
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- leetcode
- 백준
- SW Expert Academy
- 맥북
- programmers
- 코로나19
- gs25
- 금융문자분석경진대회
- Kaggle
- 우분투
- github
- 데이콘
- 파이썬
- PYTHON
- 캐치카페
- Docker
- 편스토랑 우승상품
- Git
- Real or Not? NLP with Disaster Tweets
- 자연어처리
- Baekjoon
- ChatGPT
- ubuntu
- 프로그래머스 파이썬
- dacon
- hackerrank
- 편스토랑
- 프로그래머스
- AI 경진대회
- 더현대서울 맛집
- Today
- Total
솜씨좋은장씨
DACON 금융문자분석 공모전 - 도전 1일차 본문
1. 도전하게 된 계기
[대회] 14회 금융문자 분석 경진대회
dacon.io
idEANS 팀원들과 함께했던 COMPAS 화성시 최적 시내버스 노선 제시 공모전을 잘 마무리하고
새로운 목표를 설정도 할겸 이번엔 멀티캠퍼스에서 자연어 처리를 들었던 내용을 살려 금융문자 분석 경진대회에 도전해보기로 했습니다.
[대회] 14회 금융문자 분석 경진대회 - [Dacon Baseline] 초급자용 코드
/*! * * Twitter Bootstrap * */ /*! * Bootstrap v3.3.7 (http://getbootstrap.com) * Copyright 2011-2016 Twitter, Inc. * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE) */ /*! normalize.css v3.0.3 | MIT License | github.com/necolas/
dacon.io
대회는 금융문자를 분석하여 이 문자가 스미싱일 확률이 얼마나 되는지를 분석하는 대회였습니다.
나중에 Private Score를 도출하는 상위 20팀의 점수들은 벌써 0.99를 넘어 새로 도전하는 사람에게 부담감을 주고 있었지만 그래도 도전해보고자 합니다.
2. 데이터 전처리
먼저 제공된 학습 데이터를 pandas의 read_csv를 활용하여 열어보았습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
총 295,945개의 문자 데이터를 확인할 수 있었습니다.
정상인 문자와 스미싱인 문자 데이터 비율이 어떻게 되는지 확인해보았습니다.
train_data['smishing'].value_counts().plot(kind='bar')print(train_data.groupby('smishing').size().reset_index(name='count'))
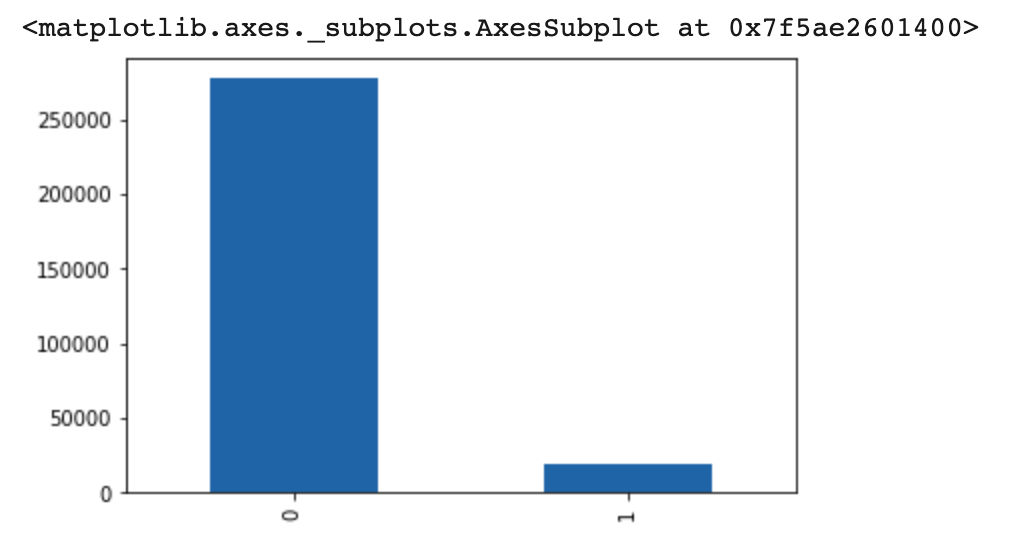

정상인 문자가 277,242개 스미싱인 문자가 18,703개로 정상인 문자가 약 15배 정도 많은 것을 알 수 있었습니다.
앞서 영화 평점 예측하기, 기사 분류하기 프로젝트를 진행하면서 학습하는 데이터의 비율이 불균형하면 한쪽으로 오버피팅 되는 경향이 있는 것 같아 스미싱 문자와 정상문자의 개수를 18,703개로 동일하게 맞추면 어떨까 생각해보았습니다.
먼저 DataFrame에서 정상인 문자만 추출하였습니다.
positive_df = train_data[train_data['smishing'] == 0]
positive_df
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
277,242개의 데이터 중에서 18,703개의 데이터만 선정해서 학습시킨다고 했을때 가장 학습 효과가 좋으려면 어떤 데이터를 선정하면 좋을지 생각하다가 문자 데이터가 가장 긴 것부터 18,703개를 선정하면 좋을 것 같다는 생각이 들었습니다.
먼저 제공된 데이터를 문자 데이터 길이가 긴 순서대로 정렬하기 위해서 len이라는 새로운 column에 각 row의 문자 데이터 길이 정보를 넣었습니다.
for i in tqdm(range(len(positive_df['smishing']))):
positive_df['len'].iloc[i] = len(positive_df['text'].iloc[i])

비효율적으로 for loop로 각 row를 탐색하며 len을 구하도록 하였더니 27만개의 데이터다보니 41분이라는 시간이 걸렸습니다.
더 효율적으로 할 수 있는 방법은 더 공부하면서 알아봐야겠습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
len이라는 column에 각 문자의 길이 정보가 담겨있는 것을 볼 수 있습니다.
positive_df_desen = positive_df.sort_values(by=['len'], axis=0, ascending=False)
positive_df_desenlen의 크기가 큰 순서대로 정렬해주었습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
정렬하고 보니 이름만 XXX로 치환한 줄 알았지만 일부 데이터에서는 불필요한 XXX 값이 너무 많은 것을 수 있었습니다.
for i in tqdm(range(277242)):
positive_df_desen['clear_text'].iloc[i] = positive_df_desen['text'].iloc[i].replace('XXX','')
XXX값을 제거한 값을 clear_text라는 column을 만들고 넣어주었습니다.
이 과정은 글을 쓰다보니 그냥 text column의 데이터를 list로 받은 뒤에 XXX를 제거하고 clear_text column에 넣었으면 더 빠른 시간 안에 하지 않았을까 생각이 들었습니다.
from tqdm import tqdm
text_datas = list(positive_df_desen['text'])
clear_text_datas = []
for i in tqdm(range(len(text_datas))):
clear_text_datas.append(text_datas[i].replace('XXX', ''))글쓰면서 직접해보니 실제로..... 1시간 12분을 단 1초도 걸리지 않는 시간에........ 할 수 있음을 알 수 있었습니다.
다음에는 더 빠른 전처리가 가능할 것으로 보입니다.(눈...물)
for i in tqdm(range(len(positive_df_desen['smishing']))):
positive_df_desen['len2'].iloc[i] = len(positive_df_desen['clear_text'].iloc[i])이번에도 동일하게 len2라는 새로운 column을 만들고 정제한 문자 데이터의 길이를 넣어주었습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
정상 문자 다음으로 스미싱 문자도 동일하게 clear_text와 len2 column을 추가해주었습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
new_df = pd.concat([nega_df_desen, posi_df_densen])
new_dfconcat 메소드를 활용하여 길이가 긴 순서대로 18,703개의 정상문자데이터와 스미싱문자데이터를 하나로 합쳤습니다.
new_df_desen = new_df.sort_values(by=['id'], axis=0, ascending=True)
new_df_desennew_df_desen.to_csv("model_kb_dacon01_trainset.csv", index=False, encoding='utf-8')이렇게 되면 정상 문자 데이터가 스미싱문자데이터 아래에 붙어 딱 반반으로 붙어 이를 섞어주기 위해서 id값으로 정렬하고
추후 파일을 불러와 사용하기 위해서 csv파일로 저장하였습니다.
테스트 데이터는 clear_text column을 만들어 정제된 문자 데이터까지만 전처리 해주었습니다.
(데이터 유출을 방지하기 위해 사진은 삭제하였습니다.)
3. 모델링
stopwords = ['의', '가', '이', '은', '들', '는', '좀', '잘', '걍', '과', '도', '를', '으로', '자', '에', '와', '한', '하다']from tqdm import tqdm
X_train = []
for i in tqdm(range(len(new_df_desen['clear_text']))):
temp_X = []
temp_X = okt.morphs(new_df_desen['clear_text'].iloc[i], stem=True) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X_train.append(temp_X)먼저 okt 형태분석기의 morphs를 활용하여 형태소 단위로 나눈 뒤 불용어를 제거한 단어들을 제거하여 train데이터와 text데이터를 만들어 주었습니다.
from keras.preprocessing.text import Tokenizer
max_words = 35000
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)Keras의 preprocessing의 Tokenizer를 활용하여 정수인코딩을 실시합니다.
print("제목의 최대 길이 :" , max(len(l) for l in X_train))
print("제목의 평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()
from keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(new_df_desen['smishing'])):
if new_df_desen['smishing'].iloc[i] == 1:
y_train.append([0, 1])
elif new_df_desen['smishing'].iloc[i] == 0:
y_train.append([1, 0])
y_train = np.array(y_train)smishing인지 아닌지 라벨링 되어있는 것도 one-hot인코딩 해주었습니다.
from keras.layers import Embedding, Dense, LSTM
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
max_len = 568 # 전체 데이터의 길이를 568로 맞춘다
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
pad_sequences를 활용하여 전체 길이를 568로 맞추었습니다.
먼저 전에 FRANEE프로젝트를 진행하면서 뉴스기사 긍정/부정/중립 분류했던 모델을 변형해서 사용해보기로 했습니다.
somjang.tistory.com
기사분류때에는 긍정/부정/중립 이 3가지로 분류하여 activation을 softmax, loss를 categorical_crossentropy를 사용했지만
이번에는 스미싱인지 아닌지 2가지로 분류하기 때문에 sigmoid와 binary_crossentropy를 사용하였습니다.
첫번째 제출에 사용된 코드 (Google Colab -TPU)
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dense(2, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=5, batch_size=32, validation_split=0.1)| epoch | 5 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
첫번째 제출 결과
두번째 제출에 사용된 코드 (Google Colab -TPU)
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dense(2, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=5, batch_size=32)| epoch | 5 | batch_size | 32 |
| optimizer | rmsprop | validation_split | X |
두번째 제출 결과
세번째 제출에 사용된 코드 (Google Colab -TPU)
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dense(2, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=3, batch_size=32)| epoch | 3 | batch_size | 32 |
| optimizer | adam | validation_split | X |
세번째 제출 결과
제출용 csv만들기
mypredict = model2.predict(X_test)
submission_ids = list(test_data['id'])
my_result = []
for i in range(len(mypredict)):
my_result.append(mypredict[i][1])
sub_dict = {"id":submission_ids, "smishing":my_result}
submission_df = pd.DataFrame(sub_dict)
submission_df.to_csv("kb_submission.csv", index=False, encoding='utf-8')
도전 첫날 결과
첫날 28위의 결과를 얻을 수 있었습니다.
첫번째 제출 결과가 가장 좋았어서 가장 마지막 제출에서는 첫번째 제출했던 모델에서 validation_split만 변경하고 모든 데이터를 학습 시켰는데 오히려 오버피팅을 우려하여 epoch 수를 3으로 줄여서 그런지 점수가 더 나오지 않는 경향이 있었습니다.
앞으로 bi-LSTM 과같은 다른 Layer들을 활용해서 계속 도전해보고자 합니다.
읽어주셔서 감사합니다.
'DACON > KB 금융문자 분석 경진대회' 카테고리의 다른 글
| DACON 금융문자분석 공모전 - 도전 6일차 (8) | 2019.12.19 |
|---|---|
| DACON 금융문자분석 공모전 - 도전 5일차 (0) | 2019.12.18 |
| DACON 금융문자분석 공모전 - 도전 4일차 (0) | 2019.12.17 |
| DACON 금융문자분석 공모전 - 도전 3일차 (0) | 2019.12.16 |
| DACON 금융문자분석 공모전 - 도전 2일차 (0) | 2019.12.15 |



