
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- leetcode
- SW Expert Academy
- 편스토랑 우승상품
- Kaggle
- PYTHON
- Real or Not? NLP with Disaster Tweets
- ubuntu
- 프로그래머스
- dacon
- AI 경진대회
- Docker
- 데이콘
- 더현대서울 맛집
- 우분투
- ChatGPT
- 자연어처리
- 프로그래머스 파이썬
- 맥북
- github
- 금융문자분석경진대회
- 편스토랑
- programmers
- Git
- gs25
- 코로나19
- 백준
- 파이썬
- Baekjoon
- hackerrank
- 캐치카페
- Today
- Total
솜씨좋은장씨
[Kaggle DAY16]Real or Not? NLP with Disaster Tweets! 본문
[Kaggle DAY16]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 13. 18:43Kaggle 도전 16회차
오늘은 캐글에 공개되어있는 노트북 들 중에서 한분이 약어를 다시 풀어서 전처리한 것을 보고
저는 그 노트북에서 약어가 담겨있는 dictionary만 빼와서 전처리를 하여 도전해보았습니다.
AdaptNLP (Easier BERT-based Models)
Explore and run machine learning code with Kaggle Notebooks | Using data from Real or Not? NLP with Disaster Tweets
www.kaggle.com
먼저 필요한 라이브러리를 import해주고 약어 부분을 가져왔습니다.
import nltk
nltk.download("punkt")
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()abbreviations = {
"$" : " dollar ",
"€" : " euro ",
"4ao" : "for adults only",
"a.m" : "before midday",
"a3" : "anytime anywhere anyplace",
"aamof" : "as a matter of fact",
"acct" : "account",
"adih" : "another day in hell",
"afaic" : "as far as i am concerned",
"afaict" : "as far as i can tell",
"afaik" : "as far as i know",
"afair" : "as far as i remember",
"afk" : "away from keyboard",
"app" : "application",
"approx" : "approximately",
"apps" : "applications",
"asap" : "as soon as possible",
"asl" : "age, sex, location",
"atk" : "at the keyboard",
"ave." : "avenue",
"aymm" : "are you my mother",
"ayor" : "at your own risk",
"b&b" : "bed and breakfast",
"b+b" : "bed and breakfast",
"b.c" : "before christ",
"b2b" : "business to business",
"b2c" : "business to customer",
"b4" : "before",
"b4n" : "bye for now",
"b@u" : "back at you",
"bae" : "before anyone else",
"bak" : "back at keyboard",
"bbbg" : "bye bye be good",
"bbc" : "british broadcasting corporation",
"bbias" : "be back in a second",
"bbl" : "be back later",
"bbs" : "be back soon",
"be4" : "before",
"bfn" : "bye for now",
"blvd" : "boulevard",
"bout" : "about",
"brb" : "be right back",
"bros" : "brothers",
"brt" : "be right there",
"bsaaw" : "big smile and a wink",
"btw" : "by the way",
"bwl" : "bursting with laughter",
"c/o" : "care of",
"cet" : "central european time",
"cf" : "compare",
"cia" : "central intelligence agency",
"csl" : "can not stop laughing",
"cu" : "see you",
"cul8r" : "see you later",
"cv" : "curriculum vitae",
"cwot" : "complete waste of time",
"cya" : "see you",
"cyt" : "see you tomorrow",
"dae" : "does anyone else",
"dbmib" : "do not bother me i am busy",
"diy" : "do it yourself",
"dm" : "direct message",
"dwh" : "during work hours",
"e123" : "easy as one two three",
"eet" : "eastern european time",
"eg" : "example",
"embm" : "early morning business meeting",
"encl" : "enclosed",
"encl." : "enclosed",
"etc" : "and so on",
"faq" : "frequently asked questions",
"fawc" : "for anyone who cares",
"fb" : "facebook",
"fc" : "fingers crossed",
"fig" : "figure",
"fimh" : "forever in my heart",
"ft." : "feet",
"ft" : "featuring",
"ftl" : "for the loss",
"ftw" : "for the win",
"fwiw" : "for what it is worth",
"fyi" : "for your information",
"g9" : "genius",
"gahoy" : "get a hold of yourself",
"gal" : "get a life",
"gcse" : "general certificate of secondary education",
"gfn" : "gone for now",
"gg" : "good game",
"gl" : "good luck",
"glhf" : "good luck have fun",
"gmt" : "greenwich mean time",
"gmta" : "great minds think alike",
"gn" : "good night",
"g.o.a.t" : "greatest of all time",
"goat" : "greatest of all time",
"goi" : "get over it",
"gps" : "global positioning system",
"gr8" : "great",
"gratz" : "congratulations",
"gyal" : "girl",
"h&c" : "hot and cold",
"hp" : "horsepower",
"hr" : "hour",
"hrh" : "his royal highness",
"ht" : "height",
"ibrb" : "i will be right back",
"ic" : "i see",
"icq" : "i seek you",
"icymi" : "in case you missed it",
"idc" : "i do not care",
"idgadf" : "i do not give a damn fuck",
"idgaf" : "i do not give a fuck",
"idk" : "i do not know",
"ie" : "that is",
"i.e" : "that is",
"ifyp" : "i feel your pain",
"IG" : "instagram",
"iirc" : "if i remember correctly",
"ilu" : "i love you",
"ily" : "i love you",
"imho" : "in my humble opinion",
"imo" : "in my opinion",
"imu" : "i miss you",
"iow" : "in other words",
"irl" : "in real life",
"j4f" : "just for fun",
"jic" : "just in case",
"jk" : "just kidding",
"jsyk" : "just so you know",
"l8r" : "later",
"lb" : "pound",
"lbs" : "pounds",
"ldr" : "long distance relationship",
"lmao" : "laugh my ass off",
"lmfao" : "laugh my fucking ass off",
"lol" : "laughing out loud",
"ltd" : "limited",
"ltns" : "long time no see",
"m8" : "mate",
"mf" : "motherfucker",
"mfs" : "motherfuckers",
"mfw" : "my face when",
"mofo" : "motherfucker",
"mph" : "miles per hour",
"mr" : "mister",
"mrw" : "my reaction when",
"ms" : "miss",
"mte" : "my thoughts exactly",
"nagi" : "not a good idea",
"nbc" : "national broadcasting company",
"nbd" : "not big deal",
"nfs" : "not for sale",
"ngl" : "not going to lie",
"nhs" : "national health service",
"nrn" : "no reply necessary",
"nsfl" : "not safe for life",
"nsfw" : "not safe for work",
"nth" : "nice to have",
"nvr" : "never",
"nyc" : "new york city",
"oc" : "original content",
"og" : "original",
"ohp" : "overhead projector",
"oic" : "oh i see",
"omdb" : "over my dead body",
"omg" : "oh my god",
"omw" : "on my way",
"p.a" : "per annum",
"p.m" : "after midday",
"pm" : "prime minister",
"poc" : "people of color",
"pov" : "point of view",
"pp" : "pages",
"ppl" : "people",
"prw" : "parents are watching",
"ps" : "postscript",
"pt" : "point",
"ptb" : "please text back",
"pto" : "please turn over",
"qpsa" : "what happens", #"que pasa",
"ratchet" : "rude",
"rbtl" : "read between the lines",
"rlrt" : "real life retweet",
"rofl" : "rolling on the floor laughing",
"roflol" : "rolling on the floor laughing out loud",
"rotflmao" : "rolling on the floor laughing my ass off",
"rt" : "retweet",
"ruok" : "are you ok",
"sfw" : "safe for work",
"sk8" : "skate",
"smh" : "shake my head",
"sq" : "square",
"srsly" : "seriously",
"ssdd" : "same stuff different day",
"tbh" : "to be honest",
"tbs" : "tablespooful",
"tbsp" : "tablespooful",
"tfw" : "that feeling when",
"thks" : "thank you",
"tho" : "though",
"thx" : "thank you",
"tia" : "thanks in advance",
"til" : "today i learned",
"tl;dr" : "too long i did not read",
"tldr" : "too long i did not read",
"tmb" : "tweet me back",
"tntl" : "trying not to laugh",
"ttyl" : "talk to you later",
"u" : "you",
"u2" : "you too",
"u4e" : "yours for ever",
"utc" : "coordinated universal time",
"w/" : "with",
"w/o" : "without",
"w8" : "wait",
"wassup" : "what is up",
"wb" : "welcome back",
"wtf" : "what the fuck",
"wtg" : "way to go",
"wtpa" : "where the party at",
"wuf" : "where are you from",
"wuzup" : "what is up",
"wywh" : "wish you were here",
"yd" : "yard",
"ygtr" : "you got that right",
"ynk" : "you never know",
"zzz" : "sleeping bored and tired"
}def convert_abbrev(word):
return abbreviations[word.lower()] if word.lower() in abbreviations.keys() else worddef convert_abbrev_in_text(text):
tokens = word_tokenize(text)
tokens = [convert_abbrev(word) for word in tokens]
text = ' '.join(tokens)
return text먼저 트윗에서 http / ftp / https 주로를 LINK로 바꾸어 주었습니다.
train_text_list = list(train['text'])
remove_link_text_list = []
for i in tqdm(range(len(train_text_list))):
text_list_corpus = train_text_list[i].lower()
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl='LINK', string=text_list_corpus)
remove_link_text_list.append(clear_text)
train['remove_link_text'] = remove_link_text_list
train
test_text_list = list(test['text'])
remove_link_text_list = []
for i in tqdm(range(len(test_text_list))):
text_list_corpus = test_text_list[i].lower()
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl='LINK', string=text_list_corpus)
remove_link_text_list.append(clear_text)
test['remove_link_text'] = remove_link_text_list
test
아까 가져온 약어 리스트를 바탕으로 약어를 다시 원래의 문장으로 풀어줍니다.
from tqdm import tqdm
text_list = list(train['remove_link_text'])
transfer_text_list = []
for i in range(len(text_list)):
transfer_text = convert_abbrev_in_text(text_list[i])
transfer_text_list.append(transfer_text)
train['transfer_text'] = transfer_text_list
train
text_list = list(test['remove_link_text'])
transfer_text_list = []
for i in range(len(text_list)):
transfer_text = convert_abbrev_in_text(text_list[i])
transfer_text_list.append(transfer_text)
test['transfer_text'] = transfer_text_list
test
그 다음으로 \n과 \t를 제거해주고 숫자를 제거합니다.
그리고 알파벳이 세번 이상 반복되는 단어는 하나로 줄여줍니다.
import re
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
train_text_list = list(train['transfer_text'])
clear_text_list = []
for i in tqdm(range(len(train_text_list))):
clear_text = train_text_list[i].replace('\n', ' ').replace('\t', ' ')
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', ' ', clear_text)
clear_text = re.sub('[0-9]', ' ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
clear_text_list.append(clear_text)
train['clear_text'] = clear_text_list
train
import re
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
test_text_list = list(test['transfer_text'])
clear_text_list = []
for i in tqdm(range(len(test_text_list))):
clear_text = test_text_list[i].replace('\n', ' ').replace('\t', ' ')
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', ' ', clear_text)
clear_text = re.sub('[0-9]', ' ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
clear_text_list.append(clear_text)
test['clear_text'] = clear_text_list
test
import re
clear_text_list = list(train['clear_text'])
X_train = []
for clear_text in clear_text_list:
word_list = word_tokenize(clear_text)
word_list = [word for word in word_list if len(word) > 2]
word_list = [word for word in word_list if word not in stop_words]
word_list = [stemmer.stem(word) for word in word_list]
X_train.append(word_list)
X_train[:3]
clear_text_list = list(test['clear_text'])
X_test = []
for clear_text in clear_text_list:
word_list = word_tokenize(clear_text)
word_list = [word for word in word_list if len(word) > 2]
word_list = [word for word in word_list if word not in stop_words]
word_list = [stemmer.stem(word) for word in word_list]
X_test.append(word_list)
X_test[:3]
이를 워드클라우드로 그려보면 다음과 같습니다.
word_list = []
for i in range(len(X_train)):
for j in range(len(X_train[i])):
word_list.append(X_train[i][j])
len(list(set(word_list)))from collections import Counter
count = Counter(word_list)
common_tag_200 = count.most_common(200)from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud(background_color="white", width=3200, height=2400)
cloud = wc.generate_from_frequencies(dict(common_tag_200))
plt.figure(figsize=(20, 16))
plt.axis('off')
plt.imshow(cloud)
plt.show()
이제 이렇게 만든 데이터를가지고 학습데이터를 만들었습니다.
import numpy as np
import pandas as pd
from keras import backend as K
from keras.layers import Embedding, Dense, Input, LSTM, Bidirectional, Activation, Conv1D, GRU, TimeDistributed, Dropout
from keras.models import Model
from keras.preprocessing.text import Tokenizer, text_to_word_sequence
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import os
from tqdm import tqdm
import matplotlib.pyplot as plt# 단어들에 넘버링 하기
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)print('max length :',max(len(l) for l in X_train))
print('average length :',sum(map(len, X_train))/len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length')
plt.ylabel('number')
plt.show()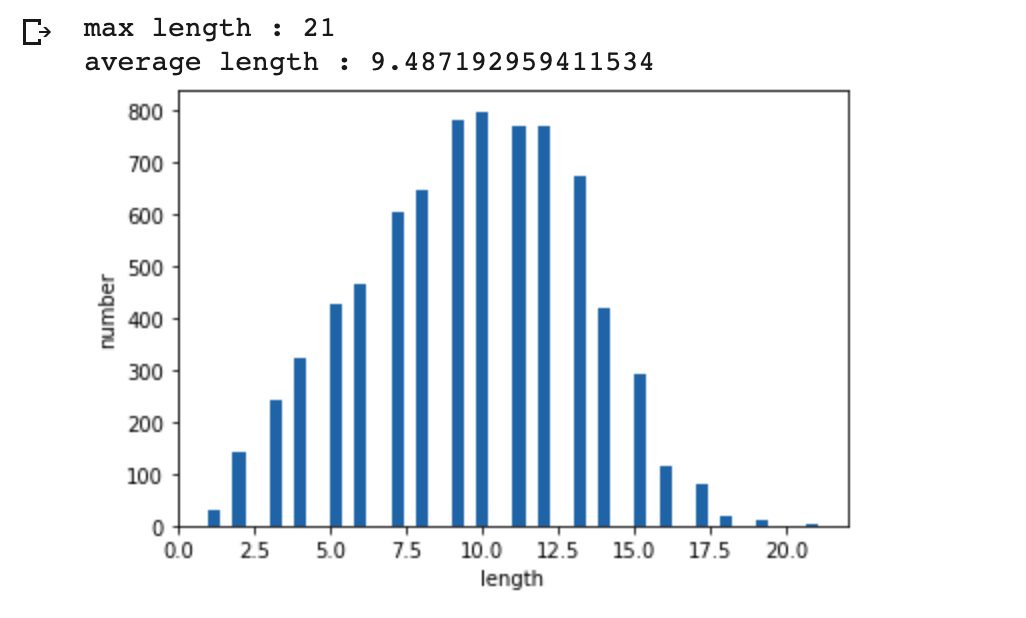
max_len = 21
x_train = pad_sequences(X_train_vec, maxlen=max_len)
x_test = pad_sequences(X_test_vec, maxlen=max_len)from keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(train['target'])):
if train['target'].iloc[i] == 1:
y_train.append([0, 1])
elif train['target'].iloc[i] == 0:
y_train.append([1, 0])
y_train = np.array(y_train)from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding, Flatten, Dropout, GRU
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categoricalvocabs = []
for i in range(len(X_train)):
for j in range(len(X_train[i])):
vocabs.append(X_train[i][j])
len(list(set(vocabs)))vocab_size = 13114저번에 만들어 두었던 가장 좋은 모델 찾기 메소드를 통해 가장 좋은 모델을 찾아줍니다.
from sklearn.datasets import load_iris # 샘플 데이터 로딩
from sklearn.model_selection import train_test_split
x_train_new, x_valid_new = train_test_split(x_train, test_size=0.1, shuffle=False, random_state=34)
y_train_new, y_valid_new = train_test_split(y_train, test_size=0.1, shuffle=False, random_state=34)from keras import optimizers
from tqdm import tqdm
def getBestParams(params_list, gru_hidden, embedding):
count = 0
histories = []
my_accs = []
my_batch = []
my_lr = []
my_epoch = []
for i in tqdm(range(len(params_list['batch_size']))):
for j in range(len(params_list['learning_rate'])):
for k in range(len(params_list['epochs'])):
batch_size = params_list['batch_size'][i]
learning_rate = params_list['learning_rate'][j]
epoch = params_list['epochs'][k]
print(str(count) + "th train")
print("batch_size : {} / lr : {} / epoch : {}".format(batch_size, learning_rate, epoch))
adam = optimizers.Adam(lr=learning_rate, decay=0.1)
accs = []
for l in range(3):
model = Sequential()
model.add(Embedding(vocab_size, embedding))
model.add(GRU(gru_hidden))
model.add(Dropout(0.5))
model.add(Dense(2, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['acc'])
history = model.fit(x_train_new, y_train_new, batch_size=batch_size, epochs=epoch, validation_split=0.1)
model_name = "./day15_model/day15" + str(count)+"th_" + str(gru_hidden) + '_' + str(embedding) +"model.h5"
model.save(model_name)
acc = model.evaluate(x_valid_new, y_valid_new)[1]*100
accs.append(acc)
my_acc = np.array(accs).mean()
print("{}th mean acc : {}%".format(i, my_acc))
my_accs.append(my_acc)
my_batch.append(batch_size)
my_lr.append(learning_rate)
my_epoch.append(epoch)
# histories.append(history)
# result_dict[count] = {"acc":my_acc, "batch_size":batch_size, "learning_rate":learning_rate, "epoch":epoch}
count = count + 1
my_result_df = pd.DataFrame({"batch_size":my_batch, "learning_rate":my_lr, "epoch":my_epoch, "accuracy":my_accs})
csv_name = "./day15_model/day15" + str(gru_hidden) + '_' + str(Embedding) + "" +"model.csv"
my_result_df.to_csv()
return my_result_dfparams_list8 = {
"batch_size":[16, 20, 24, 28, 32],
"learning_rate":[0.01, 0.03, 0.05],
"epochs":[1, 2, 3]
}my_result_df_8 = getBestParams(params_list8, 32, 100)
my_result_df_8
:

여기서 나온 결과를 accuracy 기준으로 내림차순으로 정렬해보면 다음과 같습니다.
my_result_df_8_1 = my_result_df_8.sort_values(by=['accuracy'], axis=0, ascending=False)
my_result_df_8_1
여기서 저는 상위 5개의 모델을 활용해보았습니다.
원래 목표는 저 결과를 낼때 각 파라미터마다 세번씩 학습하고 그 모델을 평가한 결과의 평균으로 저장하는데
그때마다 모델을 저장하고 나중에 저장된 모델을 활용하여 결과를 내고 평균을 내려고 했으나
중간에 코드를 실수하여 한번씩만 저장되어 새로 학습하여 결과를 내었습니다.
첫번째 제출
adam = optimizers.Adam(lr=0.05, decay=0.1)
model_1 = Sequential()
model_1.add(Embedding(vocab_size, 100))
model_1.add(GRU(32))
model_1.add(Dropout(0.5))
model_1.add(Dense(2, activation='sigmoid'))
model_1.compile(loss='binary_crossentropy', optimizer=adam, metrics=['acc'])
history = model_1.fit(x_train_new, y_train_new, batch_size=32, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

두번째 제출
adam1 = optimizers.Adam(lr=0.03, decay=0.1)
model_2 = Sequential()
model_2.add(Embedding(vocab_size, 100))
model_2.add(GRU(32))
model_2.add(Dropout(0.5))
model_2.add(Dense(2, activation='sigmoid'))
model_2.compile(loss='binary_crossentropy', optimizer=adam1, metrics=['acc'])
history = model_2.fit(x_train_new, y_train_new, batch_size=20, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

세번째 제출
adam2 = optimizers.Adam(lr=0.05, decay=0.1)
model_3 = Sequential()
model_3.add(Embedding(vocab_size, 100))
model_3.add(GRU(32))
model_3.add(Dropout(0.5))
model_3.add(Dense(2, activation='sigmoid'))
model_3.compile(loss='binary_crossentropy', optimizer=adam2, metrics=['acc'])
history = model_3.fit(x_train_new, y_train_new, batch_size=16, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

네번째 제출
adam3 = optimizers.Adam(lr=0.05, decay=0.1)
model_4 = Sequential()
model_4.add(Embedding(vocab_size, 100))
model_4.add(GRU(32))
model_4.add(Dropout(0.5))
model_4.add(Dense(2, activation='sigmoid'))
model_4.compile(loss='binary_crossentropy', optimizer=adam3, metrics=['acc'])
history = model_4.fit(x_train_new, y_train_new, batch_size=20, epochs=1, validation_data=(x_valid_new, y_valid_new))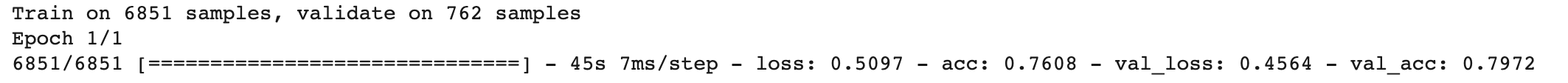
결과

다섯번째 제출
adam4 = optimizers.Adam(lr=0.05, decay=0.1)
model_5 = Sequential()
model_5.add(Embedding(vocab_size, 100))
model_5.add(GRU(32))
model_5.add(Dropout(0.5))
model_5.add(Dense(2, activation='sigmoid'))
model_5.compile(loss='binary_crossentropy', optimizer=adam4, metrics=['acc'])
history = model_5.fit(x_train_new, y_train_new, batch_size=28, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY18]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.15 |
|---|---|
| [Kaggle DAY17]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.14 |
| [Kaggle DAY15]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.12 |
| [Kaggle DAY14]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.11 |
| [Kaggle DAY13]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.10 |



