
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 백준
- gs25
- 캐치카페
- 금융문자분석경진대회
- PYTHON
- Docker
- dacon
- 편스토랑 우승상품
- Kaggle
- 파이썬
- 더현대서울 맛집
- leetcode
- ubuntu
- 맥북
- 코로나19
- github
- 프로그래머스
- 프로그래머스 파이썬
- AI 경진대회
- 자연어처리
- ChatGPT
- Baekjoon
- SW Expert Academy
- 우분투
- Git
- Real or Not? NLP with Disaster Tweets
- programmers
- 편스토랑
- 데이콘
- hackerrank
- Today
- Total
솜씨좋은장씨
DACON AI프렌즈 시즌1 온도 추정 경진대회 데이터 이해하고 분석해보기 (feat. DACON YOUTUBE) 본문
DACON AI프렌즈 시즌1 온도 추정 경진대회 데이터 이해하고 분석해보기 (feat. DACON YOUTUBE)
솜씨좋은장씨 2020. 3. 9. 21:18
3월 ! 이번 달은
지난 금융문자분석경진대회와 원자력 발전소 상태판단 알고리즘 경진대회에 이어
DACON과 AI프렌즈가 함께 개최한 AI프렌즈 시즌 1 온도 추정 경진대회에 참가해보려합니다.
이 대회는 시즌 3까지 나올 예정이라고 하여 앞으로 어떤 대회가 계속 개최될지 궁금해 더 기대가 되는 대회입니다.
[공공] AI프렌즈 시즌1 온도 추정 경진대회
출처 : DACON - Data Science Competition
dacon.io
오늘은 첫날로 데이터에 대해서 이해하고 분석해보고자 합니다.
위의 유튜브 내용을 보면서 이해한 내용과 그 후 분석해본 내용에 대해서 적어보았습니다.
대회 목적
- 기상청 데이터로 특정 지역 또는 지형지물의 온도를 추정하는 모델 생성
- 모델 생성을 위해 기상청에서 관측한 기상 데이터와 특정 지역 또는 지형지물의 온도를 측정한 센서데이터 제공
데이터 설명
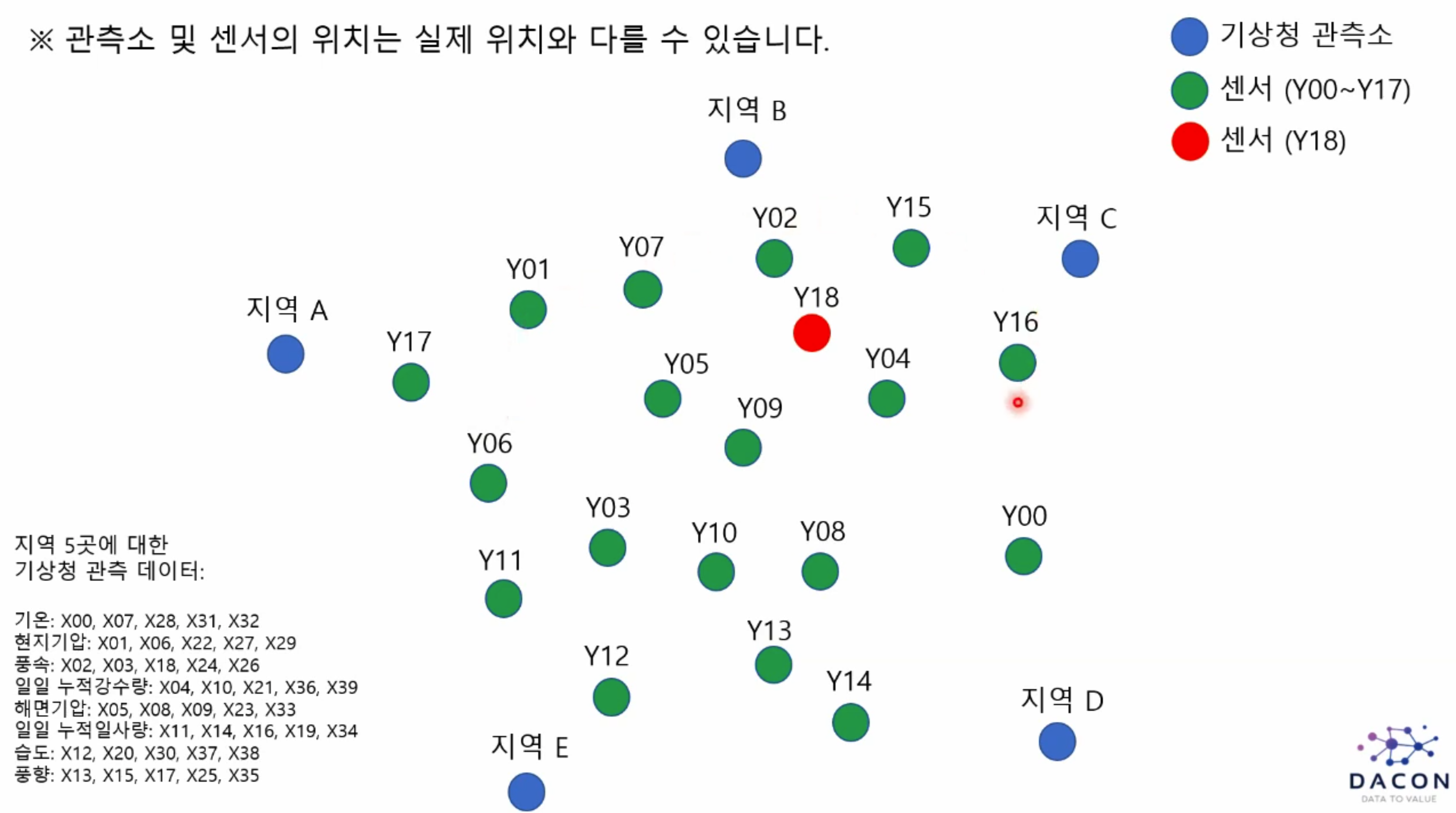
이 대회에서 제공되는 데이터는 5개의 지역에서 제공되는 데이터라고 합니다.
5개의 지역에서 총 8가지의 기상 속성정보를 제공하므로 총 40개의 X변수가 제공되었습니다.
X 변수는 다음과 같습니다.
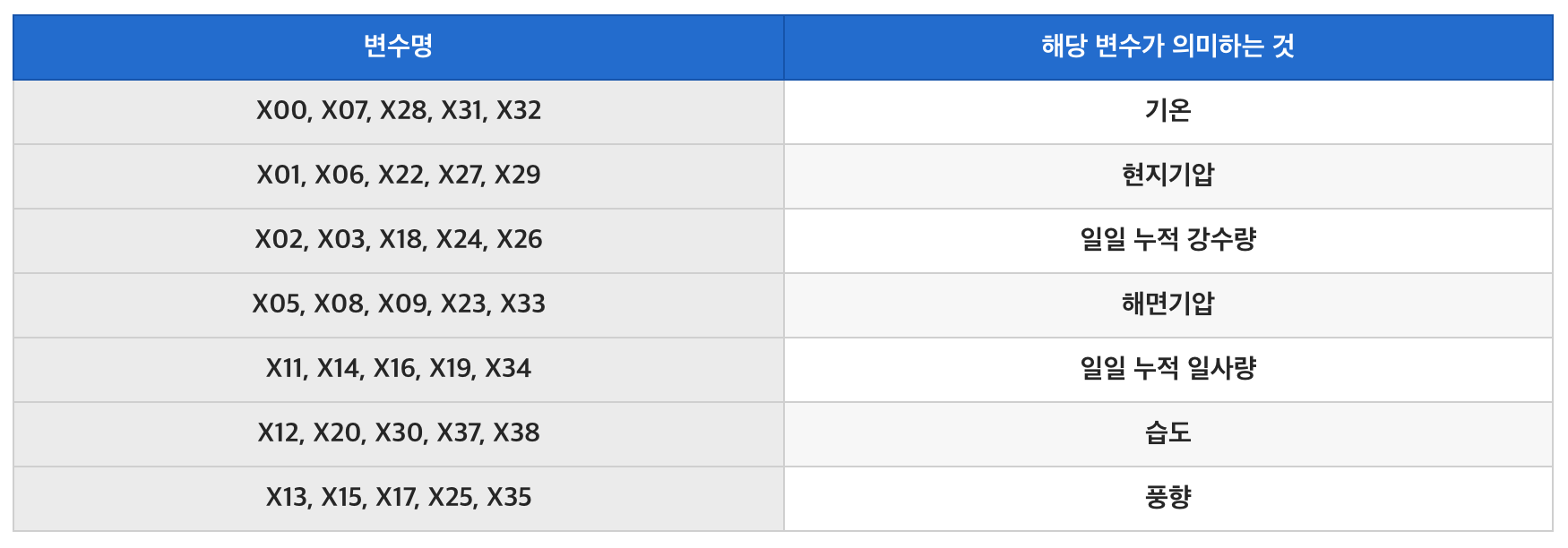
각각의 변수는 어떠한 속성인지는 제공되지만
각각의 속성이 속한 지역은 비식별화여 제공되었습니다.
대회에서 제공되는 Y 데이터는 총 19개의 위치에서 측정된 온도데이터입니다.
이 대회에서는 주변 5개의 지역에서 관측된 기상청 관측 데이터와 제공된 Y00~Y18데이터를 활용하여
Y18 위치의 온도를 추정하는 대회입니다.
데이터를 조금 더 자세하게 살펴보면 다음과 같습니다.
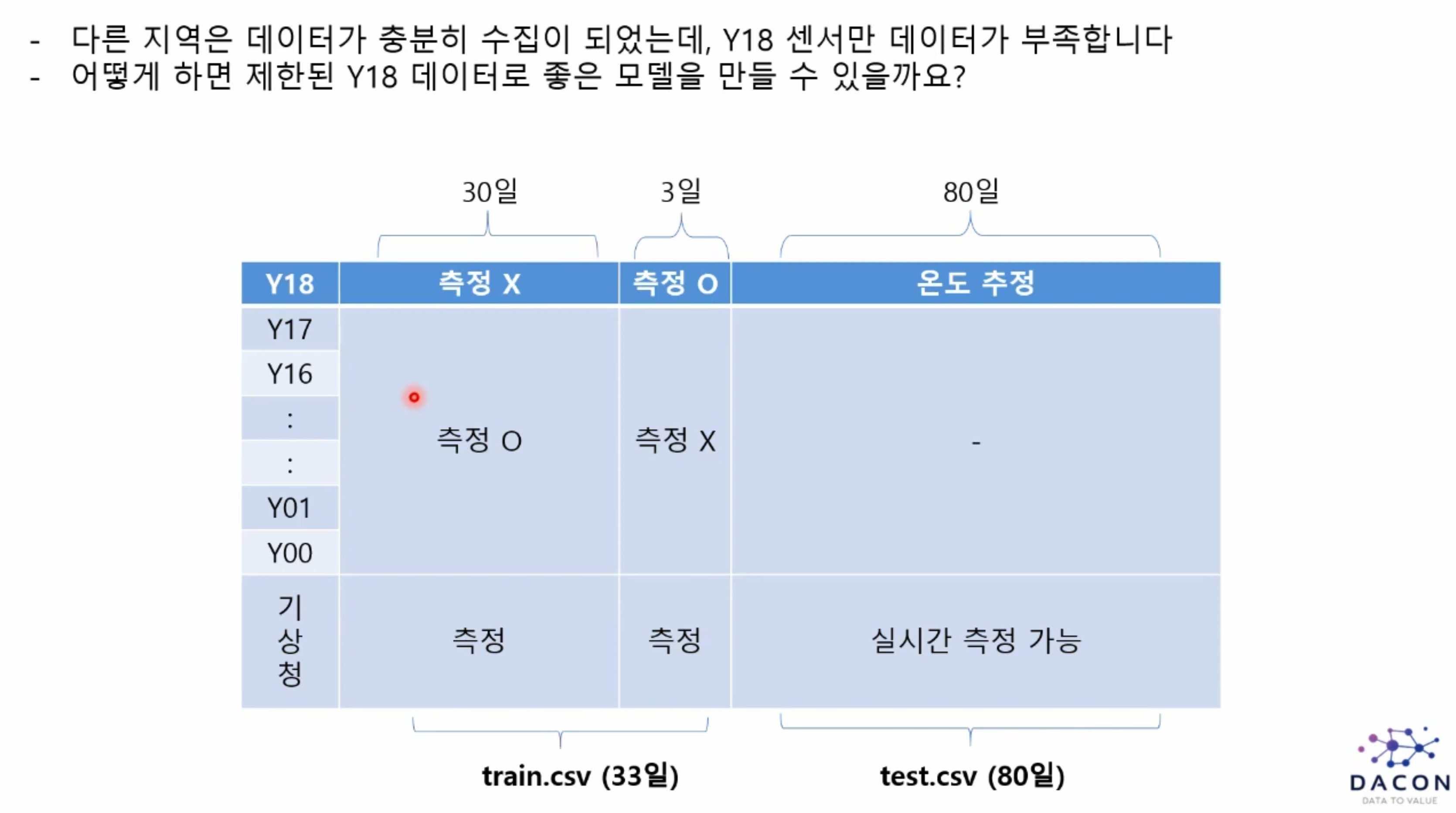
학습데이터는 33일의 데이터가 주어지고 이 데이터를 통해서 그 후 80일의 온도를 예측해야합니다.
그런데 우리가 필요한 Y18 의 데이터가 30일 가량 측정이 되어있지 않는 것을 볼 수 있습니다.
우리는 여기서 Y18의 3일치의 데이터와 기상청 측정 데이터를 가지고 80일의 온도를 추정해야하므로
참고를 할 수 있도록 Y18의 데이터가 없는 30일 동안의 Y00~Y17의 데이터도 제공해주었습니다.
이제 데이터를 다운로드 받아서 실제로 한번확인해보겠습니다.
데이터 다운로드
[공공] AI프렌즈 시즌1 온도 추정 경진대회
출처 : DACON - Data Science Competition
dacon.io
저는 데이터를 다운로드 받은 후에 Google Colab 환경에서 진행하기 위해서 Google Drive에 업로드 하였습니다.
데이터 분석 해보기
실행 환경 : Google Colab - 가속기 사용 안함
먼저 Colab에서 구글 드라이브를 마운트 해주었습니다.
마운트 방법은 다음 페이지를 참조하기 바랍니다.
Google Colab에서 Google Drive와 연동하기
먼저 새로운 노트북을 하나 만들어주고 셀에 아래의 코드를 입력해줍니다. import os, sys from google.colab import drive drive.mount('/content/mnt') nb_path = '/content/notebooks' os.symlink('/content/mn..
somjang.tistory.com
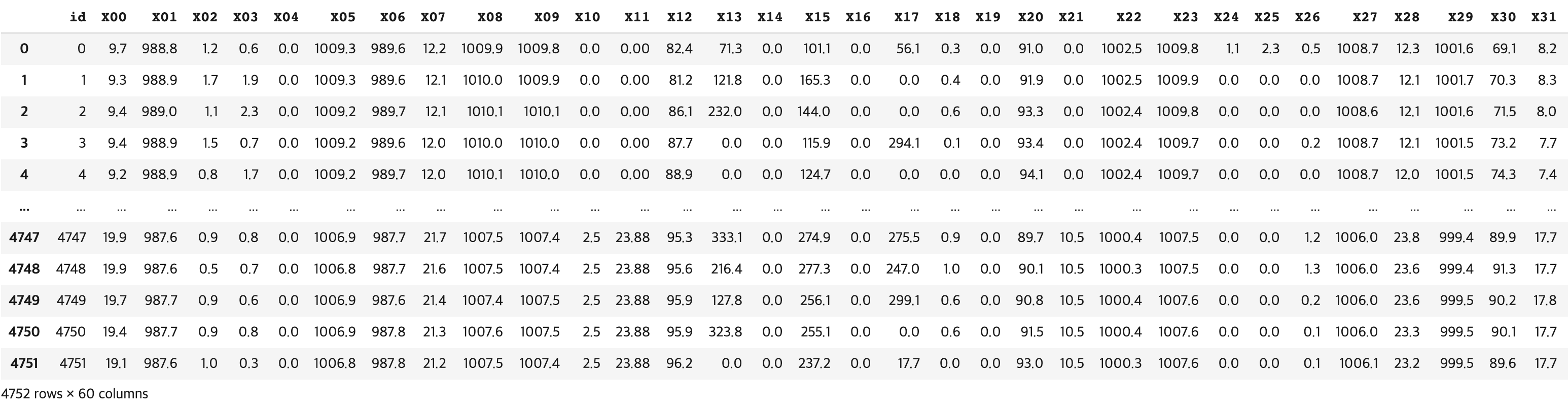
import pandas as pd
train = pd.read_csv("./data/train.csv")
test = pd.read_csv("./data/test.csv")마운트 한 이후 pandas의 read_csv 메소드를 활용하여 데이터를 DataFrame형식으로 받아옵니다.
히트맵 그려보기
각각의 변수들의 상관관계가 어떠한지 보기위해서 히트맵을 그려보기 위해서 몇가지 전처리를 실시했습니다.
먼저 X00 ~ X39까지의 변수와 Y00 ~ Y17까지의 변수의 상관관계를 보려고 합니다.
위의 데이터 설명을 보면 Y00 ~ Y17까지의 데이터에는 약 3일간의 결측치가 존재하는 것을 볼 수 있습니다.
train_for_heatmap = train.iloc[: , 1:-1]
train_for_heatmap = train_for_heatmap.dropna()
train_for_heatmap이를 해결하기 위해서
먼저 아까 csv에서 load해 만든 train 이라는 DataFrame 변수에서 iloc 메소드를 통하여 X00 ~ Y17까지의 열만 추출합니다.
그 후 dropna( ) 를 활용하여 3일치의 결측치가 존재하는 열을 제외한 나머지의 데이터만 남깁니다.
이를바탕으로 히트맵을 그리면 다음과 같습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = [60, 30]
correlations = train_for_heatmap.corr()
# plt.figure(figsize = (14, 12))
# Heatmap of correlations
sns.heatmap(correlations, cmap = plt.cm.RdYlBu_r, vmin = 0.2, annot = True, vmax = 0.9)
plt.title('Correlation Heatmap');X00 ~ X39 변수와 Y00 ~ Y17의 상관관계를 나타내는 히트맵
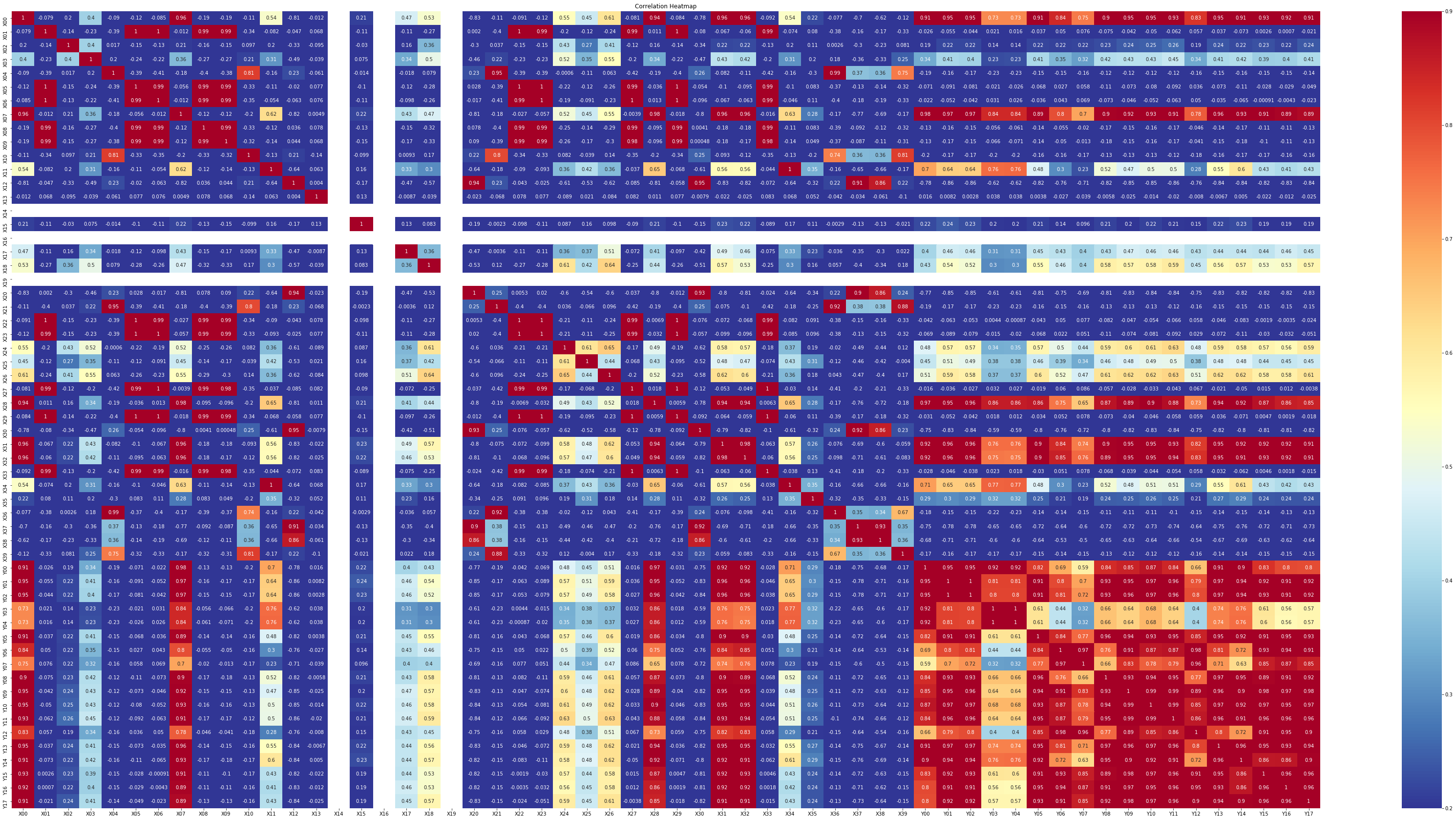
히트맵을 보면 X00, X07, X28, X31, X32와 상관관계가 높은 것을 볼 수 있었습니다.
해당 변수가 무엇인지 확인해보니 5개의 측정소에서 측정한 기온이었습니다.
데이터가 지형지물의 온도를 나타내다보니 확실히 기온의 영향을 많이 받는 것 같습니다.
또 X03, X11, X17, X18, X24, X25, X26, X34, X35 데이터도 기온만큼은 아니지만 약간의 상관관계가 있는 것을 볼 수 있었습니다.
각각의 데이터가 어떤 것을 의미하는지는 다음과 같습니다.

이번에는 X00 ~ X39 데이터와 Y18의 상관관계에 대해서도 알아보려합니다.
Y18데이터는 조금 전 보았던 Y00 ~ Y17의 데이터와 다르게 앞쪽 30일의 데이터가 결측치로 존재합니다.
train_for_heatmap2 = train.iloc[4320: , 1:41]
train_for_heatmap2 = train_for_heatmap2.dropna()
train_for_heatmap3 = train.iloc[:, -1:]
train_for_heatmap3 = train_for_heatmap3.dropna()
train_for_heatmap_Y18 = pd.concat([train_for_heatmap2, train_for_heatmap3], axis=1)먼저 train에서 iloc 메소드를 활용하여 X00 ~ X39의 열의 데이터만 추출하였습니다.
그리고 동일한 방법으로 Y18 열의 데이터만 추출합니다.
두개의 데이터를 하나로 합치기 위해서 pandas의 concat메소드를 활용하여 하나로 합쳐줍니다.
X00 ~ X39 변수와 Y18의 상관관계를 나타내는 히트맵
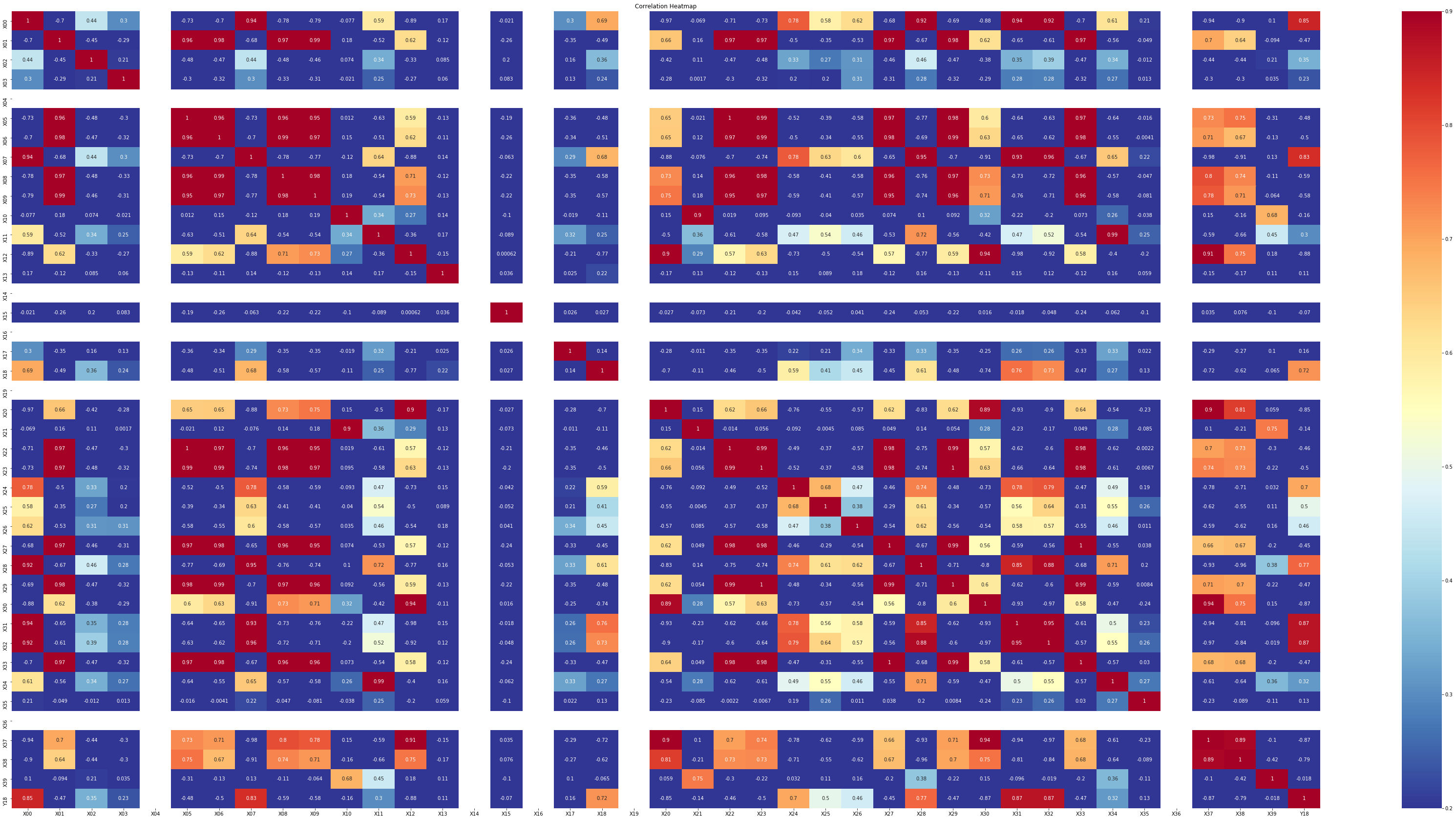
Y00 ~ Y17의 데이터와 같은 결과를 얻을 수 있었습니다.
그리고 X04, X14, X16, X19, X36의 데이터는 히트맵에서 하얀색으로 되어있어 확인해보니
X14, X16, X19는 모두 0으로 채워져있어 나중에 제외하고 사용하면 좋을 것 같습니다.
오늘은 DACON에서 제공해준 데이터 이해 동영상을 보고 정리하고 직접 히트맵을 그려 분석해보았습니다.
이를 바탕으로 남은 기간동안 온도 예측 모델을 만들어 도전해보려고 합니다.
읽어주셔서 감사합니다!
지금 바로 대회 참가해보기 ↓
[공공] AI프렌즈 시즌1 온도 추정 경진대회
출처 : DACON - Data Science Competition
dacon.io
'DACON > AI프렌즈 시즌1 온도 추정 경진대회' 카테고리의 다른 글
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 4회차 (0) | 2020.03.17 |
|---|---|
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 3회차 (0) | 2020.03.14 |
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 2회차 (0) | 2020.03.13 |
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 1회차 (0) | 2020.03.12 |
| 3월 공모전 데이콘 X AI프렌즈 온도추정 경진대회 도전! (0) | 2020.03.12 |



