
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 코로나19
- 프로그래머스
- 금융문자분석경진대회
- ubuntu
- leetcode
- 편스토랑 우승상품
- 프로그래머스 파이썬
- 더현대서울 맛집
- 파이썬
- 자연어처리
- Docker
- gs25
- 편스토랑
- hackerrank
- Git
- ChatGPT
- 백준
- Baekjoon
- 맥북
- programmers
- 캐치카페
- PYTHON
- Kaggle
- github
- Real or Not? NLP with Disaster Tweets
- AI 경진대회
- 우분투
- 데이콘
- SW Expert Academy
- dacon
Archives
- Today
- Total
솜씨좋은장씨
[Kaggle DAY15]Real or Not? NLP with Disaster Tweets! 본문
Kaggle/Real or Not? NLP with Disaster Tweets
[Kaggle DAY15]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 12. 13:42728x90
반응형
Kaggle 15회차
오늘은 GRU모델을 활용해보기로 했습니다.
첫번째 제출
model = Sequential()
model.add(Embedding(vocab_size, 100))
model.add(GRU(100))
model.add(Dropout(0.5))
model.add(Dense(2, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(x_train, y_train, batch_size=32, epochs=3, validation_split=0.1)
결과

두번째 제출
model3 = Sequential()
model3.add(Embedding(vocab_size, 100))
model3.add(GRU(100))
model3.add(Dropout(0.5))
model3.add(Dense(2, activation='sigmoid'))
model3.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['acc'])
history3 = model3.fit(x_train, y_train, batch_size=32, epochs=3, validation_split=0.1)결과

세번째 제출
model5 = Sequential()
model5.add(Embedding(vocab_size, 100))
model5.add(GRU(64))
model5.add(Dropout(0.5))
model5.add(Dense(2, activation='sigmoid'))
model5.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
model5.summary()결과

뭔가 lightGBM의 최적의 하이퍼파라미터를 찾는 방법 중의 하나인 GridSearchCV 같은 방법이 없을까하다가
그냥 한번 만들어서 사용해보기로 했습니다.
from keras import optimizersparams_list = {
"batch_size":[8, 16, 32],
"learning_rate":[0.001, 0.005, 0.01],
"epochs":[1, 2, 3]
}from tqdm import tqdm
def getBestParams(params_list, gru_hidden, embedding):
count = 0
histories = []
my_accs = []
my_batch = []
my_lr = []
my_epoch = []
for i in tqdm(range(len(params_list['batch_size']))):
for j in range(len(params_list['learning_rate'])):
for k in range(len(params_list['epochs'])):
batch_size = params_list['batch_size'][i]
learning_rate = params_list['learning_rate'][j]
epoch = params_list['epochs'][k]
print(str(count) + "th train")
print("batch_size : {} / lr : {} / epoch : {}".format(batch_size, learning_rate, epoch))
adam = optimizers.Adam(lr=learning_rate, decay=0.1)
accs = []
for l in range(3):
model = Sequential()
model.add(Embedding(vocab_size, embedding))
model.add(GRU(gru_hidden))
model.add(Dropout(0.5))
model.add(Dense(2, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['acc'])
history = model.fit(x_train_new, y_train_new, batch_size=batch_size, epochs=epoch, validation_split=0.1)
# model_name = "./day14_model/day14" + str(count)+"th_" + str(gru_hidden) + '_' + str(Embedding) +"model.h5"
# model.save(model_name)
acc = model.evaluate(x_valid_new, y_valid_new)[1]*100
accs.append(acc)
my_acc = np.array(accs).mean()
print("{}th mean acc : {}%".format(i, my_acc))
my_accs.append(my_acc)
my_batch.append(batch_size)
my_lr.append(learning_rate)
my_epoch.append(epoch)
# histories.append(history)
# result_dict[count] = {"acc":my_acc, "batch_size":batch_size, "learning_rate":learning_rate, "epoch":epoch}
# count = count + 1
my_result_df = pd.DataFrame({"batch_size":my_batch, "learning_rate":my_lr, "epoch":my_epoch, "accuracy":my_accs})
csv_name = "./day14_model/day14" + str(gru_hidden) + '_' + str(Embedding) + "" +"model.csv"
my_result_df.to_csv()
return my_result_df파라미터를 입력해주면 모든 파라미터를 모델로 생성하여
세번씩 실행해보고 평가하여 나온 정확도를 평균내어
결과를 DataFrame형식으로 return 해주도록 하였습니다.
여기서 평가를 위한 데이터가 따로 존재하지 않으므로
from sklearn.datasets import load_iris # 샘플 데이터 로딩
from sklearn.model_selection import train_test_split
x_train_new, x_valid_new = train_test_split(x_train, test_size=0.1, shuffle=False, random_state=34)
y_train_new, y_valid_new = train_test_split(y_train, test_size=0.1, shuffle=False, random_state=34)학습데이터에서 10%의 데이터를 추출하여 만들었습니다.
실제로 해보면
params_list4 = {
"batch_size":[32],
"learning_rate":[0.005, 0.01, 0.03, 0.05],
"epochs":[1, 2, 3]
}my_result_df_4 = getBestParams(params_list4, 128, 128)
my_result_df_4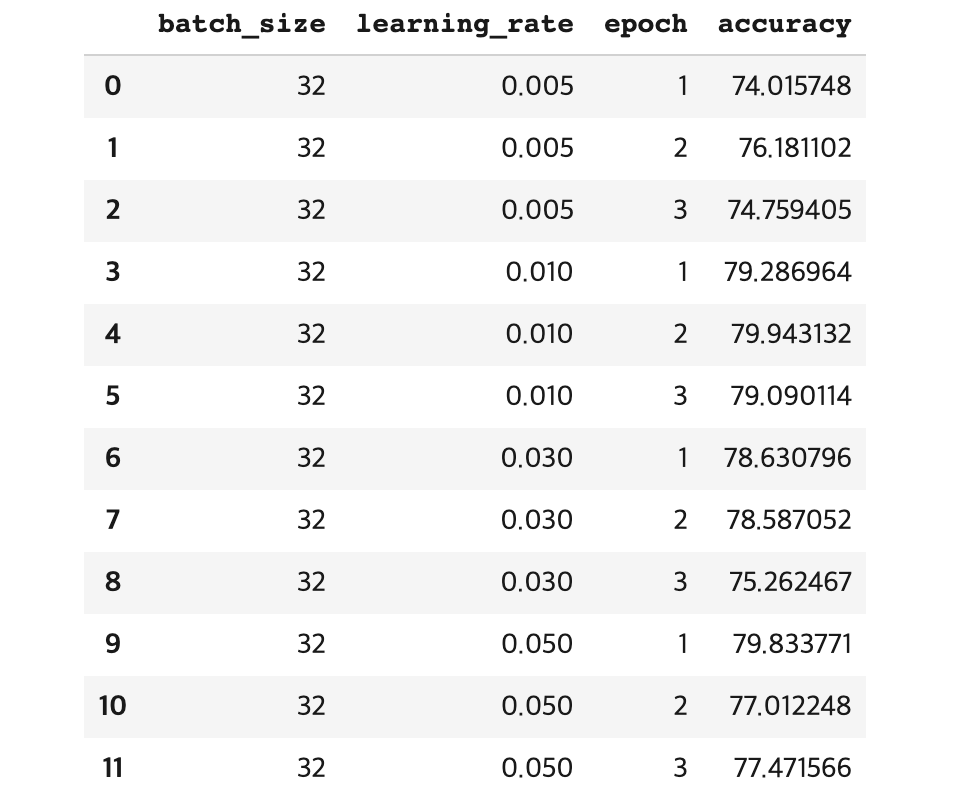
다음과 같은 결과를 얻을 수 있었습니다.
여러 파라미터를 테스트한 결과를 하나로 합치고 정렬하여
가장 좋은 결과를 낸 조합의 파라미터를 사용하여 결과를 도출하고 제출해보았습니다.
my_result_df_8 = getBestParams(params_list8, 32, 100)
my_result_df_8my_result_df_8_1 = my_result_df_8.sort_values(by=['accuracy'], axis=0, ascending=False)
my_result_df_8_1
네번째 제출
adam = optimizers.Adam(lr=0.05, decay=0.1)
model_1 = Sequential()
model_1.add(Embedding(vocab_size, 100))
model_1.add(GRU(32))
model_1.add(Dropout(0.5))
model_1.add(Dense(2, activation='sigmoid'))
model_1.compile(loss='binary_crossentropy', optimizer=adam, metrics=['acc'])
history = model_1.fit(x_train_new, y_train_new, batch_size=16, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

다섯번째 제출
adam1 = optimizers.Adam(lr=0.03, decay=0.1)
model_2 = Sequential()
model_2.add(Embedding(vocab_size, 100))
model_2.add(GRU(32))
model_2.add(Dropout(0.5))
model_2.add(Dense(2, activation='sigmoid'))
model_2.compile(loss='binary_crossentropy', optimizer=adam1, metrics=['acc'])
history = model_2.fit(x_train_new, y_train_new, batch_size=16, epochs=1, validation_data=(x_valid_new, y_valid_new))
결과

'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY17]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.14 |
|---|---|
| [Kaggle DAY16]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.13 |
| [Kaggle DAY14]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.11 |
| [Kaggle DAY13]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.10 |
| [Kaggle DAY12]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.09 |
'Kaggle/Real or Not? NLP with Disaster Tweets' Related Articles
more




Comments