
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- PYTHON
- ChatGPT
- hackerrank
- Real or Not? NLP with Disaster Tweets
- 캐치카페
- Docker
- leetcode
- AI 경진대회
- 코로나19
- Kaggle
- 편스토랑
- 프로그래머스 파이썬
- Baekjoon
- 우분투
- github
- 편스토랑 우승상품
- gs25
- Git
- 더현대서울 맛집
- programmers
- SW Expert Academy
- 데이콘
- 파이썬
- dacon
- 백준
- ubuntu
- 프로그래머스
- 자연어처리
- 맥북
- 금융문자분석경진대회
- Today
- Total
솜씨좋은장씨
[Keras]기사 제목을 가지고 긍정 / 부정 / 중립으로 분류하는 모델 만들어보기 본문
[Keras]기사 제목을 가지고 긍정 / 부정 / 중립으로 분류하는 모델 만들어보기
솜씨좋은장씨 2019. 10. 7. 21:31
프로젝트를 진행하면서 네이버 기사 내용을 긍정/부정으로 분류해주는 기능을 넣자고 하여 구현해보았습니다.
모델을 만드는 것은 위키독스에서 제공하는 딥러닝을 이용한 자연어처리 입문에 나와있는 코드를 활용하였습니다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
0. 코드 관련
2020년 12월 22일 일부 코드 업데이트가 진행되었습니다.
아래의 코드의 대부분은 python과 keras를 공부한지 두달도 안된 상황에서 진행한 코드로 중간중간 설명이 이상하거나
제대로 동작하지 않는 부분이 있을 수도 있습니다. 양해부탁드립니다.
기사 제목 분류 관련 전체적인 코드 업데이트는 2021년에 진행할 예정입니다.
감사합니다.
솜장 드림.
1. 학습데이터, 테스트데이터 만들기
먼저 모델을 만들고 나서 학습을 시킬 데이터를 만들기 위해 네이버에서 몇몇의 기업을 선정하고
그 기업에 대한 기사의 제목을 크롤링하였습니다.
크롤링 후에 학습시 필요한 긍정, 부정, 중립을 나타내는 label이 있었어야했는데
손으로 일일이 부정, 긍정, 중립 이 세 가지로 label을 붙이려고 하다보니
눈도 아프고 비슷한 내용임에도 불구하고 앞에서는 긍정으로 했다가 뒤에서는 중립으로 표기하는 등의 문제가 있었습니다.
이를 컴퓨터가 긍정적인 단어, 부정적인 단어가 포함되어있는지 여부를 확인하여
자동으로 라벨을 붙여주면 편할 것 같아 그렇게 만들어 보았습니다.
먼저, 긍정적인 단어, 부정적인 단어가 포함된 txt파일을 각각 만들어주었습니다.
뉴스 기사를 보며 만든 긍정적인 단어, 부정적인 단어 모음입니다.
단어는 생각나는대로 계속 추가하고자합니다.
코드에서는 이 단어들을 파일에서 positive, negative라는 list로 받아와서
두 개의 list를 합쳐 posneg라는 list를 만들고 크롤링해오는 단어에서 posneg안에 있는 단어가 포함되어있으면 긍정, 부정 라벨을 붙여주고
포함되어있지 않으면 그냥 중립인 0의 상태로 그대로 두도록 만들어 보았습니다.
2020년 12월 22일 업데이트 전 코드 ( 업데이트 버전은 스크롤을 내려 나오는 코드를 참고해주세요! )
파일에서 단어를 불러와 posneg리스트를 만드는 코드
import codecs
positive = []
negative = []
posneg = []
pos = codecs.open("./positive_words_self.txt", 'rb', encoding='UTF-8')
while True:
line = pos.readline()
line = line.replace('\n', '')
positive.append(line)
posneg.append(line)
if not line: break
pos.close()
neg = codecs.open("./negative_words_self.txt", 'rb', encoding='UTF-8')
while True:
line = neg.readline()
line = line.replace('\n', '')
negative.append(line)
posneg.append(line)
if not line: break
neg.close()
크롤링한 기사 제목과 기사 제목과 posneg를 활용하여 만든 긍정(1), 부정(-1), 중립(0)라벨 정보를 가지는 dataframe을 만드는 코드
(예시 : 네이버에서 버거킹으로 검색하여 나온 기사 4,000개 제목과 각각 제목의 긍정, 부정, 중립 라벨 생성)
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
label = [0] * 4000
my_title_dic = {"title":[], "label":label}
j = 0
for i in range(400):
num = i * 10 + 1
# bhc
# url = "https://search.naver.com/search.naver?&where=news&query=bhc&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&mynews=0&cluster_rank=23&start=" + str(num)
# 아오리라멘
# url2 = "https://search.naver.com/search.naver?&where=news&query=%EC%95%84%EC%98%A4%EB%A6%AC%EB%9D%BC%EB%A9%98&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&mynews=0&cluster_rank=34&start=" + str(num)
# 버거킹
url3 = "https://search.naver.com/search.naver?&where=news&query=%EB%B2%84%EA%B1%B0%ED%82%B9&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&mynews=0&cluster_rank=23&start=" + str(num)
req = requests.get(url3)
soup = BeautifulSoup(req.text, 'lxml')
titles = soup.select("a._sp_each_title")
for title in titles:
title_data = title.text
title_data = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…\"\“》]', '', title_data)
my_title_dic['title'].append(title_data)
for i in range(len(posneg)):
posflag = False
negflag = False
if i < (len(positive)-1):
# print(title_data.find(posneg[i]))
if title_data.find(posneg[i]) != -1:
posflag = True
print(i, "positive?","테스트 : ",title_data.find(posneg[i]),"비교단어 : ", posneg[i], "인덱스 : ", i, title_data)
break
if i > (len(positive)-2):
if title_data.find(posneg[i]) != -1:
negflag = True
print(i, "negative?","테스트 : ",title_data.find(posneg[i]),"비교단어 : ", posneg[i], "인덱스 : ", i, title_data)
break
if posflag == True:
label[j] = 1
# print("positive", j)
elif negflag == True:
label[j] = -1
# print("negative", j)
elif negflag == False and posflag == False:
label[j] = 0
# print("objective", j)
j = j + 1
my_title_dic['label'] = label
my_title_df = pd.DataFrame(my_title_dic)이렇게 만든 데이터 프레임은
def dftoCsv(my_title_df, num):
my_title_df.to_csv(('./title_datas'+ str(num) +'.csv'), sep=',', na_rep='NaN', encoding='utf-8')다음 코드를 활용하여 csv파일로 저장하였습니다.
2020년 12월 22일 업데이트 버전 코드
크롤링 후 positive, negative 단어를 활용해 간단하게 라벨을 다는 부분만 업데이트 하였습니다.
with open("./negative_words_self.txt", encoding='utf-8') as neg:
negative = neg.readlines()
negative = [neg.replace("\n", "") for neg in negative]
with open("./positive_words_self.txt", encoding='utf-8') as pos:
positive = pos.readlines()
negative = [neg.replace("\n", "") for neg in negative]
positive = [pos.replace("\n", "") for pos in positive]먼저 negative 단어 파일, positive 단어 파일을 with open으로 불러와서 각각 파일에 담겨있던 단어들을
리스트로 만들어줍니다.
크롤링을 진행하면서 바로 라벨을 붙이는 경우
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
from tqdm import tqdm
labels = []
titles = []
j = 0
for k in tqdm(range(400)):
num = k * 10 + 1
# 버거킹
url = "https://search.naver.com/search.naver?&where=news&query=%EB%B2%84%EA%B1%B0%ED%82%B9&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&mynews=0&cluster_rank=23&start=" + str(num)
req = requests.get(url)
soup = BeautifulSoup(req.text, 'lxml')
titles = soup.select("a._sp_each_title")
for title in titles:
title_data = title.text
clean_title = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…\"\“》]', '', title_data)
negative_flag = False
label = 0
for i in range(len(negative)):
if negative[i] in clean_title:
label = -1
negative_flag = True
print("negative 비교단어 : ", negative[i], "clean_title : ", clean_title)
break
if negative_flag == False:
for i in range(len(positive)):
if positive[i] in clean_title:
label = 1
print("positive 비교단어 : ", positive[i], "clean_title : ", clean_title)
break
titles.append(clean_title)
labels.append(label)
my_title_df = pd.DataFrame({"title":titles, "label":labels})그 다음 네이버에서 버거킹에 관한 뉴스 제목을 크롤링 해오고
각 기사에 대해서 아까 만들어둔 negative, positive 리스트를 활용하여 라벨을 붙여줍니다.
( 현재 이 방식은 정말정말 기초적인 방식으로 라벨링을 하는 것이기 때문에 실제 긍정 부정과는 다를 수 있습니다. )
크롤링 코드는 상황에 따라 작동하지 않을 수 있습니다.
제목만 있는 DataFrame을 가지고 라벨을 붙이는 경우
from tqdm import tqdm
import re
labels = []
title_data = list(my_title_df['title'])
for title in tqdm(title_data):
clean_title = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…\"\“》]', '', title)
negative_flag = False
label = 0
for i in range(len(negative)):
if negative[i] in clean_title:
label = -1
negative_flag = True
print("negative 비교단어 : ", negative[i], "clean_title : ", clean_title)
break
if negative_flag == False:
for i in range(len(positive)):
if positive[i] in clean_title:
label = 1
print("positive 비교단어 : ", positive[i], "clean_title : ", clean_title)
break
labels.append(label)
my_title_df['label'] = labels
학습데이터는 위의 코드를 통해 만들어진
버거킹기사 4,000개, 아오리라멘 기사 1,000개, 국대떡볶이기사 1,000개 데이터를 합쳐서 활용하였습니다.
테스트데이터는 맘스터치 1,500개의 기사데이터를 활용하였습니다.
2. 데이터 분석해보기
만들어진 csv파일을 google drive에 업로드하고 google colab에서 google drive를 마운트한 뒤 진행했습니다.
import pandas as pd
train_data = pd.read_csv("./train_dataset_1007.csv")
test_data = pd.read_csv("./test_dataset_1007.csv")train_data와 test_data를 pandas의 read_csv를 활용하여 dataframe으로 불러옵니다.
그 다음 matplotlib을 활용하여 -1, 0, 1 라벨별로 각각 몇개의 데이터가 존재하는지 확인해봅니다.
%matplotlib inline
import matplotlib.pyplot as plttrain_data['label'].value_counts().plot(kind='bar')

test_data['label'].value_counts().plot(kind='bar')
숫자로도 확인해봅니다. 1이 긍정 -1이 부정 0이 중립입니다.
print(train_data.groupby('label').size().reset_index(name='count'))
print(test_data.groupby('label').size().reset_index(name='count'))
3. 모델을 만들기 위한 데이터 전처리 작업
먼저 각각의 제목을 토큰화 해주었습니다.
Okt형태소 분석기를 활용하였습니다.
stopwords = ['의', '가', '이', '은', '들', '는', '좀', '잘', '걍', '과', '도', '를', '으로', '자', '에', '와', '한', '하다']import konlpy
from konlpy.tag import Okt
okt = Okt()
X_train = []
for sentence in train_data['title']:
temp_X = []
temp_X = okt.morphs(sentence, stem=True) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X_train.append(temp_X)
X_test = []
for sentence in test_data['title']:
temp_X = []
temp_X = okt.morphs(sentence, stem=True) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
X_test.append(temp_X)토큰화가 잘 되었는지 출력해보면 다음과 같습니다.

토큰화 한 단어를 컴퓨터가 인식할 수 있도록 정수인코딩을 해주었습니다.
from keras.preprocessing.text import Tokenizer
max_words = 35000
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
데이터의 최대길이 평균길이 그리고 길이를 기준으로 데이터의 분포가 어떠한지 확인해 보았습니다.
print("제목의 최대 길이 : ", max(len(l) for l in X_train))
print("제목의 평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()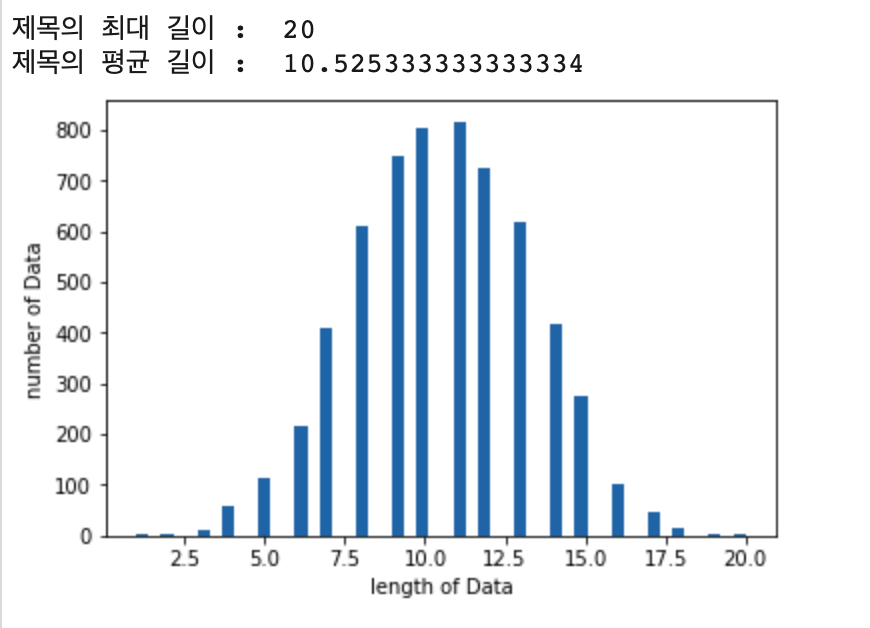
print("제목의 최대 길이 : ", max(len(l) for l in X_test))
print("제목의 평균 길이 : ", sum(map(len, X_test))/ len(X_test))
plt.hist([len(s) for s in X_test], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()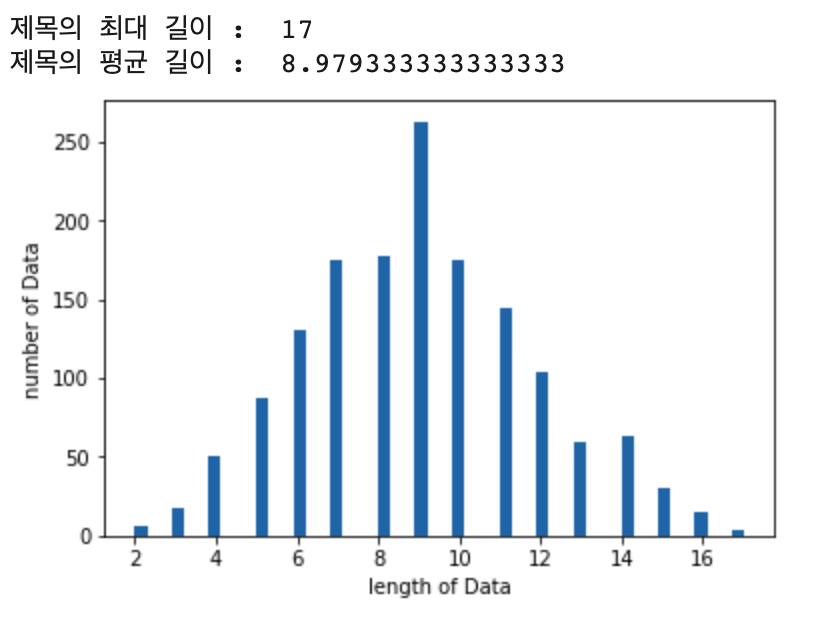
다음으로는 y값으로 들어갈 label -1, 0, 1을 컴퓨터가 보고 알수 있도록 one-hot encoding을 해주었습니다.
import numpy as np
y_train = []
y_test = []
for i in range(len(train_data['label'])):
if train_data['label'].iloc[i] == 1:
y_train.append([0, 0, 1])
elif train_data['label'].iloc[i] == 0:
y_train.append([0, 1, 0])
elif train_data['label'].iloc[i] == -1:
y_train.append([1, 0, 0])
for i in range(len(test_data['label'])):
if test_data['label'].iloc[i] == 1:
y_test.append([0, 0, 1])
elif test_data['label'].iloc[i] == 0:
y_test.append([0, 1, 0])
elif test_data['label'].iloc[i] == -1:
y_test.append([1, 0, 0])
y_train = np.array(y_train)
y_test = np.array(y_test)
4. 모델 만들기
from keras.layers import Embedding, Dense, LSTM
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
max_len = 20 # 전체 데이터의 길이를 20로 맞춘다
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)먼저 필요한 것들을 import 해주고 pad_sequences를 활용하여 모든 데이터의 길이를 20으로 통일하였습니다.
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dense(3, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10, batch_size=10, validation_split=0.1)긍정, 부정, 중립 3가지로 분류해야하니 LSTM, softmax, categorical_crossentropy를 사용하였습니다.
batch_size는 10 6,000개의 훈련데이터 중 10퍼센트인 600개는 validation_data로 활용하기위해 validation_split을 0.1을 부여하였습니다.
optimizer는 rmsprop을 사용하여 위와 같이 모델을 만들고 학습을 시켜보았습니다.


맘스터치관련 기사 제목 1,000개로 구성되어있는 테스트 데이터셋으로 평가해보니 94.27퍼센트가 나왔습니다.
생각보다 너무 잘나와서 조금 이상하지만 optimizer만 adam으로 바꿔 한번 더 해보았습니다.


이번엔 96.07%라는 결과가 나왔습니다.
predict = model.predict(X_test)import numpy as np
predict_labels = np.argmax(predict, axis=1)
original_labels = np.argmax(y_test, axis=1)for i in range(30):
print("기사제목 : ", test_data['title'].iloc[i], "/\t 원래 라벨 : ", original_labels[i], "/\t예측한 라벨 : ", predict_labels[i])
numpy와 predict를 활용하여 원래 라벨과 예측한 라벨을 비교해보았습니다.
생각보다 예측을 잘 하는 것 같습니다.
5. 느낀점 및 앞으로의 계획
저번 영화 평점 예측에 이어 이번엔 기사 제목이 긍정인지, 부정인지, 중립인지 분류해보았습니다.
생각보다 분류를 잘하는 것에 신기했지만 한편으로는 중립 데이터가 많아 잘 되는 것 같은 느낌도 들었습니다.
더 공부해서 영화평점예측과 추석에 하다가 말았던 추석 귀성/귀경 소요시간 예측도 더 발전시켜 보고 싶습니다~
'머신러닝 | 딥러닝 > TensorFlow | Keras' 카테고리의 다른 글
| [TF2.0] Tensorflow 2.0 GPU 사용 가능 여부 확인하기 (0) | 2020.10.06 |
|---|---|
| [TensorFlow] ImportError: libcusolver.so.8.0: cannot open shared object file: No such file or directory 해결 방법 (0) | 2020.07.20 |
| [TF2.0] MNIST - ValueError: Shapes (32, 10) and (32, 1) are incompatible 해결 방법 (10) | 2020.06.28 |
| [Keras]영화 평점, 줄거리를 가지고 평점 예측 모델 만들어보기 (6) | 2019.09.27 |
| [Keras]Keras에서 Model이란(feat, 레고블럭) (0) | 2019.09.13 |



