
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- AI 경진대회
- 더현대서울 맛집
- ChatGPT
- Docker
- SW Expert Academy
- 코로나19
- programmers
- 편스토랑
- 프로그래머스 파이썬
- Kaggle
- dacon
- 캐치카페
- gs25
- 자연어처리
- Git
- 편스토랑 우승상품
- Real or Not? NLP with Disaster Tweets
- 데이콘
- 금융문자분석경진대회
- github
- 우분투
- 맥북
- 백준
- ubuntu
- hackerrank
- leetcode
- PYTHON
- 프로그래머스
- 파이썬
- Baekjoon
Archives
- Today
- Total
솜씨좋은장씨
[Kaggle DAY13]Real or Not? NLP with Disaster Tweets! 본문
Kaggle/Real or Not? NLP with Disaster Tweets
[Kaggle DAY13]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 10. 13:23728x90
반응형
Kaggle 13회차!
오늘은 저번 12회차까지 데이터 전처리를 했던 방법과 Glove 임베딩 기법을 사용하고
attention모델과 CNN모델을 활용하여 학습하고 결과를 도출해 제출해보았습니다.
X_train = []
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
train_text_list = list(train['text'])
clear_text_list = []
for text in train_text_list:
text_list_corpus = text.lower()
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl=' ', string=text_list_corpus)
clear_text = clear_text.replace('\n', ' ').replace('\t', ' ')
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', ' ', clear_text)
clear_text = re.sub('[0-9]', ' ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
word_list = word_tokenize(clear_text)
word_list = [word for word in word_list if len(word) > 2]
word_list = [word for word in word_list if word not in stop_words]
word_list = [stemmer.stem(word) for word in word_list]
X_train.append(word_list)
X_train# 단어들에 넘버링 하기
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)print('max length :',max(len(l) for l in X_train))
print('average length :',sum(map(len, X_train))/len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length')
plt.ylabel('number')
plt.show()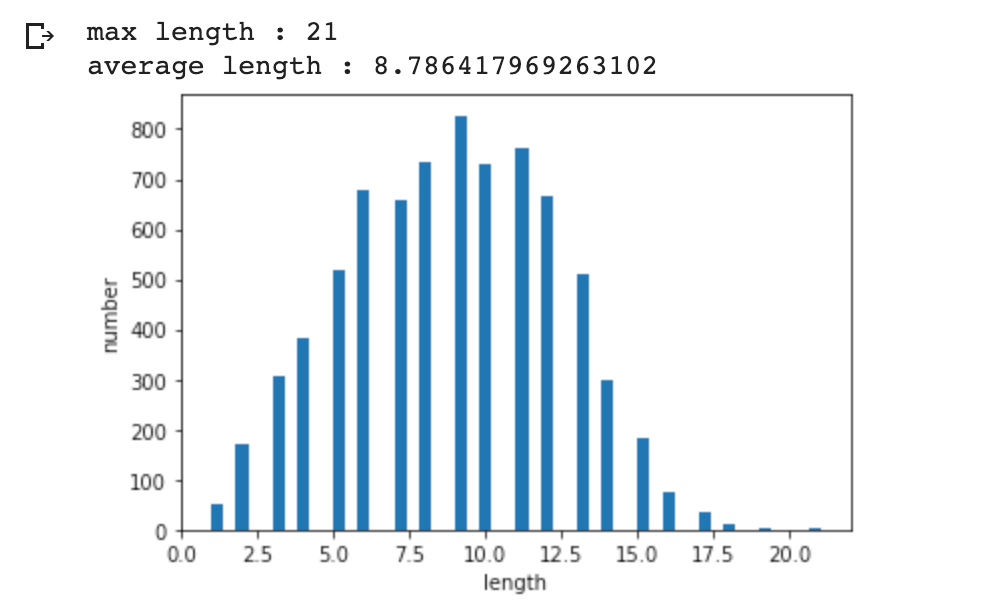
max_len = 21
x_train = pad_sequences(X_train_vec, maxlen=max_len)
x_test = pad_sequences(X_test_vec, maxlen=max_len)from keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(train['target'])):
if train['target'].iloc[i] == 1:
y_train.append([0, 1])
elif train['target'].iloc[i] == 0:
y_train.append([1, 0])
y_train = np.array(y_train)import gensim
import os, requests, shutil
glove_dir = './glove'
glove_100k_50d = 'glove.first-100k.6B.50d.txt'
glove_100k_50d_path = os.path.join(glove_dir, glove_100k_50d)
# These are temporary files if we need to download it from the original source (slow)
data_cache = './data/cache'
glove_full_tar = 'glove.6B.zip'
glove_full_50d = 'glove.6B.50d.txt'
#force_download_from_original=False
download_url= 'http://redcatlabs.com/downloads/deep-learning-workshop/notebooks/data/RNN/'+glove_100k_50d
original_url = 'http://nlp.stanford.edu/data/'+glove_full_tar
if not os.path.isfile( glove_100k_50d_path ):
if not os.path.exists(glove_dir):
os.makedirs(glove_dir)
# First, try to download a pre-prepared file directly...
response = requests.get(download_url, stream=True)
if response.status_code == requests.codes.ok:
print("Downloading 42Mb pre-prepared GloVE file from RedCatLabs")
with open(glove_100k_50d_path, 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
else:
# But, for some reason, RedCatLabs didn't give us the file directly
if not os.path.exists(data_cache):
os.makedirs(data_cache)
if not os.path.isfile( os.path.join(data_cache, glove_full_50d) ):
zipfilepath = os.path.join(data_cache, glove_full_tar)
if not os.path.isfile( zipfilepath ):
print("Downloading 860Mb GloVE file from Stanford")
response = requests.get(download_url, stream=True)
with open(zipfilepath, 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
if os.path.isfile(zipfilepath):
print("Unpacking 50d GloVE file from zip")
import zipfile
zipfile.ZipFile(zipfilepath, 'r').extract(glove_full_50d, data_cache)
with open(os.path.join(data_cache, glove_full_50d), 'rt') as in_file:
with open(glove_100k_50d_path, 'wt') as out_file:
print("Reducing 50d GloVE file to first 100k words")
for i, l in enumerate(in_file.readlines()):
if i>=100000: break
out_file.write(l)
# Get rid of tarfile source (the required text file itself will remain)
#os.unlink(zipfilepath)
#os.unlink(os.path.join(data_cache, glove_full_50d))
print("GloVE available locally")
def loadGloveModel(gloveFile):
print("Loading Glove Model")
f = open(gloveFile,'r')
model = {}
for line in f:
splitLine = line.split()
word = splitLine[0]
embedding = np.array([float(val) for val in splitLine[1:]])
model[word] = embedding
print("Done.",len(model)," words loaded!")
return modelword_embedding = loadGloveModel(glove_100k_50d_path)vocab_size = len(tokenizer.word_index) + 1
embedding_matrix = np.zeros((vocab_size, 50))
np.shape(embedding_matrix)def get_vector(word):
if word in word_embedding:
return word_embedding[word]
else:
return None
for word, i in tokenizer.word_index.items():
temp = get_vector(word)
if temp is not None:
embedding_matrix[i] = temp!pip install keras-self-attention
첫번째 제출
from keras_self_attention import SeqWeightedAttention
e = Embedding(vocab_size, 50, weights=[embedding_matrix], input_length=max_len, trainable=False)
inputs = Input(shape=(max_len,), dtype='int32')
embedding= e(inputs)
x = Bidirectional(LSTM(64, return_sequences=True))(embedding)
merged = SeqWeightedAttention()(x) #attention layer 추가
merged = Dense(80, activation='relu')(merged)
merged = Dropout(0.25)(merged)
outputs = Dense(2, activation='sigmoid')(merged)
attention_model4 = Model(inputs=inputs, outputs=outputs)
attention_model4.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])

결과

두번째 제출
attention_model5 = Model(inputs=inputs, outputs=outputs)
attention_model5.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
history5 = attention_model5.fit(x_train, y_train, batch_size = 32, validation_split=0.1, shuffle=True, epochs=2)
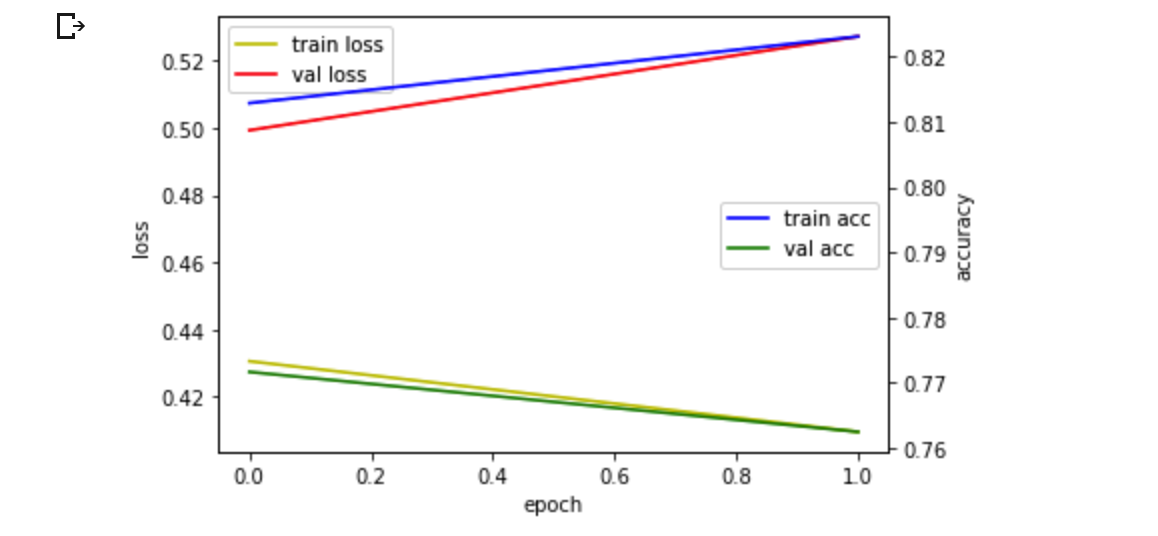
결과

세번째 제출
attention_model8 = Model(inputs=inputs, outputs=outputs)
attention_model8.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
history8 = attention_model8.fit(x_train, y_train, batch_size = 32, validation_split=0.1, shuffle=True, epochs=5)
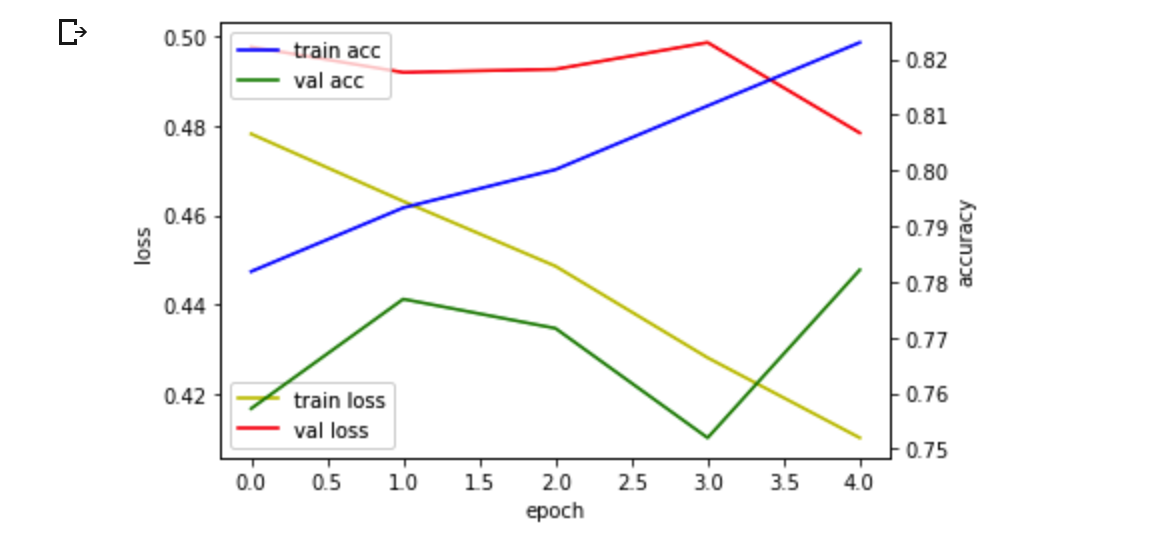
결과

생각보다 학습시에도 accuracy가 올라가지 않고 결과도 좋지않았습니다.
그래서 기존에 제출했던 모델중에 가장 결과가 좋았던 모델에 정제한 데이터를 가지고 학습하고 결과를 도출해보았습니다.
from keras.preprocessing.text import Tokenizer
max_words = 13144
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec2 = tokenizer.texts_to_sequences(X_train)
X_test_vec2 = tokenizer.texts_to_sequences(X_test)max_len2 = 21
X_train_vec2 = pad_sequences(X_train_vec2, maxlen=max_len2)
X_test_vec2 = pad_sequences(X_test_vec2, maxlen=max_len2)네번째 제출
model2 = Sequential()
model2.add(Embedding(max_words, 128, input_length=21))
model2.add(Dropout(0.2))
model2.add(Conv1D(256,
3,
padding='valid',
activation='relu',
strides=1))
model2.add(GlobalMaxPooling1D())
model2.add(Dense(32, activation='relu'))
model2.add(Dropout(0.2))
model2.add(Dense(2, activation='sigmoid'))
model2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history9 = model2.fit(X_train_vec2, y_train, epochs=2, batch_size=32, validation_split=0.1)
결과

다섯번째 제출
model3 = Sequential()
model3.add(Embedding(max_words, 128, input_length=21))
model3.add(Dropout(0.2))
model3.add(Conv1D(256,
3,
padding='valid',
activation='relu',
strides=1))
model3.add(GlobalMaxPooling1D())
model3.add(Dense(32, activation='relu'))
model3.add(Dropout(0.2))
model3.add(Dense(2, activation='sigmoid'))
model3.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history10 = model3.fit(X_train_vec2, y_train, epochs=1, batch_size=32, validation_split=0.1)
결과

'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY15]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.12 |
|---|---|
| [Kaggle DAY14]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.11 |
| [Kaggle DAY12]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.09 |
| [Kaggle DAY11]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.08 |
| [Kaggle DAY10]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.07 |
'Kaggle/Real or Not? NLP with Disaster Tweets' Related Articles
more




Comments