
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 프로그래머스
- 편스토랑 우승상품
- SW Expert Academy
- Git
- hackerrank
- 캐치카페
- Kaggle
- 백준
- 파이썬
- 편스토랑
- programmers
- Docker
- 더현대서울 맛집
- 금융문자분석경진대회
- gs25
- leetcode
- 우분투
- ChatGPT
- github
- 자연어처리
- 데이콘
- 맥북
- PYTHON
- 프로그래머스 파이썬
- ubuntu
- Real or Not? NLP with Disaster Tweets
- Baekjoon
- AI 경진대회
- dacon
- 코로나19
- Today
- Total
솜씨좋은장씨
[Kaggle DAY11]Real or Not? NLP with Disaster Tweets! 본문
[Kaggle DAY11]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 8. 17:53Kaggle 도전 11일차!
오늘은 어제 데이터 전처리했던 방식에서 조금 더 추가하여 전처리를 진행하고 학습 시킨 후 결과를 도출하여 제출해보았습니다.
먼저 추가로 어떤 데이터를 어떻게 전처리할지 보기위해서 워드클라우드도 그려보고
단어의 빈도수도 확인해보았습니다.
먼저 저번주에 워드클라우드를 그렸던 방법에서
길이가 3이상인 단어와 nltk의 불용어에 없는 단어만 남겨놓고 그려보았습니다.
(이 글을 쓰면서 정말 큰 실수했다고 생각되는 부분은 stemmer.stem(word)하기 전에 불용어 처리를 했어야했는데 이미 stemming이 완료된 이후에 불용어 처리를 하다보니 the가 thi로 바뀌는 등 제대로 불용어 처리가 되지 않았던 것 같습니다.)
word_list = word_tokenize(clear_text)
word_list = [stemmer.stem(word) for word in word_list]
word_list = [word for word in word_list if len(word) > 2]
word_list = [word for word in word_list if word not in stop_words]
len(list(set(word_list)))
워드클라우드에서 link 가 엄청나게 크게 보이는 것을 볼 수 있었습니다.
이에 저번 10회차에서 https / http / ftp 주소를 LINK로 바꾼 것이 의미가 있을까 궁금하여
진짜 트윗과 가짜 트윗에 각각 얼마나 LINK가 존재하는지 확인해보았습니다.
real_tweet = train[train['target'] == 1]
fake_tweet = train[train['target'] == 0]
len(real_tweet['text']), len(fake_tweet['text'])
먼저 학습데이터에서 target 값을 통해서 진짜 트윗과 가짜 트윗을 분리해줍니다.
분리 후 각각의 데이터가 몇개씩 존재하는지 확인해보면 진짜 트윗은 3,271개, 가짜 트윗은 4,342개가 존재하는 것을 알 수 있습니다.
new_real_index = []
for i in range(3271):
new_real_index.append(i)
real_tweet.index = new_real_index
real_tweet_text = list(real_tweet['text'])
indexs_real = []
for i in range(len(real_tweet['text'])):
if real_tweet['clear_text'].iloc[i].find('LINK') != -1:
indexs_real.append(i)
real_tweet_with_link = real_tweet.loc[indexs_real]
real_tweet_with_linknew_fake_index = []
for i in range(4342):
new_fake_index.append(i)
fake_tweet.index = new_fake_index
fake_tweet_text = list(fake_tweet['text'])
indexs_fake = []
for i in range(len(fake_tweet['text'])):
if fake_tweet['clear_text'].iloc[i].find('link') != -1:
indexs_fake.append(i)
fake_tweet_with_link = fake_tweet.loc[indexs_fake]
fake_tweet_with_link여기서 각각의 트윗에 link가 존재하는 row만 추출하여 길이를 비교해보았습니다.
len(real_tweet_with_link), len(fake_tweet_with_link)
존재하는 비율이 크게 다르지 않아 link는 전처리시 지우기로 했습니다.
이번에는 num도 확인해보았습니다.
동일한 방법으로 확인해보니

이 또한 크게 크게 다르지않아 전처리시 지웠습니다.
이렇게 전처리 방법을 바꾸어 진짜 트윗과 가짜 트윗만 뽑아서 워드클라우드를 그려보니 다음과 같았습니다.
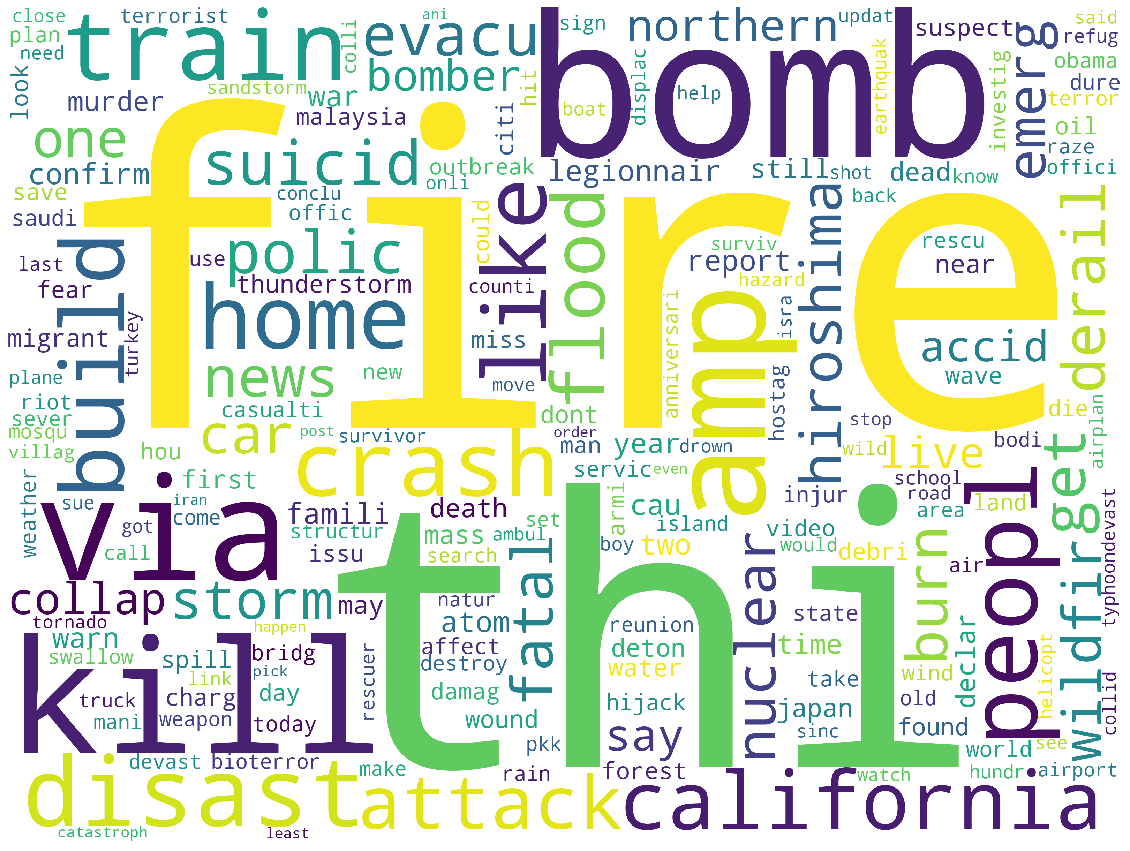
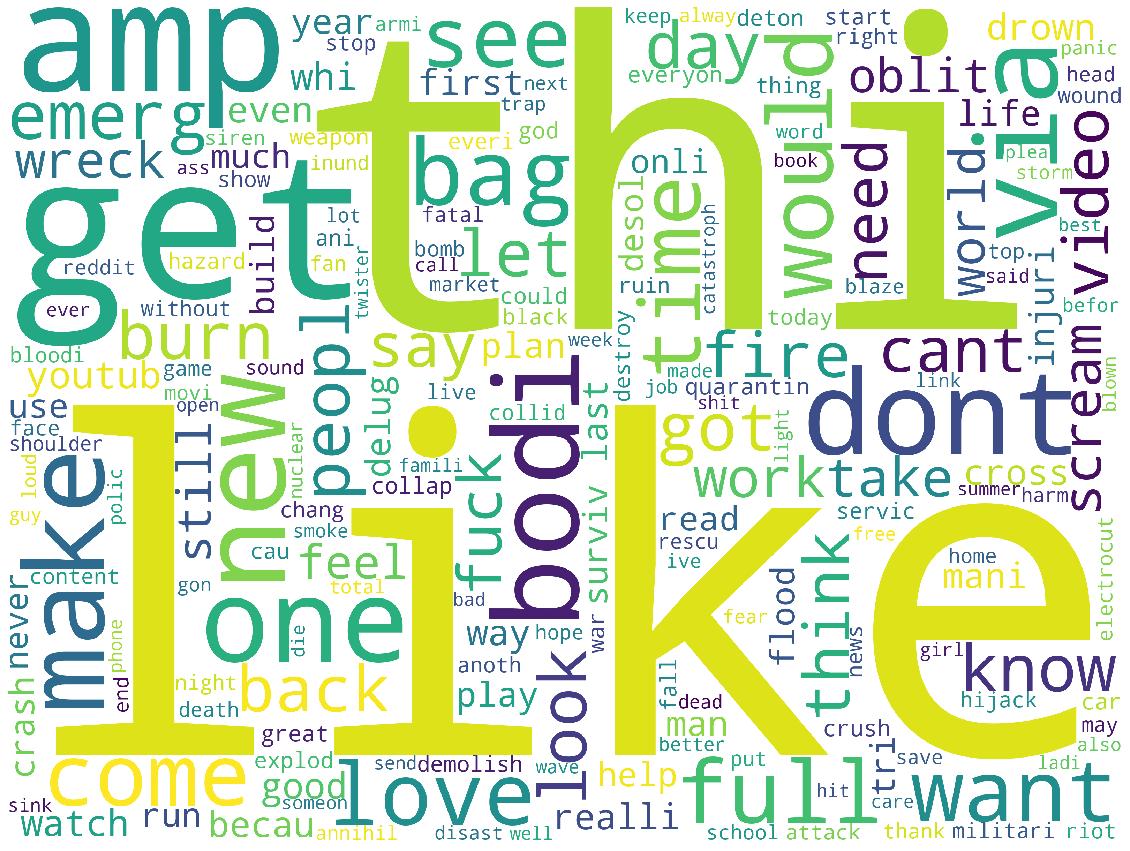
이렇게 만든 데이터를 가지고 모델은 그대로 활용해서 도전 해봤습니다.
첫번째 제출
sess = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess.run(init)
bert_model = get_bert_finetuning_model(model)
history = bert_model.fit(train_x, train_y_new, epochs=2, batch_size=16, verbose = 1, validation_split=0.05, shuffle=True)
결과

두번째 제출
bert_model2 = get_bert_finetuning_model(model)
history2 = bert_model2.fit(train_x, train_y_new, epochs=2, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

세번째 제출
bert_model3 = get_bert_finetuning_model(model)
history2 = bert_model3.fit(train_x, train_y_new, epochs=3, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

네번째 제출
bert_model4 = get_bert_finetuning_model(model)
history2 = bert_model4.fit(train_x, train_y_new, epochs=5, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

다섯번째 제출
bert_model5 = get_bert_finetuning_model(model)
history2 = bert_model5.fit(train_x, train_y_new, epochs=5, batch_size=16, verbose = 1, validation_split=0.05, shuffle=True)
결과

글을 쓰면서 생각난 것들
- 특수문자 제거할 때 무조건 제거하지말고 공백으로 처리하면 좋을 것 같다.
(이유) 가끔 세가지 단어가 연결되어 의미없는 단어로 토큰화 되는 경우가 많이 존재
앞으로 해보고 싶은 것
- N-gram / LIME / TF-IDF / lightGBM
'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY13]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.10 |
|---|---|
| [Kaggle DAY12]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.09 |
| [Kaggle DAY10]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.07 |
| [Kaggle DAY09]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.07 |
| [Kaggle DAY08]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.05 |



