
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- gs25
- 편스토랑
- 편스토랑 우승상품
- SW Expert Academy
- 데이콘
- programmers
- Real or Not? NLP with Disaster Tweets
- github
- 프로그래머스
- 파이썬
- Docker
- 더현대서울 맛집
- ChatGPT
- Kaggle
- 백준
- ubuntu
- Git
- leetcode
- 우분투
- AI 경진대회
- hackerrank
- 캐치카페
- Baekjoon
- 자연어처리
- 맥북
- 코로나19
- PYTHON
- 프로그래머스 파이썬
- dacon
- 금융문자분석경진대회
- Today
- Total
솜씨좋은장씨
데이콘 X AI 프렌즈 온도추정 경진대회 도전 4회차 본문

데이콘 온도추정 경진대회 도전 4회차입니다.
[공공] AI프렌즈 시즌1 온도 추정 경진대회
출처 : DACON - Data Science Competition
dacon.io
오늘은 그동안 계속 해보고 싶었던 방법을 도전해보았습니다.
30일 동안의 Y00 ~ Y17까지의 센서 데이터를 가지고 Y18 센서의 데이터만 존재하는 3일동안의 Y00 ~ Y17 센서 데이터를 예측한 후
가장 비슷한 센서데이터를 선택하여 그 데이터를 바탕으로 앞쪽에 30일 가량 비어있는 Y18데이터를 채워넣어
학습하고 결과를 도출해보았습니다.
먼저 ligthGBM의 LGBMRegressor를 활용하여 3일간의 Y00 ~ Y17센서 데이터를 예측해보았습니다.
최적의 파라미터를 구하는데에는 GridSearchCV를 활용하였습니다.
lgb_for_best = LGBMRegressor()
lgb_param_grid = {
'n_estimators' : [10, 20 ,30, 40, 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
'max_depth' : [5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 70, 80, 90, 100],
'learning_rate' : [0.001, 0.005, 0.007, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1]
}
best_lgb_param = get_best_params(lgb_for_best, lgb_param_grid)lgb_with_best_params = LGBMRegressor(learning_rate=0.01, max_depth=5, n_estimators=600)
lgb_with_best_params.fit(X_train, Y_train)GridSearchCV를 통해서 얻은 파라미터 값을 가지고 LGBMRegressor를 학습시켰습니다.
for_predict_x_train = train.loc[4320:, ['X00', 'X07', 'X11','X28', 'X31', 'X32', 'X34']]
for_predict_x_train그 후 Y00 ~ Y17 센서데이터가 없는기간의 기온과 일일 누적일사량 데이터를 가져옵니다.
predict = lgb_with_best_params.predict(for_predict_x_train)
predict_labels = predict아까 학습한 모델을 가지고 예측을 하고
train_new = train
train_new.loc[4320:, ['Y00']] = predict_labels예측한 값을 DataFrame에 비어있는 공간에 집어 넣어봅니다.
이 모델이 정확하게 예측을 한 것인지 눈으로 확인해보기위해서 이미 데이터가 존재하는 앞쪽의 30일 데이터도 이 모델을 통해서
예측해보고 그 예측한 값과 기존 데이터랑 같이 matplotlib으로 시각화하여 확인해보았습니다.
for_predict_x_train2 = train.loc[0:4320, ['X00', 'X07', 'X11','X28', 'X31', 'X32', 'X34']]
for_predict_x_train2
predict2 = lgb_with_best_params.predict(for_predict_x_train2)
predict_labels2 = predict2
train_new2 = train
train_new2.loc[0:4320, ['Y00']] = predict_labels2앞쪽 30일의 기온과 일일 누적 일사량 데이터만 가져와서 예측하고 그 값을 대입해보았습니다.
plt.figure(figsize=(20, 10))
plt.plot(train_new_Y00)
plt.plot(train_predict_Y00)주황색이 예측한 값
파란색이 기존의 데이터 입니다.
생각보다 정말 잘 예측이 된 것을 볼 수있습니다.
이방법으로 Y00 ~ Y17까지 예측해보았습니다.
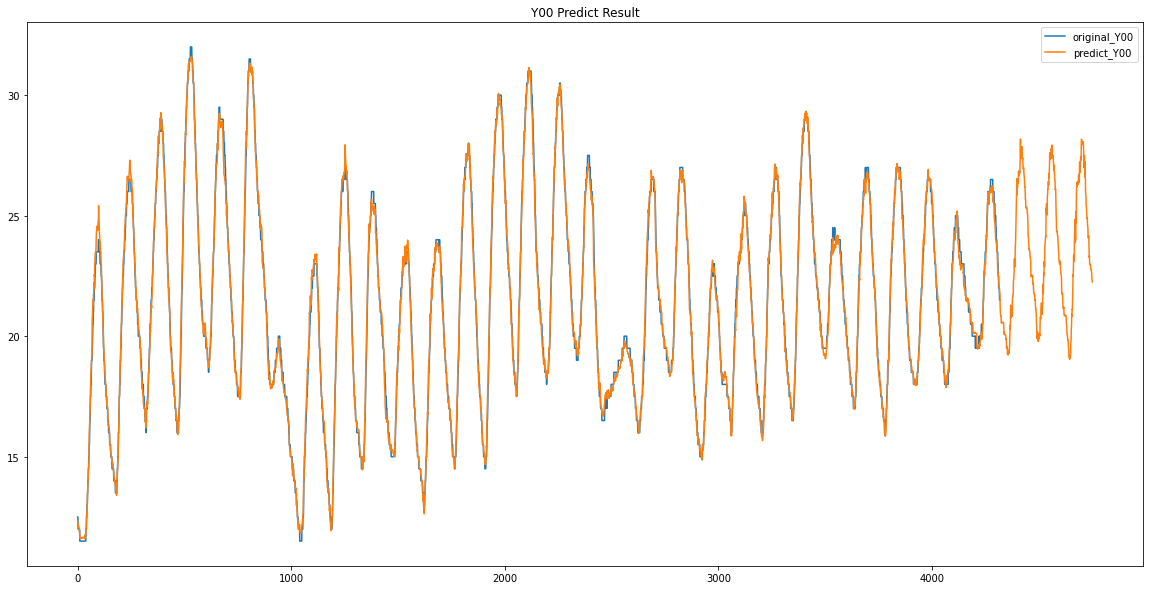
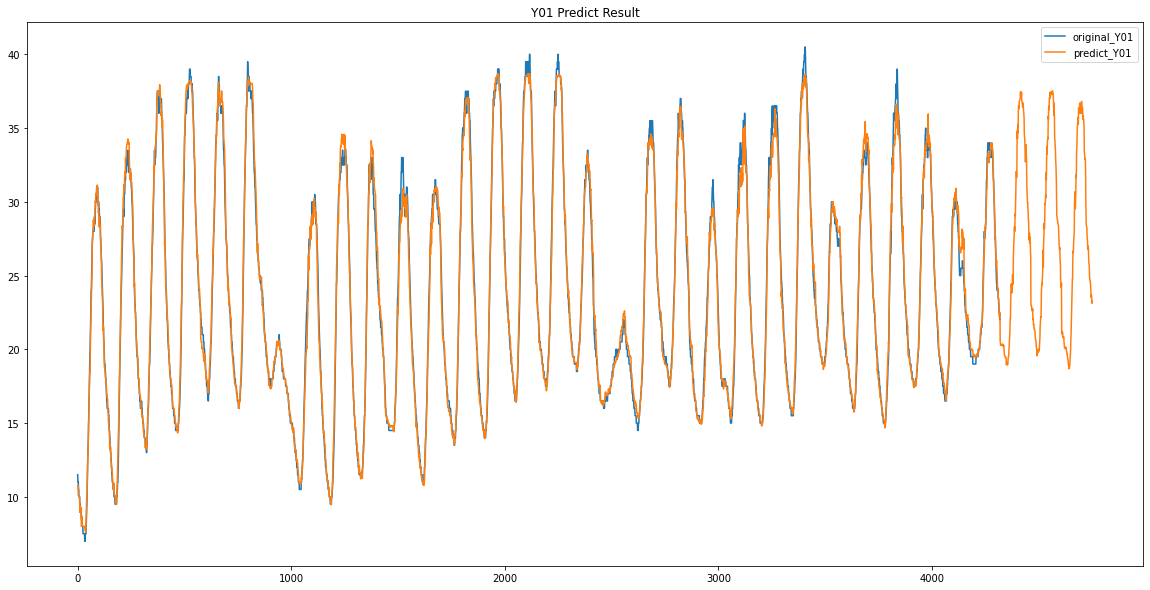
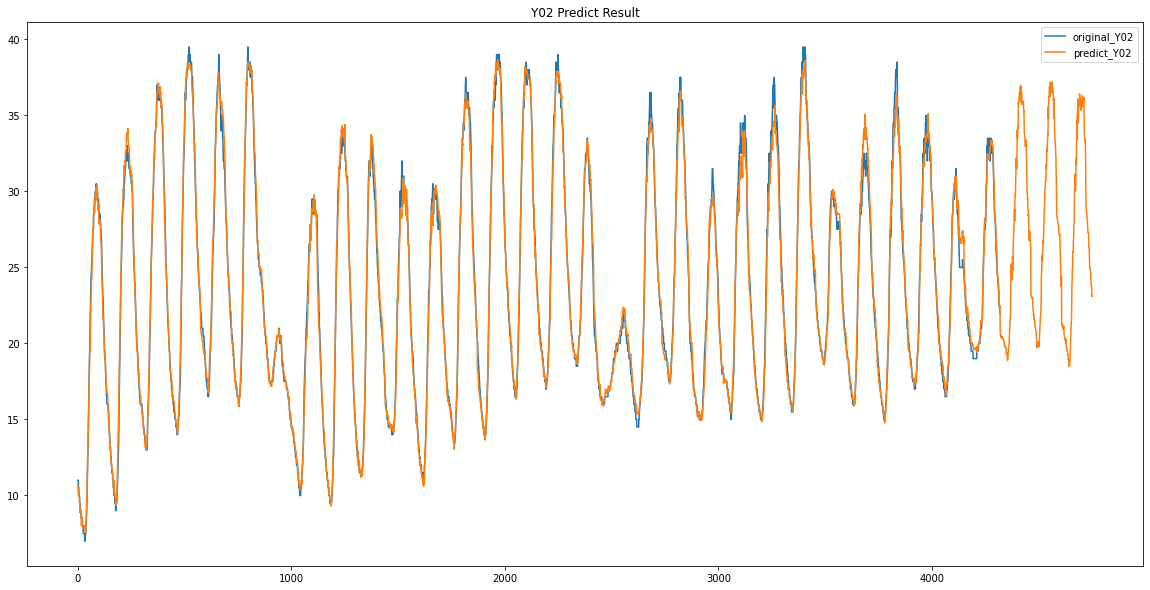
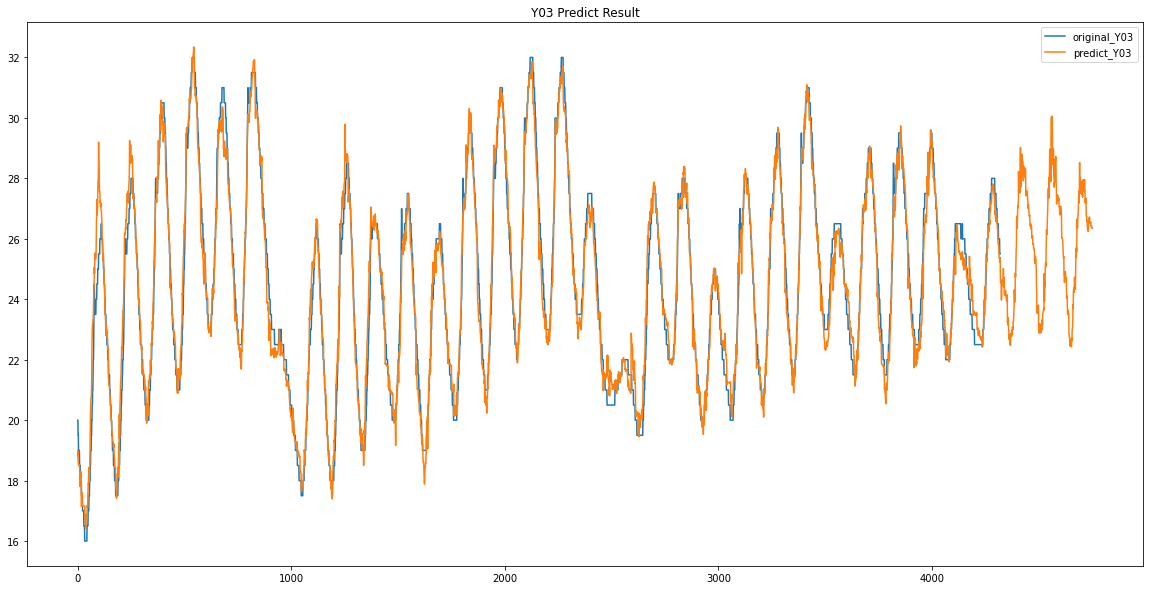
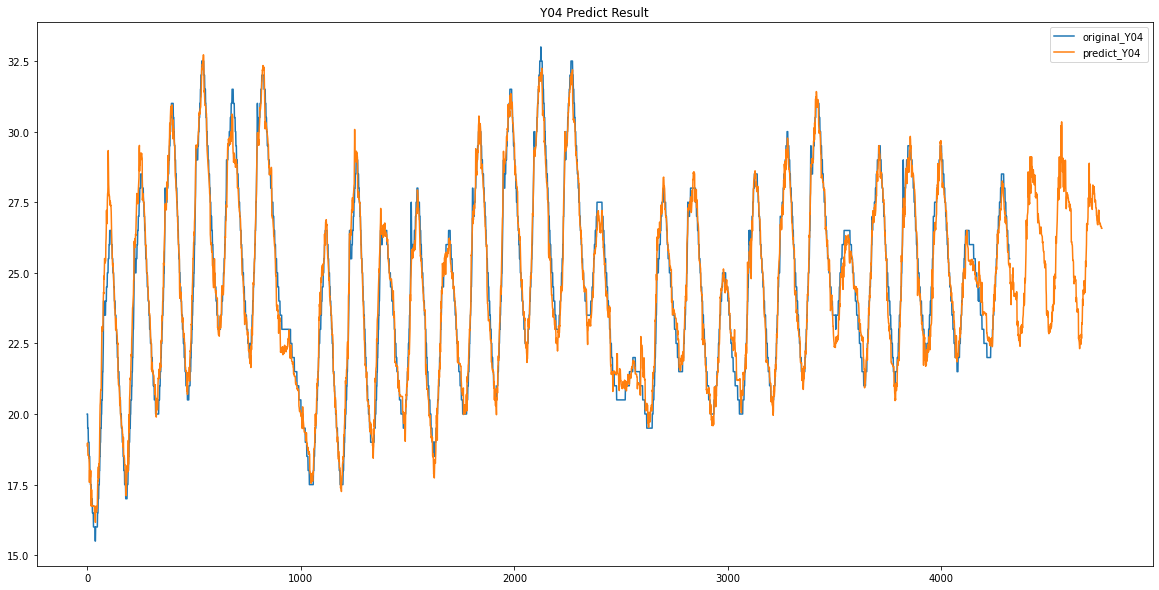
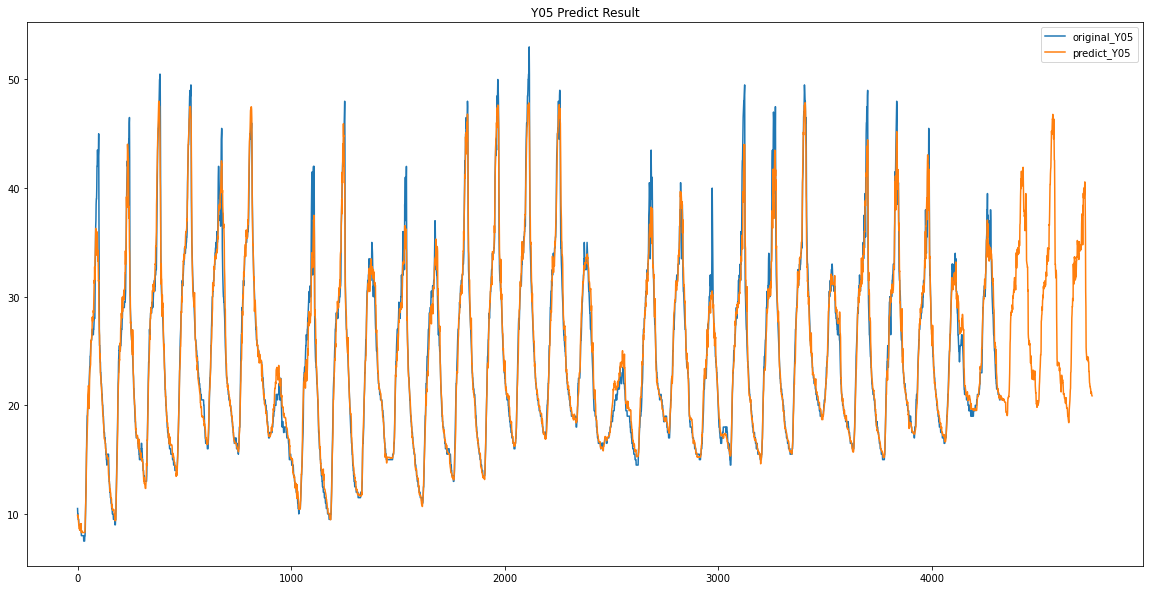
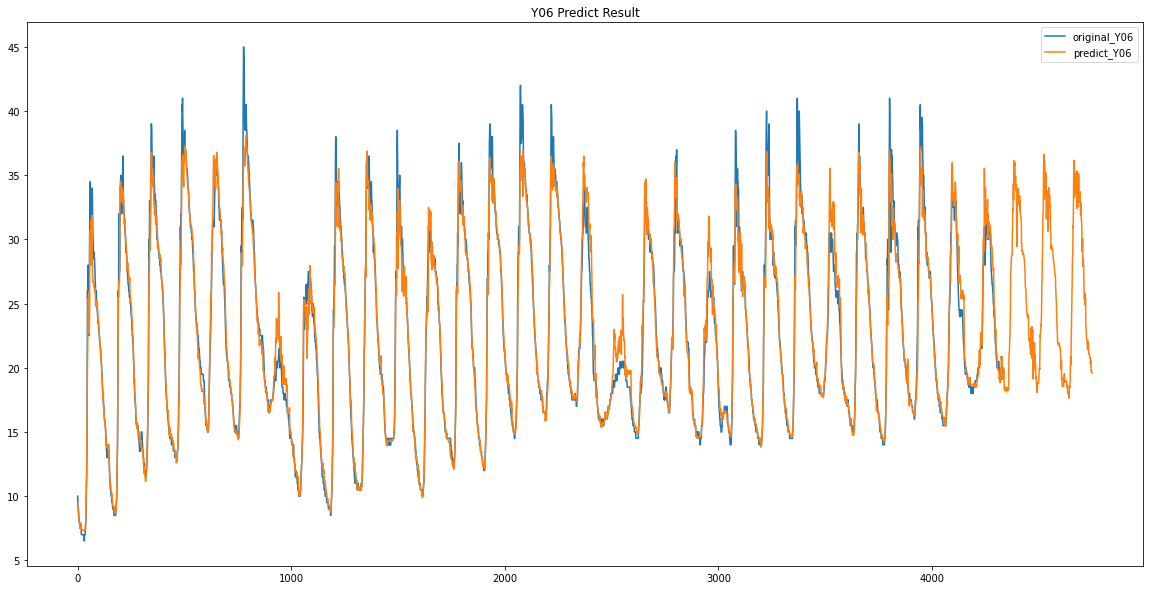
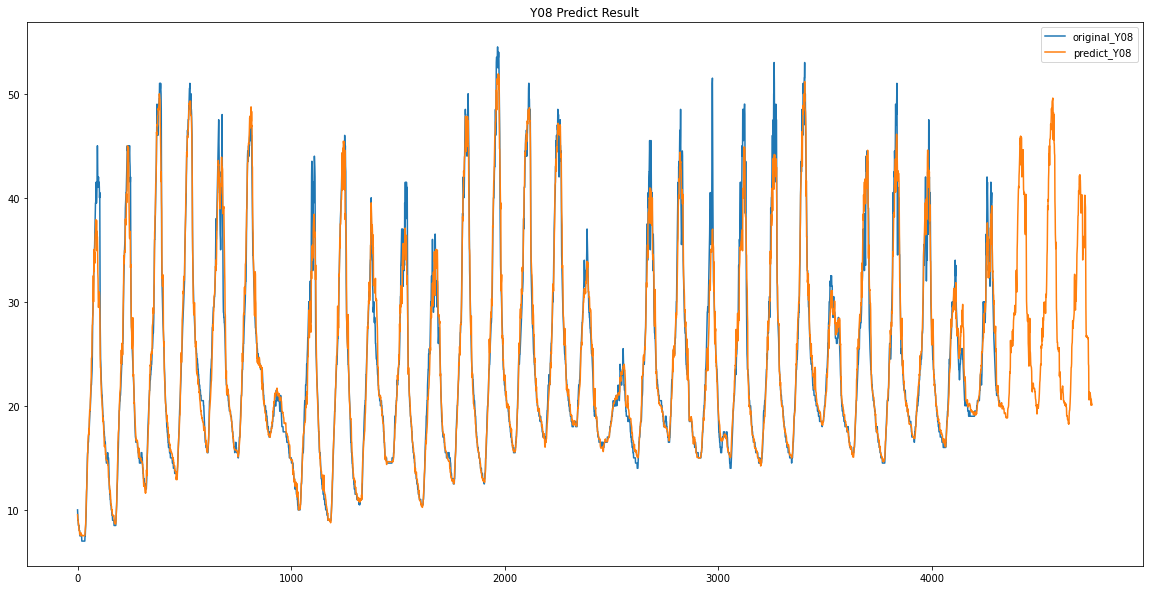
파란색이 원래 데이터 / 주황색이 예측한 데이터입니다.
data = train_data.loc[:, ['X00', 'X07', 'X11','X28', 'X31', 'X32', 'X34', 'Y00']].dropna()
X_train = data.loc[:, ['X00', 'X07', 'X11', 'X28', 'X31', 'X32', 'X34']]
Y_train = data['Y00']
lgb_with_best_params_for_predict = LGBMRegressor(learning_rate=0.01, max_depth=5, n_estimators=600)
lgb_with_best_params_for_predict.fit(X_train, Y_train)
for_predict_x_train = train_data.loc[:, ['X00', 'X07', 'X11','X28', 'X31', 'X32', 'X34']]
predict = lgb_with_best_params_for_predict.predict(for_predict_x_train)
predict_Y = pd.DataFrame({"Y00":predict})
data_for_input_predict_values.loc[4320: , ['Y00']] = predict_Y['Y00']
plt.figure(figsize=(20, 10))
plt.plot(train_data.loc[:, ['Y00']])
plt.plot(predict_Y)
plt.title("Y00 Predict Result")
plt.legend(["original_Y00", "predict_Y00"])
Y00 / Y01
Y02 / Y03
Y04 / Y05
Y06 / Y07

Y08 / Y09
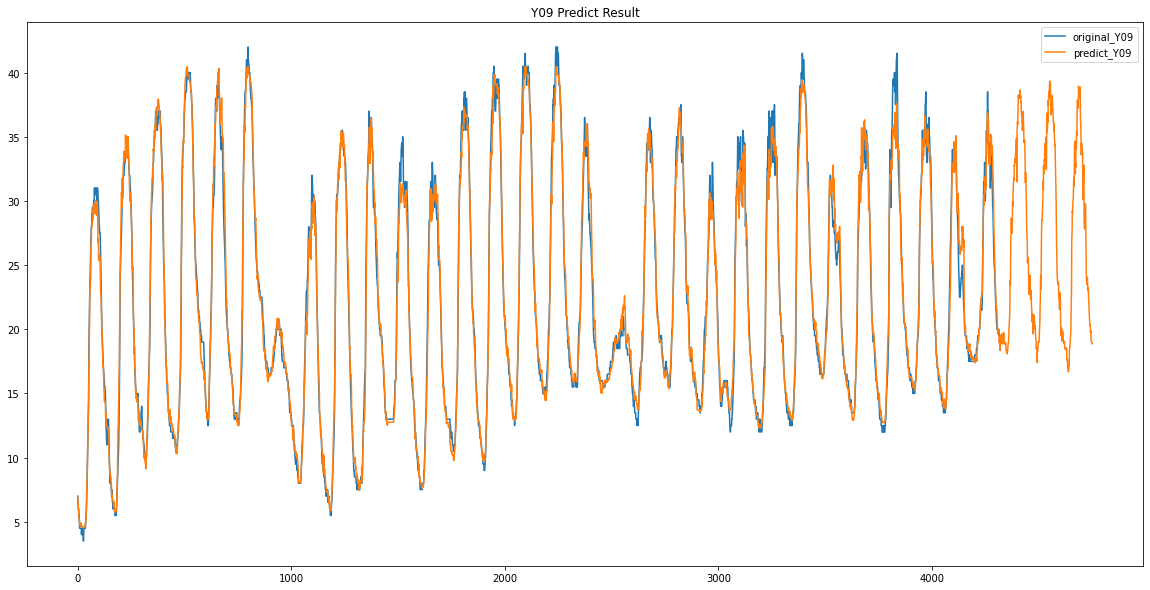
Y10 / Y11
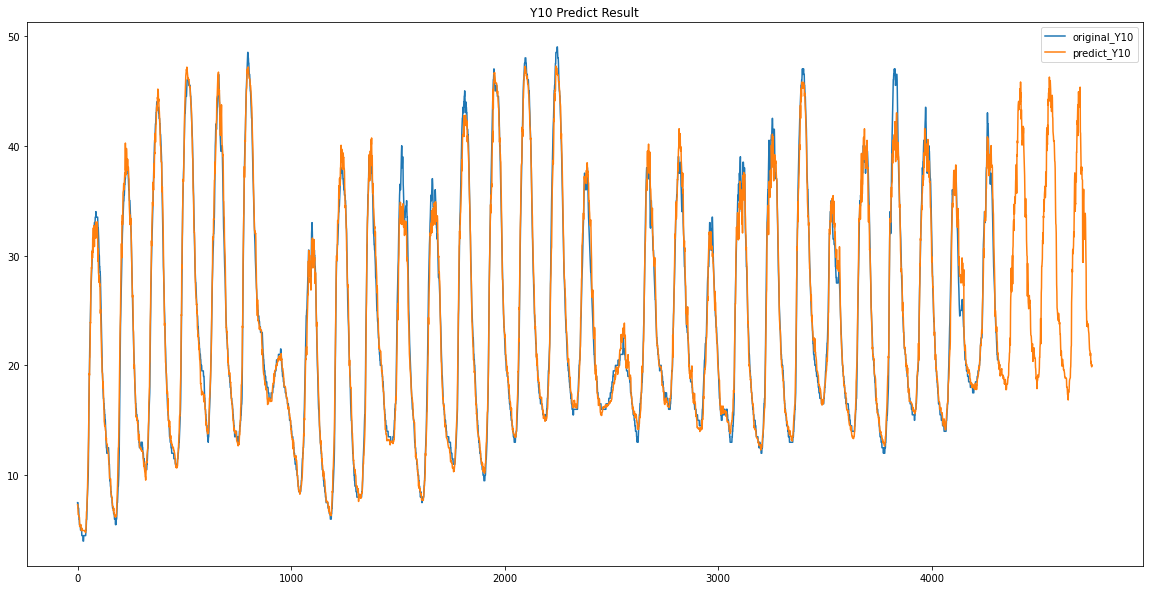
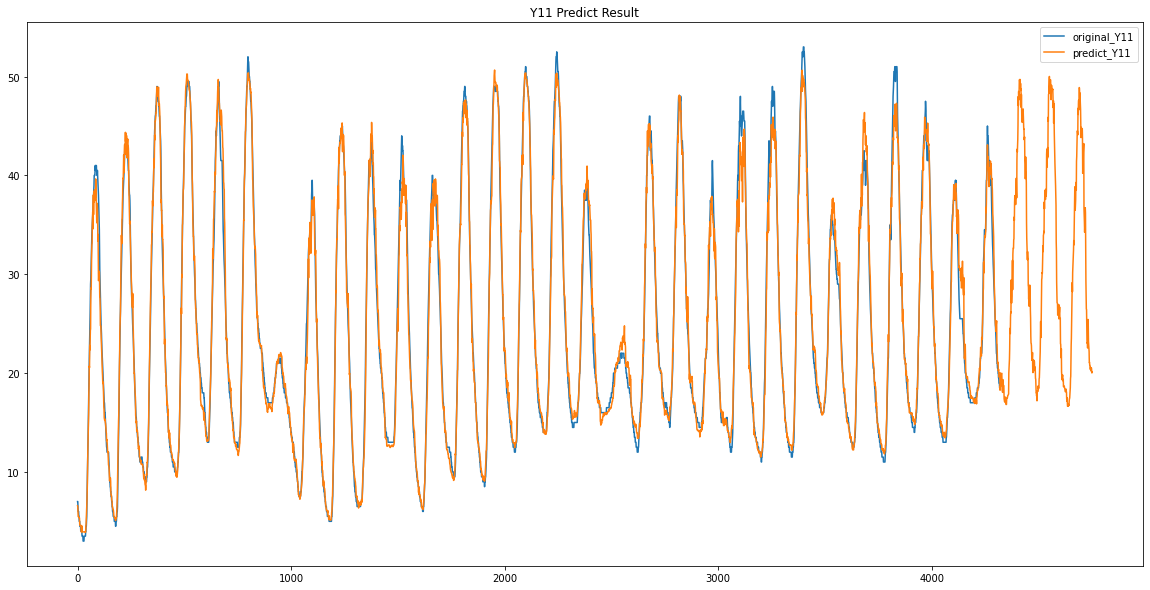
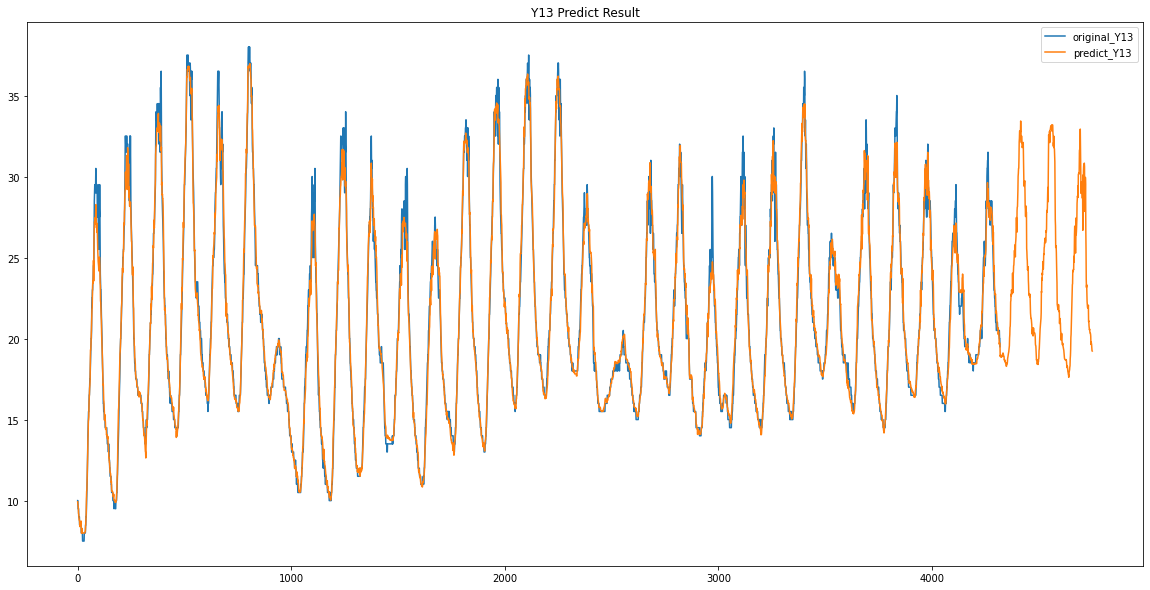
Y12 / Y13
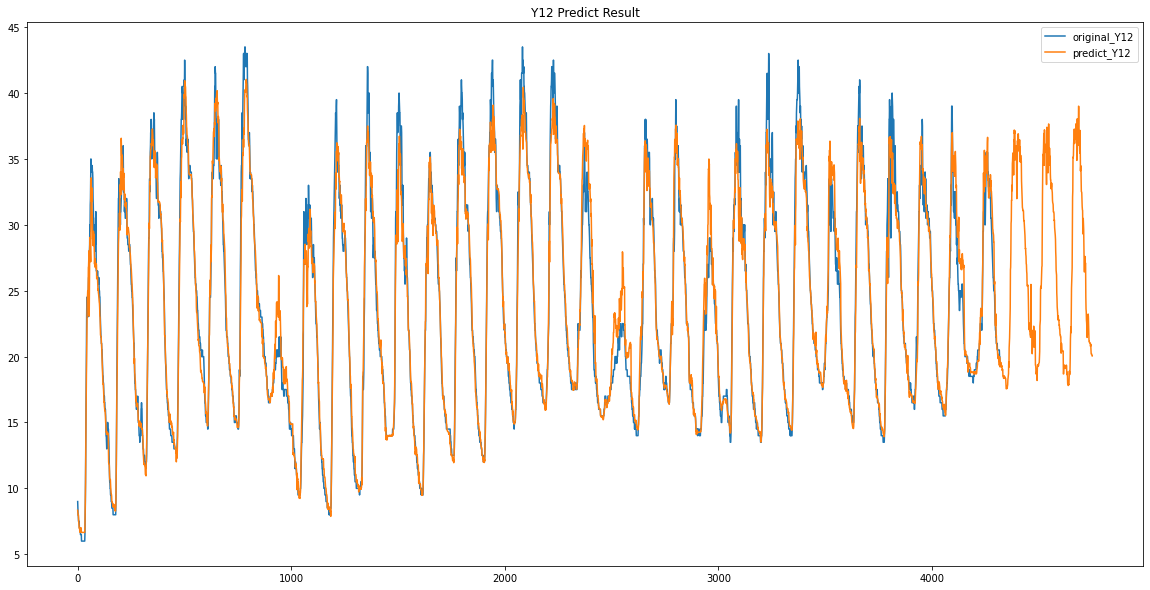
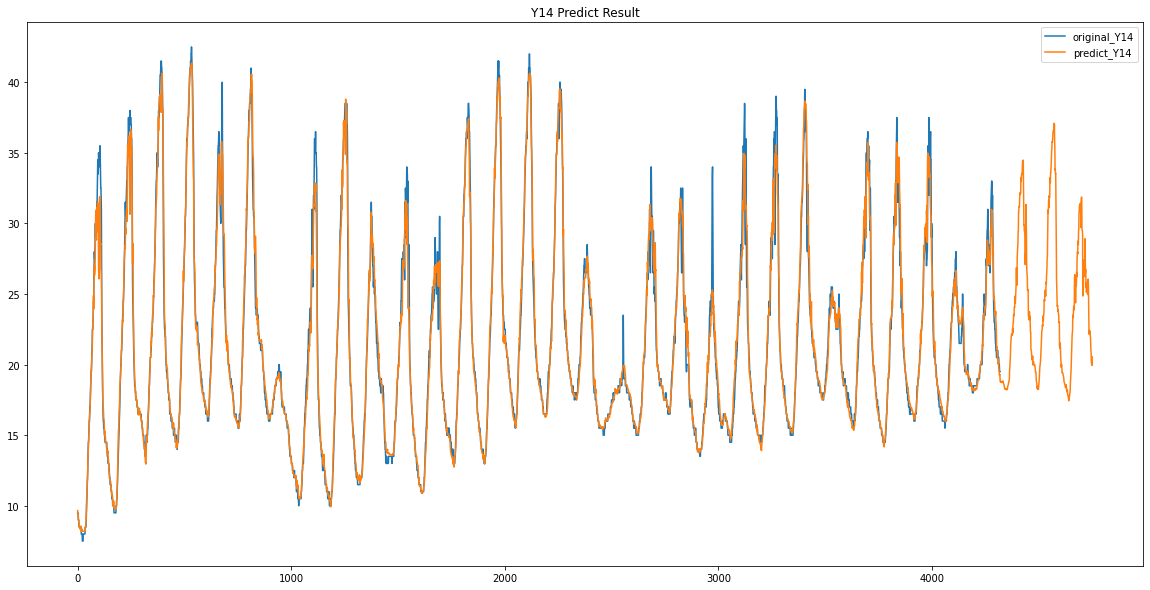
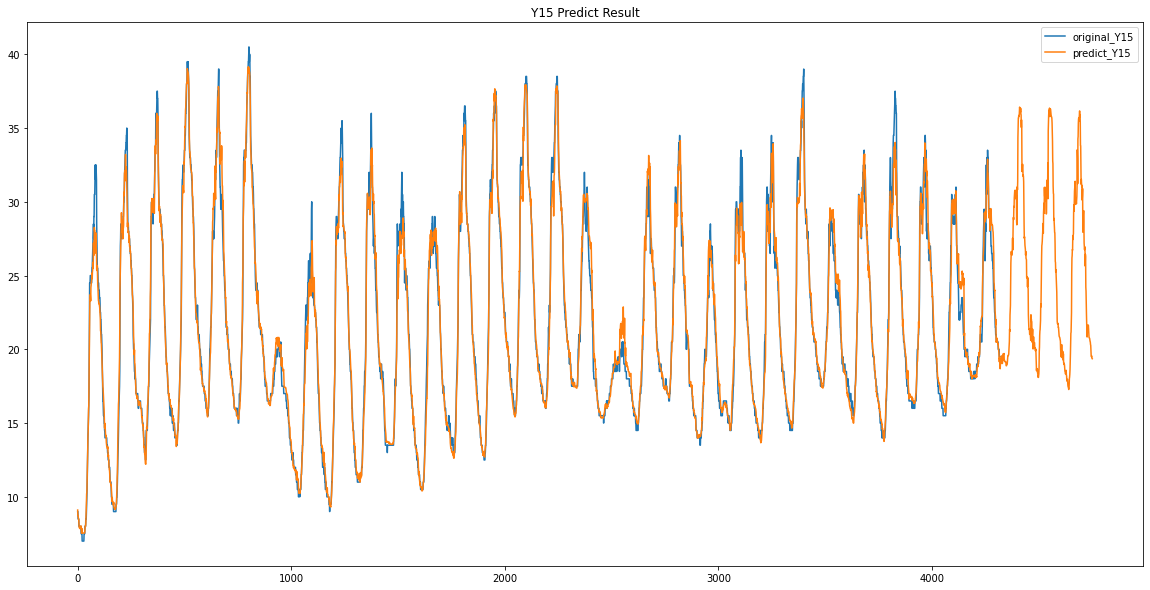
Y14 / Y15
Y16 / Y17
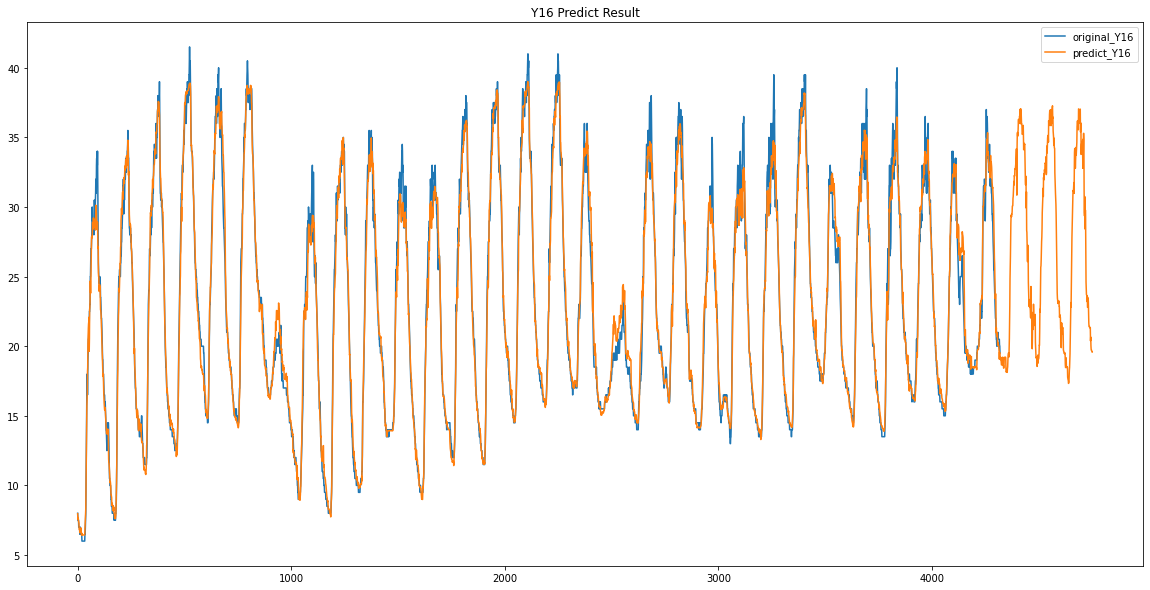
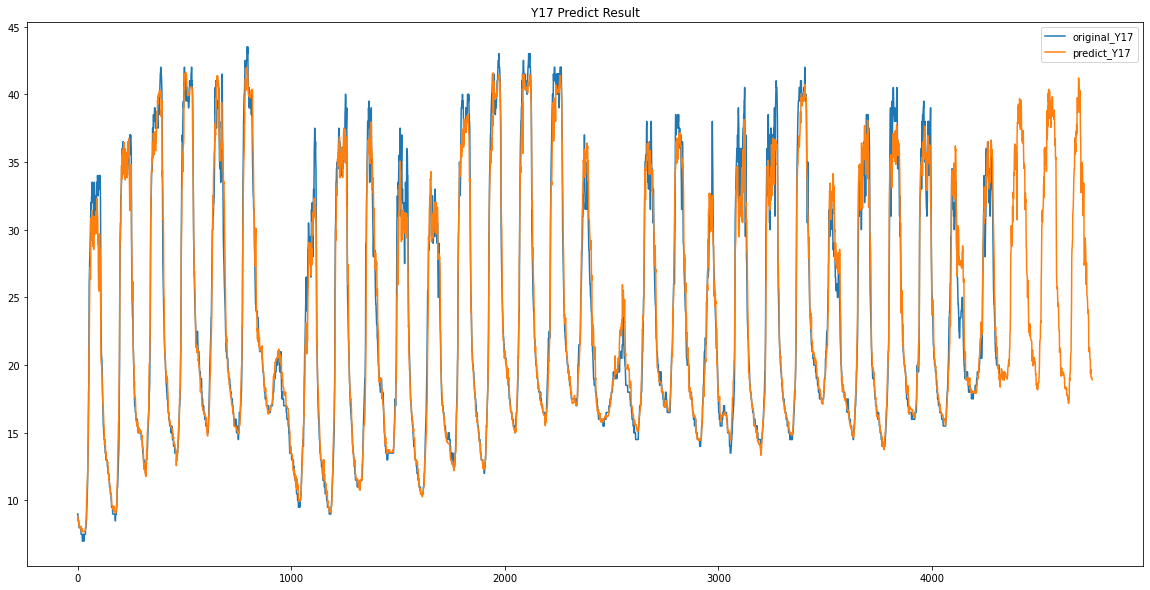
이렇게 Y00 ~ Y17 데이터가 없었던 3일동안의 데이터를 예측하였습니다.
이 예측한 3일간의 Y00 ~ Y17의 데이터를 가지고 Y18 데이터와 어떤 상관관계가 있는지 확인해보았습니다.
여기서 Y12와 0.93 / Y06과 0.92 / Y17과 0.91 / Y09와 0.9 / Y16과 0.9 라는 값을 얻을 수 있었습니다.
data_for_graph = data_for_input_predict_values.loc[:, ['Y06', 'Y09', 'Y12', 'Y16', 'Y17', 'Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.plot(data_for_graph)이들을 Y18과 함께 그래프를 그려보면 다음과 같았습니다.
비슷한 형태를 띄는 것 같지만 너무 많은 선들로 제대로 보이지 않아 Y06 ~ Y17를 각각 Y18과 한번씩 다 그려보았습니다.
data_for_graph_2 = data_for_input_predict_values.loc[4320:, ['Y06','Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.title('Y06 / Y18')
plt.plot(data_for_graph_2)data_for_graph_2 = data_for_input_predict_values.loc[4320:, ['Y09','Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.title('Y09 / Y18')
plt.plot(data_for_graph_2)data_for_graph_2 = data_for_input_predict_values.loc[4320:, ['Y12','Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.title('Y12 / Y18')
plt.plot(data_for_graph_2)data_for_graph_2 = data_for_input_predict_values.loc[4320:, ['Y16','Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.title('Y16 / Y18')
plt.plot(data_for_graph_2)data_for_graph_2 = data_for_input_predict_values.loc[4320:, ['Y17','Y18']].dropna()
plt.figure(figsize=(20, 10))
plt.title('Y17 / Y18')
plt.plot(data_for_graph_2)여기서 오늘은 Y09데이터를 Y18의 비어있는 30일치의 데이터로 사용하였습니다.
my_data = data_for_input_predict_values.loc[0:4320, ['Y09']]
data_for_input_predict_values.loc[0:4320, ['Y18']] = my_data['Y09']
data_for_input_predict_valuesX_train_Y18 = data_for_predict_Y18.loc[:, ['X00', 'X07', 'X11','X28', 'X31', 'X32', 'X34']]
Y_train_Y18 = data_for_predict_Y18['Y18'].astype('float64')
첫번째 제출
lgb_with_best_params_for_predict_Y18_after80days = LGBMRegressor(learning_rate=0.01, max_depth=5, n_estimators=600)
lgb_with_best_params_for_predict_Y18_after80days.fit(X_train_Y18, Y_train_Y18)
predict = lgb_with_best_params_for_predict_Y18_after80days.predict(X_test)
predict_labels = predict
ids = list(test['id'])
print(len(ids))
submission_dic = {"id":ids, "Y18":predict_labels}
submission_df = pd.DataFrame(submission_dic)
submission_df.to_csv("dacon_temp_sub_04_1.csv", index=False)파라미터는 아까 전에 찾았던 파라미터를 그대로 사용했습니다.
"learning_rate" : 0.01
"max_depth" : 5
"n_estimators" : 600결과
두번째 제출
lgb_with_best_params_for_predict_Y18_after80days = LGBMRegressor(learning_rate=0.007, max_depth=5, n_estimators=800)
lgb_with_best_params_for_predict_Y18_after80days.fit(X_train_Y18, Y_train_Y18)
predict = lgb_with_best_params_for_predict_Y18_after80days.predict(X_test)
predict_labels = predict
ids = list(test['id'])
print(len(ids))
submission_dic = {"id":ids, "Y18":predict_labels}
submission_df = pd.DataFrame(submission_dic)
submission_df.to_csv("dacon_temp_sub_04_2.csv", index=False)"learning_rate" : 0.007
"max_depth" : 5
"n_estimators" : 800결과
세번째 제출
lgb_with_best_params_for_predict_Y18_after80days = LGBMRegressor(learning_rate=0.007, max_depth=5, n_estimators=600)
lgb_with_best_params_for_predict_Y18_after80days.fit(X_train_Y18_2, Y_train_Y18_2)
predict = lgb_with_best_params_for_predict_Y18_after80days.predict(X_test)
predict_labels = predict
ids = list(test['id'])
print(len(ids))
submission_dic = {"id":ids, "Y18":predict_labels}
submission_df = pd.DataFrame(submission_dic)
submission_df.to_csv("dacon_temp_sub_04_3.csv", index=False)"learning_rate" : 0.007
"max_depth" : 5
"n_estimators" : 600결과
[공공] AI프렌즈 시즌1 온도 추정 경진대회
출처 : DACON - Data Science Competition
dacon.io
'DACON > AI프렌즈 시즌1 온도 추정 경진대회' 카테고리의 다른 글
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 7, 8회차 (0) | 2020.03.21 |
|---|---|
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 5, 6회차 (0) | 2020.03.19 |
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 3회차 (0) | 2020.03.14 |
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 2회차 (0) | 2020.03.13 |
| 데이콘 X AI 프렌즈 온도추정 경진대회 도전 1회차 (0) | 2020.03.12 |



