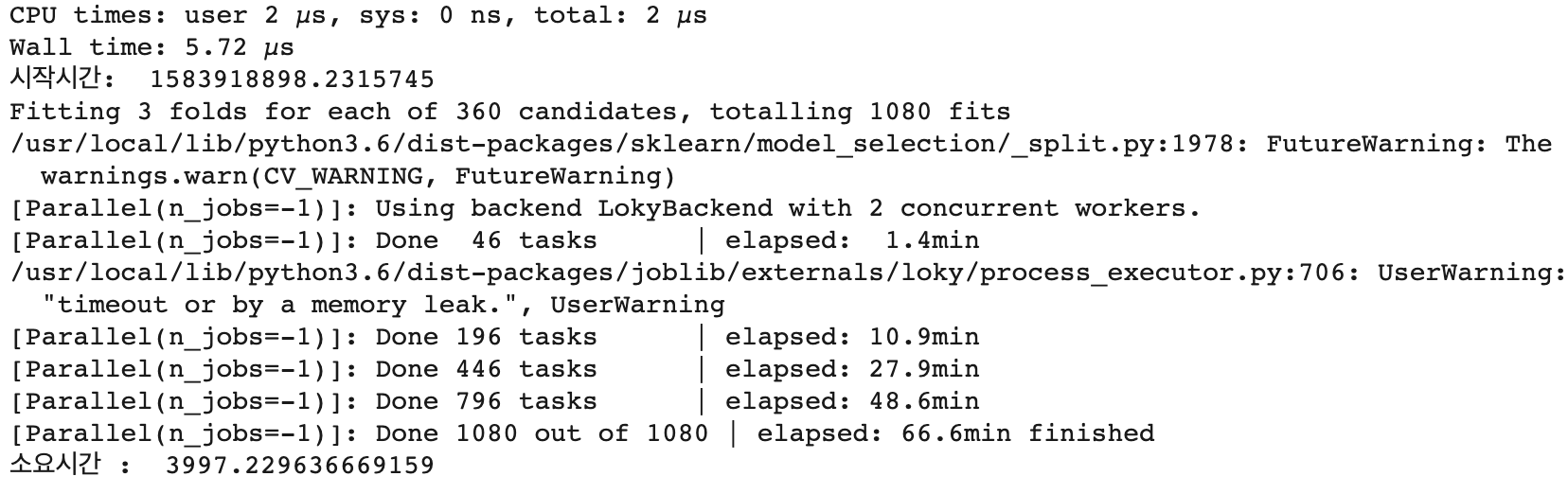
print("최고 평균 정확도 {0:4f}".format(lgb_grid6.best_score_))
print("최고의 파라미터 : ", lgb_grid6.best_params_)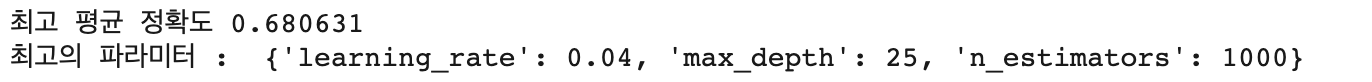
lgb_param_grid7 = {
'n_estimators' : [1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010],
'max_depth' : [21, 22, 23, 24, 25, 26, 27, 28, 29],
'learning_rate' : [0.04]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid7 = GridSearchCV(lgb, param_grid=lgb_param_grid7, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid7.fit(train_feature_tfidf, y_label)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid7.best_score_))
print("최고의 파라미터 : ", lgb_grid7.best_params_)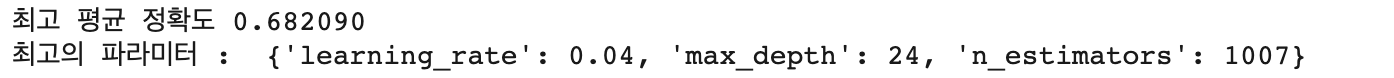
lgb_param_grid8 = {
'n_estimators' : [300, 400, 500, 600, 700, 800, 900, 1000],
'max_depth' : [10, 15, 20, 25, 30, 35]
}import time
%time
strTime = time.time()
print("시작시간: ", strTime)
lgb_grid8 = GridSearchCV(lgb, param_grid=lgb_param_grid8, scoring='accuracy', n_jobs=-1, verbose = 1)
lgb_grid8.fit(train_feature_tfidf2, y_label2)
print("소요시간 : ", time.time() - strTime)
print("최고 평균 정확도 {0:4f}".format(lgb_grid8.best_score_))
print("최고의 파라미터 : ", lgb_grid8.best_params_)
세번째 제출
lgb_best_params2 = LGBMClassifier(max_depth=24, n_estimators=1007, learning_rate=0.04) %time lgb_best_params2.fit(train_feature_tfidf, y_label)
결과

금융문자 분석처럼 결과가 좋을 줄 알았는데 너무 낮은 점수에 많이 실망하게되었습니다.
다시 전처리 방법을 바꾼 데이터를 가지고 딥러닝 모델로 바꾸어 제출해보았습니다.
from tqdm import tqdm
X_train = []
clear_text_list = list(train['clear_text'])
for i in tqdm(range(len(clear_text_list))):
temp = word_tokenize(clear_text_list[i])
temp = [stemmer.stem(word) for word in temp]
temp = [word for word in temp if word not in stop_words]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)
X_train[:3]
words = []
for i in tqdm(range(len(X_train))):
for j in range(len(X_train[i])):
words.append(X_train[i][j])
len(list(set(words)))

from keras.preprocessing.text import Tokenizer
max_words = 13173
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)import matplotlib.pyplot as plt
print("트윗의 최대 길이 :" , max(len(l) for l in X_train))
print("트윗의 평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()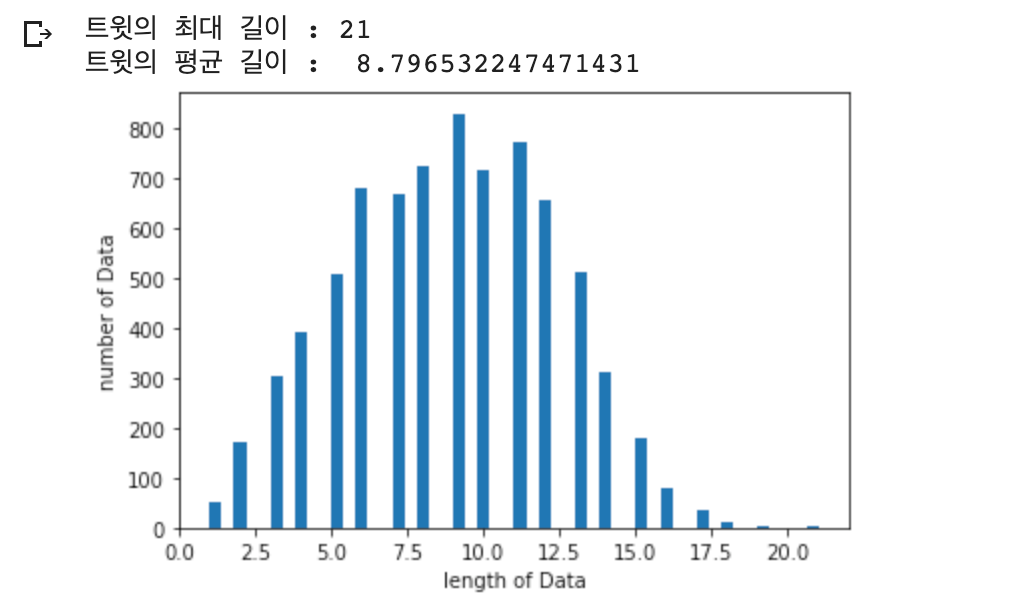
from keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(train['target'])):
if train['target'].iloc[i] == 1:
y_train.append([0, 1])
elif train['target'].iloc[i] == 0:
y_train.append([1, 0])
y_train = np.array(y_train)from keras.layers import Embedding, Flatten, Dense, SimpleRNN, LSTM, Dropout, Bidirectional, Conv1D, MaxPooling1D
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequencesmax_len = 21 # 전체 데이터의 길이를 23로 맞춘다
X_train_vec = pad_sequences(X_train_vec, maxlen=max_len)
X_test_vec = pad_sequences(X_test_vec, maxlen=max_len)
네번째 제출
model2 = Sequential()
model2.add(Embedding(max_words, 100, input_length=21)) # 임베딩 벡터의 차원은 32
model2.add(Flatten())
model2.add(Dense(32, activation='relu'))
model2.add(Dense(2, activation='sigmoid'))
model2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history2 = model2.fit(X_train_vec, y_train, epochs=1, batch_size=16, validation_split=0.1)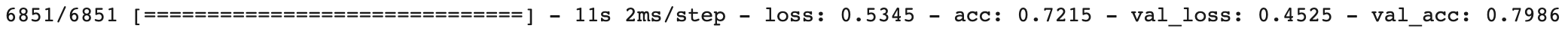
결과

파라미터 최적화에 참고한 글 / 워드 임베딩에 참고한 글
lightGBM / XGBoost 파라미터 설명 – Go Lab
lightGBM에는 무수히 많은 파라미터가 있다. 다만 기억할것은 정답이 없다는것이다. 생각보다 하이퍼파라미터 튜닝에 시간을 많이 쏟지는 않는 이유는, 어차피 ensemble형식이기 때문에 구조자체가 파라미터에 맞게 큰그림에서는 맞춰질것이라, 그다지 정확도면에서 차이가 없을수 있다. lightGBM / XGBoost 파라미터 이름순으로 정렬했다. 파라미터가 너무 많아서 어떤 파라미터를 만져야 하는지 우선순위가 있어야 해서 아래처럼 표기했다. 언급되지 않는
machinelearningkorea.com
corazzon/petitionWrangling
청와대 국민청원 데이터 분석. Contribute to corazzon/petitionWrangling development by creating an account on GitHub.
github.com
'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY16]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.13 |
|---|---|
| [Kaggle DAY15]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.12 |
| [Kaggle DAY13]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.10 |
| [Kaggle DAY12]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.09 |
| [Kaggle DAY11]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.08 |



