
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Docker
- 더현대서울 맛집
- 코로나19
- leetcode
- github
- 자연어처리
- Real or Not? NLP with Disaster Tweets
- hackerrank
- 맥북
- gs25
- ubuntu
- programmers
- SW Expert Academy
- Git
- 캐치카페
- dacon
- 데이콘
- 금융문자분석경진대회
- 백준
- Baekjoon
- Kaggle
- PYTHON
- 프로그래머스 파이썬
- 우분투
- 파이썬
- 편스토랑
- 프로그래머스
- AI 경진대회
- 편스토랑 우승상품
- ChatGPT
Archives
- Today
- Total
솜씨좋은장씨
[DACON] 소설 작가 분류 AI 경진대회 8일차! 본문
728x90
반응형

소설 작가 분류 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
대회 커버가 바뀌어 뭔가 새로운 대회를 참가하는 것 같은 느낌의 도전 8일차 입니다.
먼저 fasttext로 결과를 도출해보고자 열심히 시도해보았으나 제 시간 내에 validation_loss 값을 0.78 아래로
떨어지는 것을 확인하지 못하여 이번에도 아쉽지만 7일차에서 조금씩만 변형하여 도전해보았습니다.
PorterStemmer로 어간추출 후 WordNetLemmatizer로 표제어 추출을 하여 나온 데이터를 바탕으로
시도해보았습니다.
train_dataset = pd.read_csv("./train.csv")
test_dataset = pd.read_csv("./test_x.csv")from nltk.corpus import stopwords
def alpha_num(text):
return re.sub(r"[^A-Za-z0-9\']", ' ', text)
stopwords_list = [ "a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as",
"at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "will",
"did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has",
"have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself",
"his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself",
"let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours",
"ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that",
"that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll",
"they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll",
"we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom",
"why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
stopwords_list = stopwords_list + stopwords.words('english')
from tqdm import tqdm
import re
def get_clean_text_list(data_df):
plain_text_list = list(data_df['text'])
clear_text_list = []
for i in tqdm(range(len(plain_text_list))):
plain_text = plain_text_list[i].lower()
plain_text = alpha_num(plain_text)
plain_split = plain_text.split()
plain_split = [word.strip() for word in plain_split if word.strip() not in stopwords_list]
clear_text = " ".join(plain_split).replace("'", "")
clear_text_list.append(clear_text)
return clear_text_list
train_dataset['clear_text'] = get_clean_text_list(train_dataset)
test_dataset['clear_text'] = get_clean_text_list(test_dataset)from nltk.tokenize import word_tokenize
# from nltk.stem.lancaster import LancasterStemmer
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
import re
from tqdm import tqdm
X_train = []
train_clear_text = list(train_dataset['clear_text'])
for i in tqdm(range(len(train_clear_text))):
temp = word_tokenize(train_clear_text[i])
temp = [stemmer.stem(word) for word in temp]
temp = [lemmatizer.lemmatize(word) for word in temp]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)
X_train[:3]
X_test = []
test_clear_text = list(test_dataset['clear_text'])
for i in tqdm(range(len(test_clear_text))):
temp = word_tokenize(test_clear_text[i])
temp = [stemmer.stem(word) for word in temp]
temp = [lemmatizer.lemmatize(word) for word in temp]
temp = [word for word in temp if len(word) > 1]
X_test.append(temp)
X_test[:3]word_list = []
for i in tqdm(range(len(X_train))):
for j in range(len(X_train[i])):
word_list.append(X_train[i][j])
len(list(set(word_list)))16295어간추출 후 표제어 추출을 진행해서 그런지 유니크한 단어의 수가 확실히 많이 줄었습니다.
import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()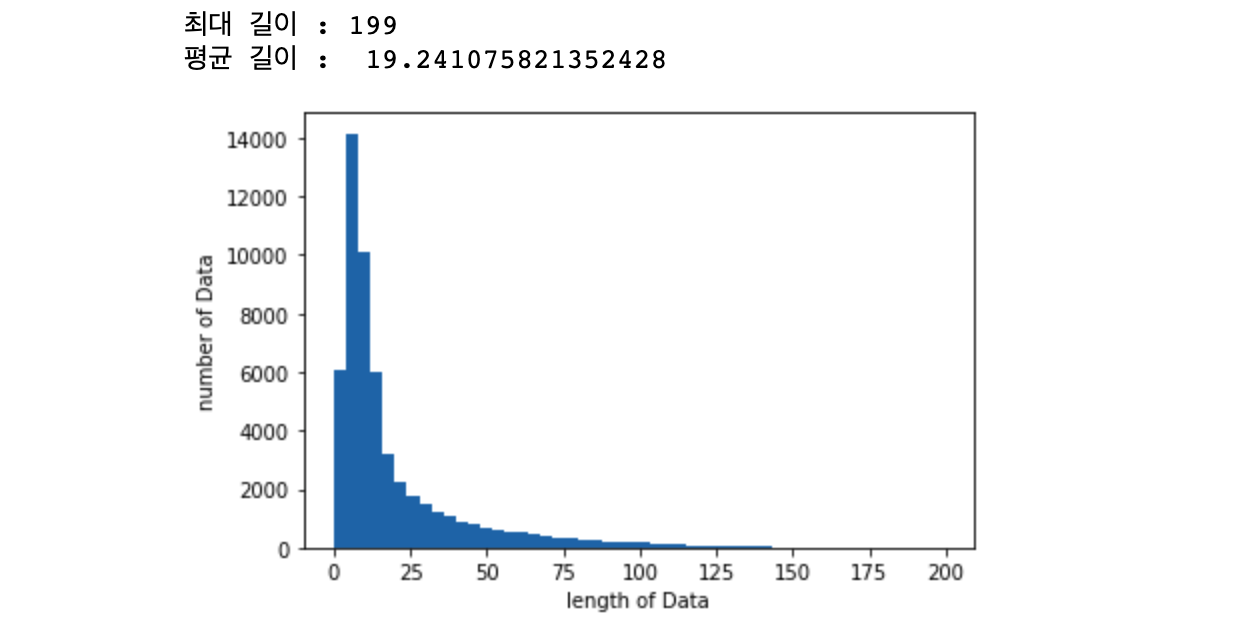
import numpy as np
y_train = np.array([x for x in train_dataset['author']])#파라미터 설정
vocab_size = 16295
embedding_dim = 128
max_length = 200
padding_type='post'위에서 얻은 값들을 바탕으로 파라미터를 정해줍니다.
from keras_preprocessing.text import Tokenizer
#tokenizer에 fit
tokenizer = Tokenizer(num_words = vocab_size)#, oov_token=oov_tok)
tokenizer.fit_on_texts(X_train)
word_index = tokenizer.word_index
from keras_preprocessing.sequence import pad_sequences
#데이터를 sequence로 변환해주고 padding 해줍니다.
train_sequences = tokenizer.texts_to_sequences(X_train)
train_padded = pad_sequences(train_sequences, padding=padding_type, maxlen=max_length)
test_sequences = tokenizer.texts_to_sequences(X_test)
test_padded = pad_sequences(test_sequences, padding=padding_type, maxlen=max_length)
import tensorflow as tf
from keras.callbacks import ModelCheckpoint
import os
MODEL_SAVE_FOLDER_PATH = './model08_20/'
if not os.path.exists(MODEL_SAVE_FOLDER_PATH):
os.mkdir(MODEL_SAVE_FOLDER_PATH)
model_path = MODEL_SAVE_FOLDER_PATH + '{epoch:02d}-{val_loss:.4f}.hdf5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss',
verbose=1, save_best_only=True)
#가벼운 NLP모델 생성
model42 = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(5, activation='softmax')
])
# compile model
model42.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# model summary
print(model42.summary())
# fit model
num_epochs = 30
history42 = model42.fit(train_padded, y_train,
epochs=num_epochs, batch_size=256,
validation_split=0.1, callbacks=[cb_checkpoint])Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 200, 128) 2602752
_________________________________________________________________
global_average_pooling1d (Gl (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 24) 3096
_________________________________________________________________
dropout (Dropout) (None, 24) 0
_________________________________________________________________
dense_1 (Dense) (None, 5) 125
=================================================================
Total params: 2,605,973
Trainable params: 2,605,973
Non-trainable params: 0
_________________________________________________________________
None
Train on 49391 samples, validate on 5488 samples
Epoch 1/30
48896/49391 [============================>.] - ETA: 0s - loss: 1.5614 - accuracy: 0.2766
Epoch 00001: val_loss improved from inf to 1.54436, saving model to ./model08_20/01-1.5444.hdf5
49391/49391 [==============================] - 6s 114us/sample - loss: 1.5610 - accuracy: 0.2769 - val_loss: 1.5444 - val_accuracy: 0.2580
...
Epoch 12/30
48896/49391 [============================>.] - ETA: 0s - loss: 0.5597 - accuracy: 0.7955
Epoch 00012: val_loss improved from 0.69994 to 0.68315, saving model to ./model08_20/12-0.6831.hdf5
49391/49391 [==============================] - 4s 80us/sample - loss: 0.5593 - accuracy: 0.7956 - val_loss: 0.6831 - val_accuracy: 0.7476
Epoch 13/30
48896/49391 [============================>.] - ETA: 0s - loss: 0.5355 - accuracy: 0.8040
Epoch 00013: val_loss did not improve from 0.68315
49391/49391 [==============================] - 4s 84us/sample - loss: 0.5360 - accuracy: 0.8037 - val_loss: 0.6873 - val_accuracy: 0.7442
Epoch 14/30
48640/49391 [============================>.] - ETA: 0s - loss: 0.5199 - accuracy: 0.8099
Epoch 00014: val_loss improved from 0.68315 to 0.67998, saving model to ./model08_20/14-0.6800.hdf5
49391/49391 [==============================] - 4s 90us/sample - loss: 0.5199 - accuracy: 0.8097 - val_loss: 0.6800 - val_accuracy: 0.7509
...validation loss를 기준으로 가장 학습이 잘 된것으로 보이는 체크포인트를 활용하여 결과를 도출하고 제출해보았습니다.
결과 도출
from tensorflow.keras.models import load_model
best_model_path = "./model08_20/14-0.6800.hdf5"
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_22.csv', index = False, encoding = 'utf-8')best_model_path = './model08_20/12-0.6831.hdf5'
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_23.csv', index = False, encoding = 'utf-8')best_model_path = './model08_20/12-0.6831.hdf5'
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_24.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

여기서 두번째에 3.249 점이 나온이유는 전처리 방식을 다른 방식으로 했던 데이터를 모델에 넣고 예측한 것을 모르고
제출하여 저렇게 나왔습니다.
결과는 0.4216334597 점으로 다시 최고기록을 세웠습니다.
하지만 아직 일부의 데이터만을 바탕으로 낸 점수에다가 베이스라인에서 많이 벗어나지 못하여 많이 아쉽습니다.
아직 시간은 남아있으니!
저의 도전은 계속 됩니다.
읽어주셔서 감사합니다.
'DACON > 소설 작가 분류 AI 경진대회' 카테고리의 다른 글
| [DACON] 소설 작가 분류 AI 경진대회 12일차! (0) | 2020.11.10 |
|---|---|
| [DACON] 소설 작가 분류 AI 경진대회 9일차! (0) | 2020.11.07 |
| [DACON] 소설 작가 분류 AI 경진대회 7일차! (0) | 2020.11.05 |
| [DACON] 소설 작가 분류 AI 경진대회 N일차! (0) | 2020.11.05 |
| [DACON] 소설 작가 분류 AI 경진대회 6일차! (0) | 2020.11.04 |
'DACON/소설 작가 분류 AI 경진대회' Related Articles
more




Comments