
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 프로그래머스 파이썬
- SW Expert Academy
- PYTHON
- hackerrank
- Git
- Docker
- 자연어처리
- 맥북
- gs25
- 백준
- AI 경진대회
- programmers
- 데이콘
- 우분투
- 캐치카페
- ChatGPT
- Real or Not? NLP with Disaster Tweets
- github
- Baekjoon
- 더현대서울 맛집
- 코로나19
- 프로그래머스
- 파이썬
- 편스토랑
- dacon
- 편스토랑 우승상품
- 금융문자분석경진대회
- Kaggle
- ubuntu
- leetcode
- Today
- Total
솜씨좋은장씨
DACON 금융문자분석 공모전 - 도전 3일차 본문
첫번째 시도해본 모델 (Google Colab -GPU)
ELMo를 활용하여보기로 하였습니다.
import tensorflow_hub as hub
import tensorflow as tf
from keras import backend as K
sess = tf.Session()
K.set_session(sess)
elmo = hub.Module("https://tfhub.dev/google/elmo/1", trainable=True)
sess.run(tf.global_variables_initializer())
sess.run(tf.tables_initializer())
def ELMoEmbedding(x):
return elmo(tf.squeeze(tf.cast(x, tf.string)), as_dict=True, signature="default")["default"]
from keras.models import Model
from keras.layers import Dense, Lambda, Input
input_text = Input(shape=(1,), dtype=tf.string)
embedding_layer = Lambda(ELMoEmbedding, output_shape=(1024, ))(input_text)
hidden_layer = Dense(256, activation='relu')(embedding_layer)
output_layer = Dense(2, activation='sigmoid')(hidden_layer)
model3 = Model(inputs=[input_text], outputs=output_layer)
model3.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
X_train2 = list(train_data['clear_text'])
X_train2 = np.asarray(X_train2)
history2 = model4.fit(X_train2, y_train, epochs=3, batch_size=32)#, validation_data=(X_val, y_val))

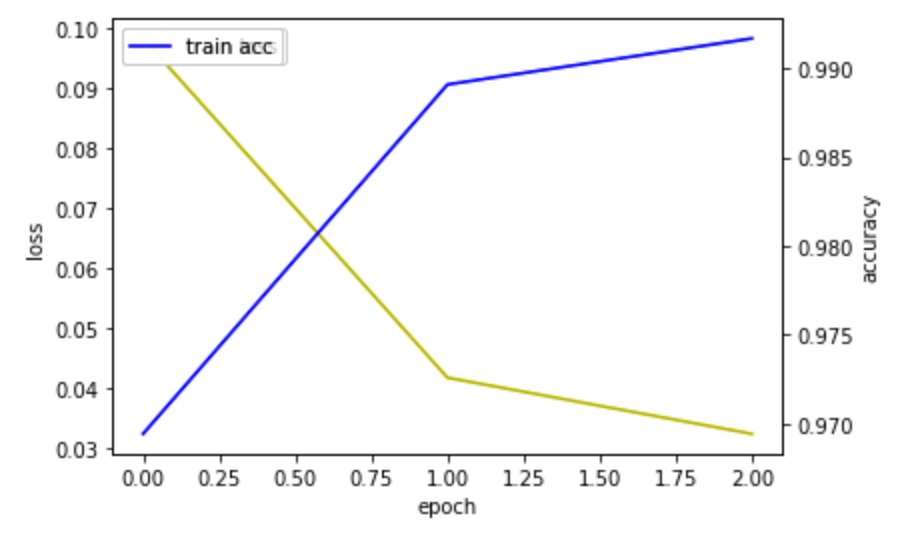
첫번째 시도 결과

음... 점수가 너무 낮게 나왔습니다.
제출의 횟수가 하루에 3번으로 정해져있기때문에 기존의 모델로 다시 도전해보고 20위 안에 들었을때 다시 도전해보려합니다.
이번에는 가장 점수가 좋았던 가장 첫번째 모델에
기존 학습데이터에서 특수문자를 제거하여 만든 데이터를 새로 만들어 학습시켜보기로 했습니다.
import re
train_clear_text = list(train_data['clear_text'])
train_clear_text2 = []
for text in train_clear_text:
temp = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]', '', text)
train_clear_text2.append(temp)
train_data['clear_text2'] = train_clear_text2
train_data먼저 정규식을 활용하여 특수문자를 제거하였습니다.
특수문자를 제거하고나니 문자의 최대길이가 380으로 줄었습니다.
max_len = 380 # 전체 데이터의 길이를 380로 맞춘다
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)모든 데이터의 길이를 380으로 맞춰주고 학습을 시켜보았습니다.
epoch, batch_size를 계속 바꿔가며 계속 시도해보았습니다.
1. epoch 5 / batch_size 32 (Google Colab -TPU)
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dense(2, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=5, batch_size=32, validation_split=0.1)| epoch | 5 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
2. epoch 2 / batch_size 32 (Google Colab -TPU) <두번째 제출 모델>
model2 = Sequential()
model2.add(Embedding(max_words, 100))
model2.add(LSTM(128))
model2.add(Dense(2, activation='sigmoid'))
model2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history2 = model2.fit(X_train, y_train, epochs=2, batch_size=32, validation_split=0.1)| epoch | 2 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
3. epoch 5 / batch_size 64 (Google Colab -TPU)
model3 = Sequential()
model3.add(Embedding(max_words, 100))
model3.add(LSTM(128))
model3.add(Dense(2, activation='sigmoid'))
model3.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history3 = model3.fit(X_train, y_train, epochs=5, batch_size=64, validation_split=0.1)| epoch | 5 | batch_size | 64 |
| optimizer | adam | validation_split | 0.1 |
4. epoch 5 / batch_size 100 (Google Colab -TPU)
model4 = Sequential()
model4.add(Embedding(max_words, 100))
model4.add(LSTM(128))
model4.add(Dense(2, activation='sigmoid'))
model4.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history4 = model4.fit(X_train, y_train, epochs=5, batch_size=100, validation_split=0.1)| epoch | 5 | batch_size | 100 |
| optimizer | adam | validation_split | 0.1 |
5. epoch 5 / batch_size 1,000 (Google Colab -TPU)
model5 = Sequential()
model5.add(Embedding(max_words, 100))
model5.add(LSTM(128))
model5.add(Dense(2, activation='sigmoid'))
model5.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history5 = model5.fit(X_train, y_train, epochs=5, batch_size=1000, validation_split=0.1)| epoch | 5 | batch_size | 1,000 |
| optimizer | adam | validation_split | 0.1 |
6. epoch 10 / batch_size 1,000 (Google Colab -TPU)
model6 = Sequential()
model6.add(Embedding(max_words, 100))
model6.add(LSTM(128))
model6.add(Dense(2, activation='sigmoid'))
model6.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history6 = model6.fit(X_train, y_train, epochs=10, batch_size=1000, validation_split=0.1)| epoch | 10 | batch_size | 1,000 |
| optimizer | adam | validation_split | 0.1 |
두번째 제출
두번째 제출은 위에서 해봤던 다양한 시도 중 2번째 시도했던 결과를 제출하였습니다.
두번째 제출 결과
특수문자를 제거하고 도전해보니 확실히 점수가 더 높아지는 모습을 볼 수 있었습니다.
지난 순위에서 3계단 올라갔습니다.
특수문자 제거만으로도 더 높은 점수를 얻을 수 있었습니다.
형태소 분석기를 바꾸어보자 (Okt -> Mecab)
이번에는 형태소 분석기를 mecab으로 바꾸어 토큰화 하여 학습하여 비교해보고자 했습니다.
mecab으로 토큰화하니 최대길이가 469 였습니다.
1. epoch 5 / batch_size 32 (Google Colab -TPU)
model8 = Sequential()
model8.add(Embedding(max_words, 100))
model8.add(LSTM(128))
model8.add(Dense(2, activation='sigmoid'))
model8.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history8 = model8.fit(X_train, y_train, epochs=5, batch_size=32, validation_split=0.1)| epoch | 5 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
2. epoch 3 / batch_size 32 (Google Colab -TPU)
model9 = Sequential()
model9.add(Embedding(max_words, 100))
model9.add(LSTM(128))
model9.add(Dense(2, activation='sigmoid'))
model9.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history9 = model9.fit(X_train, y_train, epochs=3, batch_size=32, validation_split=0.1)| epoch | 2 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
3. epoch 2 / batch_size 32 (Google Colab -TPU)
model10 = Sequential()
model10.add(Embedding(max_words, 100))
model10.add(LSTM(128))
model10.add(Dense(2, activation='sigmoid'))
model10.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history10 = model10.fit(X_train, y_train, epochs=2, batch_size=32, validation_split=0.1)| epoch | 2 | batch_size | 32 |
| optimizer | adam | validation_split | 0.1 |
세번째 제출
세번째 제출은 위에서 Mecab을 활용하여 해봤던 다양한 시도 중 3번째 시도했던 결과를 제출하였습니다.
세번째 제출 결과
| 순위 | 점수 | epoch / batch | optimizer | val_split | train_data | 특수문자제거 | colab | ||
| 1 | |||||||||
| 2 | 0.972980365 | 2 / 32 | adam | 0.1 | model_kb_dacon02_trainset.csv | O | TPU | Mecab | 9 |
| 3 | 0.97262973 | 5 / 32 | adam | 0.1 | |||||
| 4 | |||||||||
| 5 | 0.96873422 | 5 / 32 | adam | 0.1 | model_kb_dacon01_trainset.csv | X | GPU | Okt | 6 |
| 6 | 0.96549088 | 5 / 32 | rmsprop | X | model_kb_dacon01_trainset.csv | X | TPU | Okt | 2 |
| 7 | 0.9608906 | 5 / 32 | adam | X | model_kb_dacon01_trainset.csv | X | TPU | Okt | 3 |
| 8 | 0.95197054 | 5 / 32 | adam | 0.1 | model_kb_dacon01_trainset.csv | X | TPU | Mecab | 5 |
| 9 | 0.701388499 | 3 / 32 | adam | X | model_kb_dacon01_trainset.cs | X | GPU | ELMo | 7 |
도전 3일차! 3계단 올라간 25등에 머물렀습니다.
아쉬운 점은 하루에 세번밖에 제출을 할 수 없어 어떠한 파라미터가 최적인지 알 수 없는 것이 조금 아쉬웠습니다.
앞으로 여러 하이퍼 파라미터를 수정하면서 계속 발전시켜나가고자 합니다.
'DACON > KB 금융문자 분석 경진대회' 카테고리의 다른 글
| DACON 금융문자분석 공모전 - 도전 6일차 (8) | 2019.12.19 |
|---|---|
| DACON 금융문자분석 공모전 - 도전 5일차 (0) | 2019.12.18 |
| DACON 금융문자분석 공모전 - 도전 4일차 (0) | 2019.12.17 |
| DACON 금융문자분석 공모전 - 도전 2일차 (0) | 2019.12.15 |
| DACON 금융문자분석 공모전 - 도전 1일차 (4) | 2019.12.14 |



