
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- SW Expert Academy
- programmers
- Real or Not? NLP with Disaster Tweets
- dacon
- Git
- 금융문자분석경진대회
- 프로그래머스
- 자연어처리
- hackerrank
- Docker
- 코로나19
- gs25
- ubuntu
- Baekjoon
- leetcode
- ChatGPT
- 파이썬
- AI 경진대회
- PYTHON
- 프로그래머스 파이썬
- 더현대서울 맛집
- github
- 데이콘
- 우분투
- Kaggle
- 편스토랑 우승상품
- 백준
- 캐치카페
- 편스토랑
- 맥북
- Today
- Total
솜씨좋은장씨
[Ensemble] Colab에서 LightGBM 사용하기! 본문
2021년 5월 24일 내용이 수정되었습니다.👏👏
원자력 발전소 상태판단 알고리즘을 도전해보면서 머신러닝을 공부하며
Gradient Boosing알고리즘 중의 하나인 LightGBM 알고리즘을 알게되었고
DACON KB 금융문자분석경진대회에서도 수상자들이 사용했다는 것을 알게되어 저도 이번 경진대회에서 활용해보기위해
검색하여 찾아 사용해본 내용을 정리해보았습니다.
LGBM on Colab with GPU
My experience with LGBM to enable GPU on Google Colab!
medium.com
위의 글을 참고하여 직접실행해보며 오류가 나는 부분을 수정해보았습니다.
설치 방법
1. Colab 런타임 설정 중 하드웨어 가속기를 None에서 GPU로 바꾸어줍니다.

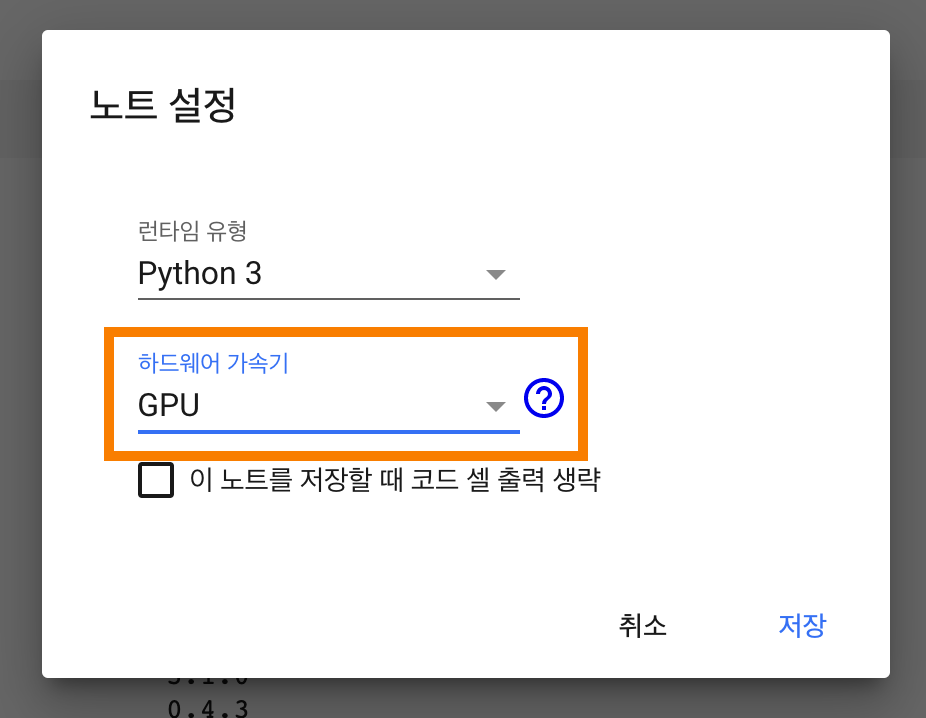
2. GitHub에 올라와 있는 소스코드를 git clone 명령어를 통하여 다운로드 받아줍니다.
!git clone --recursive https://github.com/Microsoft/LightGBM3. 다운로드 받은 소스코드 파일이있는 디렉토리로 이동합니다.
%cd /content/LightGBM4. 다음의 코드를 활용하여 설치를 진행합니다.
!mkdir build!cmake -DUSE_GPU=1!make -j$(nproc)!sudo apt-get -y install python-pip!sudo -H pip install setuptools pandas numpy scipy scikit-learn -U%cd /content/LightGBM/python-package/!sudo python setup.py install --precompile5. Colab의 scikit-learn버전은 0.22.1이나
LightGBM이 지원하는 버전은 0.21.3이므로 scikit-learn의 버전을 0.21.3 버전으로 재설치해줍니다.
( 재설치 하지 않아도 실행이 가능합니다.)
6. 다시 설치한 scikit-learn 버전을 적용하기 위해서 런타임을 재시작해줍니다.
7. 제대로 동작하는지 테스트를 수행합니다.
예제 코드 ( 붓꽃 품종 예측하기 )
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
# 붓꽃 데이터 세트를 로딩한다.
iris = load_iris()
# iris.data는 Iris 데이터 세트에서 피처(feature)만으로 된 데이터를 numpy로 가지고 있다.
iris_data = iris.data
# iris.target은 붓꽃 데이터 세트에서 레이블(결정 값) 데이터를 numpy로 가지고 있다.
iris_label = iris.target
print('iris target값:', iris_label)
print('iris target명:', iris.target_names)
# 붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환한다.
iris_df = pd.DataFrame(data = iris_data, columns = iris.feature_names)
iris_df['label'] = iris.targetX_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)# coding: utf-8
import pandas as pd
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# specify your configurations as a dict
params = {
'boosting_type': 'gbdt',
'metric': {'l2', 'l1'},
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
print('Starting training...')
# train
gbm = lgb.train(params,
lgb_train,
num_boost_round=20,
valid_sets=lgb_eval,
early_stopping_rounds=5)
print('Saving model...')
# save model to file
gbm.save_model('model.txt')
print('Starting predicting...')
# predict
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# eval
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
sklearn 기초 - 붓꽃 품종 예측하기
사이킷런(scikit-learn)은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리다. pip install scikit-learn conda install sciket-learn import sklearn print(sklearn.__version__) pip 또는 conda로..
hun931018.tistory.com
microsoft/LightGBM
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning ...
github.com
코드는 위의 두 페이지를 참고하였습니다.
실행해보면 정말 빠른시간 안에 결과가 나오는 것을 볼 수 있습니다.
읽어주셔서 감사합니다~



