
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- Docker
- 데이콘
- 코로나19
- ChatGPT
- 프로그래머스
- ubuntu
- gs25
- Kaggle
- SW Expert Academy
- 편스토랑 우승상품
- hackerrank
- 더현대서울 맛집
- 자연어처리
- 편스토랑
- dacon
- programmers
- 캐치카페
- Git
- PYTHON
- 우분투
- AI 경진대회
- Baekjoon
- 프로그래머스 파이썬
- 맥북
- leetcode
- 파이썬
- 백준
- github
- 금융문자분석경진대회
- Real or Not? NLP with Disaster Tweets
Archives
- Today
- Total
솜씨좋은장씨
[Kaggle DAY10]Real or Not? NLP with Disaster Tweets! 본문
Kaggle/Real or Not? NLP with Disaster Tweets
[Kaggle DAY10]Real or Not? NLP with Disaster Tweets!
솜씨좋은장씨 2020. 3. 7. 16:23728x90
반응형
Kaggle 도전 10회차!
데이터를 가공하여 학습하고 결과를 도출해보았습니다.
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
train_text_list = list(train['text'])
text_list_corpus = ''
for text in train_text_list:
text_list_corpus = text_list_corpus + text
text_list_corpus = text_list_corpus.lower()
text_list_corpus
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl='LINK', string=text_list_corpus)
clear_text = clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', '', clear_text)
clear_text = clear_text = re.sub('[0-9]', 'num ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
clear_text먼저 모든 단어를 소문자로 바꾸어주고
데이터에서 알파벳이 세번 이상 반복되는 곳은 해당 알파벳을 하나만 남겨두는것으로
https http ftp 링크는 LINK로
특수문자는 제거
부처, 알라, 예수의 단어는 god로 통일
숫자는 num으로 바꾸었습니다.
워드클라우드를 그려보기위해 필요한 라이브러리를 import 해주었습니다.
import nltk
nltk.download("stopwords")
nltk.download("punkt")
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer() word_list = word_tokenize(clear_text)
word_list = [stemmer.stem(word) for word in word_list]
word_list = [word for word in word_list if word not in stop_words]
len(list(set(word_list)))
from collections import Counter
count = Counter(word_list)
common_tag_200 = count.most_common(16208)from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud(background_color="white", width=3200, height=2400)
cloud = wc.generate_from_frequencies(dict(common_tag_200))
plt.figure(figsize=(20, 16))
plt.axis('off')
plt.imshow(cloud)
plt.show()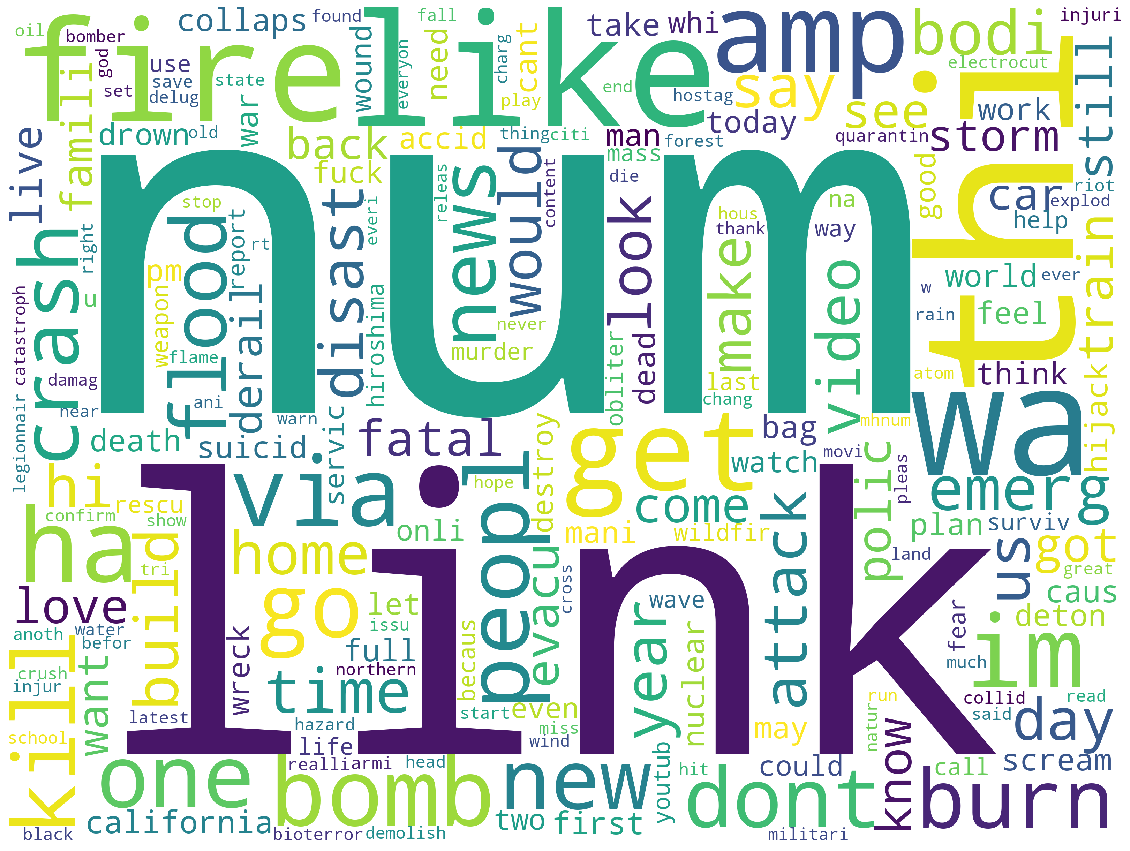
이 데이터를 가지고 결과를 내보았습니다.
alphabets = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
god_list = ['buddha', 'allah', 'jesus']
train_text_list = list(train['text'])
clear_text_list = []
for text in train_text_list:
text_list_corpus = text.lower()
pattern = '(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+/(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
clear_text = re.sub(pattern=pattern, repl='LINK', string=text_list_corpus)
clear_text = clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》;]', '', clear_text)
clear_text = clear_text = re.sub('[0-9]', 'num ', clear_text)
for i in range(len(alphabets)):
clear_text = re.sub(alphabets[i]+'{3,}', alphabets[i], clear_text)
for i in range(len(god_list)):
clear_text = clear_text.replace(god_list[i], 'god')
clear_text_list.append(clear_text)
train['clear_text'] = clear_text_list
trainMake WordCloud With Pre-Processing
Explore and run machine learning code with Kaggle Notebooks | Using data from Real or Not? NLP with Disaster Tweets
www.kaggle.com
첫번째 제출
sess = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess.run(init)
bert_model = get_bert_finetuning_model(model)
history = bert_model.fit(train_x, train_y_new, epochs=2, batch_size=16, verbose = 1, validation_split=0.05, shuffle=True)
결과

두번째 제출
sess2 = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess2.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess2.run(init)
bert_model2 = get_bert_finetuning_model(model)
history2 = bert_model2.fit(train_x, train_y_new, epochs=2, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

세번째 제출
sess = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess.run(init)
bert_model3 = get_bert_finetuning_model(model)
history2 = bert_model3.fit(train_x, train_y_new, epochs=3, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

네번째 제출
sess2 = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess2.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess2.run(init)
bert_model4 = get_bert_finetuning_model(model)
history2 = bert_model4.fit(train_x, train_y_new, epochs=5, batch_size=32, verbose = 1, validation_split=0.05, shuffle=True)
결과

다섯번째 제출
sess2 = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess2.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess2.run(init)
bert_model5 = get_bert_finetuning_model(model)
history2 = bert_model5.fit(train_x, train_y_new, epochs=5, batch_size=16, verbose = 1, validation_split=0.05, shuffle=True)
결과

'Kaggle > Real or Not? NLP with Disaster Tweets' 카테고리의 다른 글
| [Kaggle DAY12]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.09 |
|---|---|
| [Kaggle DAY11]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.08 |
| [Kaggle DAY09]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.07 |
| [Kaggle DAY08]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.05 |
| [Kaggle DAY07]Real or Not? NLP with Disaster Tweets! (0) | 2020.03.04 |
'Kaggle/Real or Not? NLP with Disaster Tweets' Related Articles
more




Comments