
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 맥북
- 백준
- ubuntu
- 프로그래머스 파이썬
- Git
- Baekjoon
- ChatGPT
- Docker
- Kaggle
- 편스토랑
- 캐치카페
- 우분투
- Real or Not? NLP with Disaster Tweets
- gs25
- github
- AI 경진대회
- 파이썬
- hackerrank
- SW Expert Academy
- 금융문자분석경진대회
- programmers
- 코로나19
- 편스토랑 우승상품
- PYTHON
- 데이콘
- 자연어처리
- dacon
- leetcode
- 프로그래머스
- 더현대서울 맛집
- Today
- Total
솜씨좋은장씨
[DACON] 소설 작가 분류 AI 경진대회 12일차! 본문

소설 작가 분류 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
11월 애플 이벤트를 기다리면서 진행한 12일차!
이번엔 베이스라인 코드에서 벗어나서! 새로운 전처리방식과 모델을 활용해보기로 했습니다.
그 과정에서 아래의 링크를 참고하였습니다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
이번 시도도 NIPA에서 지원해준 수시사용자 지원 V100 GPU 환경에서 실시하였습니다.
올 초 금융문자분석경진대회에서는 Colab을 활용하였어서 런타임에 엄청 고통 받았었는데
덕분에 정말 편하게 대회를 진행하는 것 같습니다.
지원해주셔서 정말 감사드립니다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
df_questions = pd.read_csv("./train.csv")
df_test = pd.read_csv("./test_x.csv")먼저! 데이터를 불러온 후에 각 author 에는 몇 개의 데이터가 존재하는지 확인해보았습니다.
tags = list(df_questions['author'])from collections import Counter
cnt = Counter(tags)Counter({3: 15063, 2: 11554, 1: 7222, 4: 7805, 0: 13235})1번과 4번의 작가가 상대적으로 적은 데이터를 가지고 있는 것을 알 수 있었습니다.
하지만! 오늘은 개수에 대한 정보는 활용하지 않았습니다.
일단 NLTK의 word_tokenize 함수가 각 문장을 어떻게 토큰화하는지 확인해보았습니다.
여기서 궁금했던 점은 과연 He's He'll What's 와 같이 '가 붙으면서 줄임말이 들어가는 문장들이
어떻게 토큰화가 되는지 여부였습니다.
import nltk
print(nltk.word_tokenize("What's your name?"))['What', "'s", 'your', 'name', '?']
몇 가지 문장으로 테스트를 진행해보니 What's 의 경우 What과 's 로 s에 ' 가 붙어있는 형태로 분리가 되는 것을
확인할 수 있었습니다.
그 다음 이번엔 word_tokenize로 토큰화를 했을때!
' 가 포함되어있는 토큰은 얼마나 들어있는지 확인해보았습니다.
from tqdm import tqdm
all_tokens = []
for i in tqdm(range(len(df_questions))):
tokens = nltk.word_tokenize(df_questions['text'].iloc[i])
for token in tokens:
all_tokens.append(token.lower())먼저 전체 토큰을 구한뒤에 그 토큰 속에서 찾아보았습니다.
unique_tokens = list(set(all_tokens))len(all_tokens), len(unique_tokens)(2863392, 43752)전체 토큰의 개수는 2,863,392개였고 중복된 토큰을 제외한 유니크한 토큰의 개수는 43,752개 였습니다.
check_tokens = [token for token in unique_tokens if "'" in token]
check_tokens이 유니크한 토큰 속에서 ' 를 포함한 토큰만 찾아보았습니다.
["'cut",
"'mad",
"'seized",
"'wherever",
"'just",
"'ah",
"l'eglise",
"'everything",
"'neither",
"'let",
"'prove",
"'whoever",
"'strangers",
"'would",
"'much",
"ford's.",
"'number",
"'ha",
"for't",
"'everybody",
"'harry",
"'certain",
"'worse",
"'often",
"'ow",
"'surely",
"'_it_",
"'though",
"'less",
"'be",
"'juries",
"'damme",
"'have",
"more'n",
"'takes",
"'fill",
"'those",
"'hark",
"'clever",
"'but",
"'because",
"han'sel",
"'thanks",
"'um",
"'from",
"'seeing",
...확인하다 보니 영어가 아닌 것 같은 단어들이 꽤 많이 존재했습니다.
정확히 어떤 부분에 포함되어있는 단어들인지 보기위하여
해당 단어들이 존재하는 전체 문장 text를 찾아주는 함수를 하나 만들었습니다.
def show_check_token_string(check_token, check_df):
for i in tqdm(range(len(check_df))):
if check_token in check_df['text'].iloc[i]:
print(check_df['text'].iloc[i])check_token = "d'eau"
show_check_token_string(check_token=check_token, check_df=df_questions)85%|████████▌ | 46815/54879 [00:00<00:00, 78084.81it/s]
"How rich they are and how good! And if one could only have _un doigt d'eau de vie_."
100%|██████████| 54879/54879 [00:00<00:00, 77715.12it/s]위 처럼 하나하나 찾아보았습니다.
나오는 단어들이 포함된 문장들이 어떤 언어인지 어떤 의미인지 구글 번역기를 통하여 확인해보았습니다.
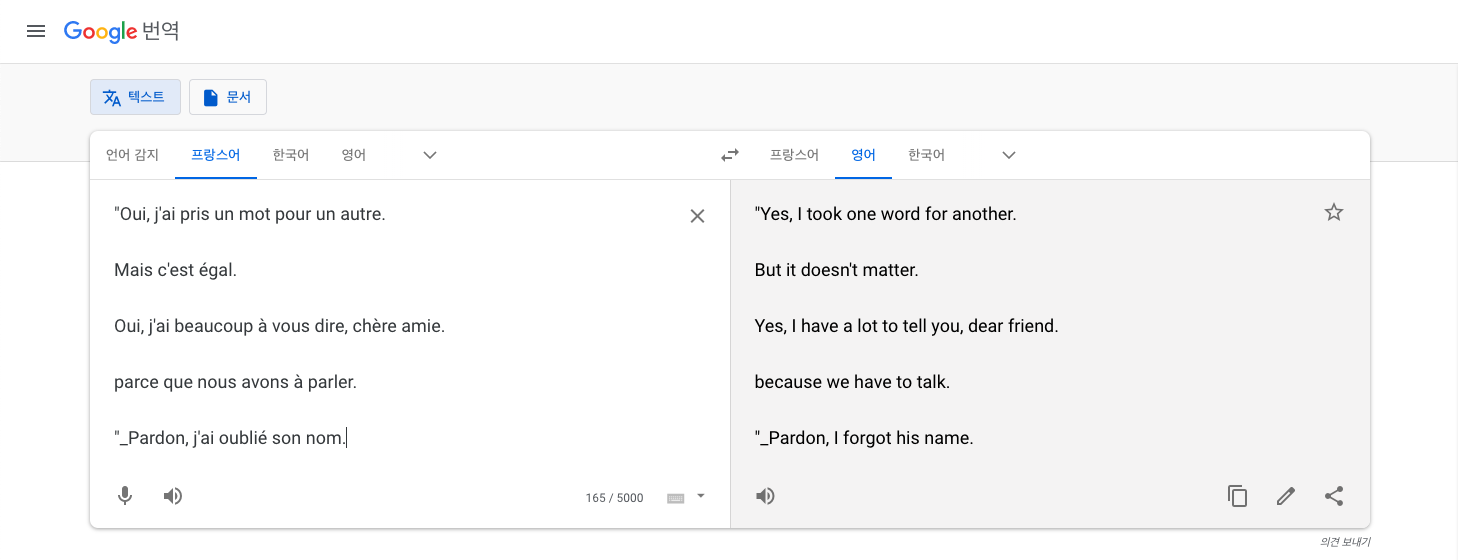
구글 번역기에 넣어보니 해당 문장들은 프랑스어였고 영어로 번역이 되었습니다.
이렇게 눈에 보이는 문장들을 구글번역기를 통해 번역해보았고 이를 바탕으로 번역 사전을 만들었습니다.
translate_user_dict = {"_un doigt d'eau de vie_.":"a finger of brandy",
"Oui, j'ai pris un mot pour un autre.":"Yes, I took one word for another.",
"Mais c'est égal.":"But it doesn't matter.",
"Oui, j'ai beaucoup à vous dire, chère amie.":"Yes, I have a lot to tell you, dear friend.",
"parce que nous avons à parler.":"because we have to talk.",
"Pardon, j'ai oublié son nom.":"Sorry, I forgot his name.",
"Il n'est pas du pays":"He is not from the country",
"quelque chose de bête et d'Allemand dans la physionomie.":"something stupid and German in the physiognomy.",
"C'est encore mieux":"It's even better",
"j'ai en tout quarante roubles mais":"I have forty rubles in all but",
"Grace à Dieu":"Thanks to God",
"c'est une si pauvre tête!":"that is such a poor head!",
"c'est un pauvre sire, tout de même":"he is a poor sire, all the same",
"et puis":"and then",
"c'est très":"it's very",
"c'est rassurant au plus haut degré.":"that is reassuring to the highest degree.",
"Elle me soupçonnera toute sa vie":"She will suspect me all her life",
"c'est égal":"is equal",
"L'Evangile... voyez-vous, désormais nous prêcherons ensemble":"The Gospel ... see, from now on we will preach together",
"c'est admis":"it is admitted",
"chère innocente":"dear innocent",
"et à cette chère ingrate":"and to this dear ungrateful",
"c'est un ange":"it's an angel",
"cette pauvre_ auntie":"this poor auntie",
"Cap'n":"captain",
"jawing--v'yages":"jawing - travels",
"a'terwards":"afterwards",
"m'clour":"to me",
"ma'am":"madam",
"Oh, hier il avait tant d'esprit":"Oh, yesterday he had so much wit"}일단 어느정도만 만들어보고 이를 바탕으로 번역 후 학습 했을때 좋은 결과가 나온다면 앞으로 더 구축할 생각이었습니다.
번역된 영어로 치환할 때 짧은 문장들이 먼저 치환되어 버리면 긴 문장에 중복으로 들어가있는 짧은 문장들이
먼저 영어로 번역되어버려 긴 문장 번역본 치환이 의미가 없을 것 같아
긴 문장 부터 치환되도록 dictionary 키를 정렬하여 활용하였습니다.
keys = list(translate_user_dict.keys())
keys_with_length = [(key, len(key)) for key in keys][("_un doigt d'eau de vie_.", 24),
("Oui, j'ai pris un mot pour un autre.", 36),
("Mais c'est égal.", 16),
("Oui, j'ai beaucoup à vous dire, chère amie.", 43),
('parce que nous avons à parler.', 30),
("Pardon, j'ai oublié son nom.", 28),
("Il n'est pas du pays", 20),
("quelque chose de bête et d'Allemand dans la physionomie.", 56),
("C'est encore mieux", 18),
("j'ai en tout quarante roubles mais", 34),
('Grace à Dieu', 12),
("c'est une si pauvre tête!", 25),
("c'est un pauvre sire, tout de même", 34),
('et puis', 7),
("c'est très", 10),
("c'est rassurant au plus haut degré.", 35),
('Elle me soupçonnera toute sa vie', 32),
("c'est égal", 10),
("L'Evangile... voyez-vous, désormais nous prêcherons ensemble", 60),
("c'est admis", 11),
('chère innocente', 15),
('et à cette chère ingrate', 24),
("c'est un ange", 13),
('cette pauvre_ auntie', 20),
("Cap'n", 5),
("jawing--v'yages", 15),
("a'terwards", 10),
("m'clour", 7),
("ma'am", 5),
("Oh, hier il avait tant d'esprit", 31)]
sorted_keys = sorted(keys_with_length, key=lambda x : -x[1])
sorted_keys = [ key[0] for key in sorted_keys ]["L'Evangile... voyez-vous, désormais nous prêcherons ensemble",
"quelque chose de bête et d'Allemand dans la physionomie.",
"Oui, j'ai beaucoup à vous dire, chère amie.",
"Oui, j'ai pris un mot pour un autre.",
"c'est rassurant au plus haut degré.",
"j'ai en tout quarante roubles mais",
"c'est un pauvre sire, tout de même",
'Elle me soupçonnera toute sa vie',
"Oh, hier il avait tant d'esprit",
'parce que nous avons à parler.',
"Pardon, j'ai oublié son nom.",
"c'est une si pauvre tête!",
"_un doigt d'eau de vie_.",
'et à cette chère ingrate',
"Il n'est pas du pays",
'cette pauvre_ auntie',
"C'est encore mieux",
"Mais c'est égal.",
'chère innocente',
"jawing--v'yages",
"c'est un ange",
'Grace à Dieu',
"c'est admis",
"c'est très",
"c'est égal",
"a'terwards",
'et puis',
"m'clour",
"Cap'n",
"ma'am"]각 키의 길이를 기준으로 내림차순 정렬하였습니다.
cnt = 0
text_list = list(df_questions['text'])
for i in tqdm(range(len(sorted_keys))):
for j in range(len(text_list)):
if sorted_keys[i] in text_list[j]:
text_list[j] = text_list[j].replace(sorted_keys[i], translate_user_dict[sorted_keys[i]])
cnt = cnt + 1
print("{}번 수정되었습니다.".format(cnt))이를 바탕으로 데이터를 수정하여 새로운 Column으로 넣어 주었습니다.
df_questions['new_text'] = text_listdf_questions.head()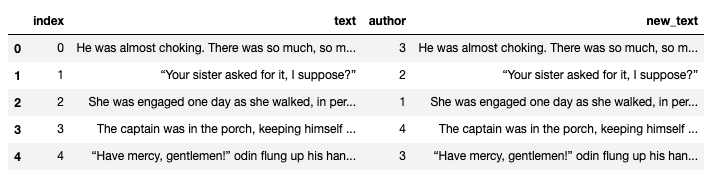
이 글을 쓰면서 코드를 다시 살펴보면서 깨달은 내용인데
위에서 열심히 전처리한 데이터를 하나도 활용하지 않았습니다.
왜냐하...면.....
바로 다음에 학습에 쓸 데이터를 아래처럼 다시 불러왔기 때문입니다. ^^
train_text = list(df_questions['text'])
test_text = list(df_test['text'])
갑자기 엄청 허탈했지만! 다음날 도전에서 더 좋은 결과를 얻을 수 있을거라는 기대감과 함께 계속 글을 적어보려 합니다.
각설하고!
이제 토큰화 후 불용어와 특수문자를 제거해 주었습니다.
맨 처음에 nltk를 활용한 토큰화가 어떻게되는지 확인한 이유가 바로 불용어 처리 방식을 변경해야할지 말지
고민하기 위해서 였습니다.
from nltk.corpus import stopwords
stopwords_list = [ "a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as",
"at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "will",
"did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has",
"have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself",
"his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself",
"let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours",
"ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that",
"that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll",
"they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll",
"we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom",
"why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
stopwords_list = stopwords_list + stopwords.words("english")
stopwords_list = list(set(stopwords_list))기존에 불용어를 구축하는 방법은 위와 같았습니다.
DACON에서 가져온 불용어와 nltk에서 제공하는 불용어를 합쳐놓은 형태를 활용하였습니다.
잘 보면 저 데이터에서는 what's, we've 와 같이 모든 불용어들에 ' 가 붙어서 존재했습니다.
그런데! 우리는 토큰화를 할때 nltk의 word_tokenize를 활용할 것이고
활용하여 분리된 토큰을 저 불용어 리스트와 비교하여 불용어를 제거하여야하는데!
nltk의 word_tokenize는
we've의 경우 we 와 've 로 두개의 토큰으로
that's 의 경우 that 과 's 로 두개의 토큰으로 분리하여 위의 불용어 리스트를 활용하면
제거를 한다고 해도 제대로 제거가 되지 않을 것이 틀림 없었습니다.
그래서!
불용어도 nltk의 word_tokenize를 활용하여 한 번 분리를 한 형태를 활용하기로 했습니다.
nltk_fit_stopwords = []
for stopword in stopwords_list:
tokens = nltk.word_tokenize(stopword)
for token in tokens:
nltk_fit_stopwords.append(token)
nltk_fit_stopwords = [token.lower() for token in nltk_fit_stopwords]
그리고 위에서 만든 불용어를 활용하여
특수문자와 불용어를 제거한 토큰을 남기는 함수를 만들었습니다.
import re
def alpha_num(text):
text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\“\”\'\"…》]', '', text)
return re.sub(r"[^A-Za-z0-9]", ' ', text)
def get_clean_tokens(text_list, stopwords_list):
clean_tokens = []
for i in tqdm(range(len(text_list))):
text = text_list[i].lower()
word_tokens = nltk.word_tokenize(text)
word_tokens = [ alpha_num(token) for token in word_tokens if token not in nltk_fit_stopwords]
word_tokens = [word for word in word_tokens if len(word) > 1]
clean_tokens.append(word_tokens)
return clean_tokenstrain_tokens = get_clean_tokens(train_text, stopwords_list)
text_tokens = get_clean_tokens(test_text, stopwords_list)이를 바탕으로 불용어와 특수문자를 제거해 주었습니다.
word_list = []
for i in tqdm(range(len(train_tokens))):
for j in range(len(train_tokens[i])):
word_list.append(train_tokens[i][j])
len(list(set(word_list)))41179학습데이터를 이루고 있는 유니크한 토큰은 총 41179개 였습니다.
이번엔 위의 위키독스 페이지에서 가져온 코드를 활용하여 여러 파라미터를 정해보았습니다.
from keras_preprocessing.text import Tokenizer
#tokenizer에 fit
tokenizer = Tokenizer()#, oov_token=oov_tok)
tokenizer.fit_on_texts(train_text)
word_index = tokenizer.word_indexthreshold = 2
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)단어 집합(vocabulary)의 크기 : 42330
등장 빈도가 1번 이하인 희귀 단어의 수: 16347
단어 집합에서 희귀 단어의 비율: 38.61800141743444
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 0.6867015891552651
# 전체 단어 개수 중 빈도수 2이하인 단어 개수는 제거.
# 0번 패딩 토큰과 1번 OOV 토큰을 고려하여 +2
vocab_size = total_cnt - rare_cnt + 2
print('단어 집합의 크기 :',vocab_size)단어 집합의 크기 : 25985
위의 과정을 거쳐 vocab_size 파라미터를 정하였습니다.
tokenizer = Tokenizer(vocab_size, oov_token = 'OOV')
tokenizer.fit_on_texts(train_text)
X_train = tokenizer.texts_to_sequences(train_text)
X_test = tokenizer.texts_to_sequences(test_text)import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()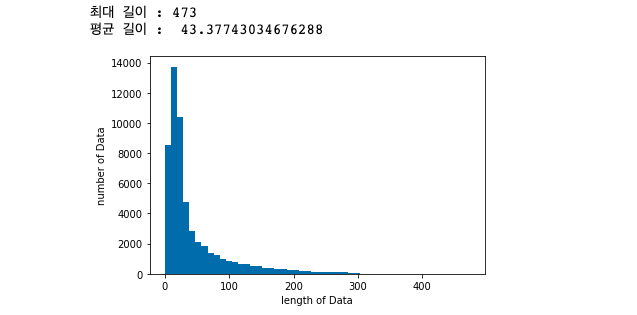
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if len(s) <= max_len:
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100))max_len = 350
below_threshold_len(max_len, X_train)전체 샘플 중 길이가 350 이하인 샘플의 비율: 99.97266714043623
위의 과정을 통해서 max_len의 길이를 구했습니다.
max_len을 350으로 설정하면 전체 데이터에서 약 99.97퍼센트의 데이터는 전체 데이터 정보를 가져갈 수 있습니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X_train = pad_sequences(X_train, maxlen = max_len)
X_test = pad_sequences(X_test, maxlen = max_len)위에서 얻은 max_len을 바탕으로 모든 데이터를 max_len의 길이로 맞추어 줍니다.
import numpy as np
y_train = np.array([x for x in df_questions['author']])라벨에 해당하는 author 값은 numpy의 array로 만들어 y_train에 넣어줍니다.
이제! Bi-LSTM을 활용하여 학습하고 결과를 도출해보았습니다.
import re
from tensorflow.keras.layers import Embedding, Dense, LSTM, Bidirectional
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import osmodel = Sequential()
model.add(Embedding(vocab_size, 100))
model.add(Bidirectional(LSTM(100)))
model.add(Dense(5, activation='softmax'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
MODEL_SAVE_FOLDER_PATH = './model12_1/'
if not os.path.exists(MODEL_SAVE_FOLDER_PATH):
os.mkdir(MODEL_SAVE_FOLDER_PATH)
model_path = MODEL_SAVE_FOLDER_PATH + '{epoch:02d}-{val_loss:.4f}.hdf5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss',
verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, cb_checkpoint], batch_size=256, validation_split=0.2)callback으로 early_stopping과 checkpoint 저장을 설정하였습니다.
Train on 43903 samples, validate on 10976 samples
Epoch 1/15
43776/43903 [============================>.] - ETA: 0s - loss: 1.2702 - acc: 0.5026
Epoch 00001: val_loss improved from inf to 0.98054, saving model to ./model12_1/01-0.9805.hdf5
43903/43903 [==============================] - 21s 475us/sample - loss: 1.2701 - acc: 0.5027 - val_loss: 0.9805 - val_acc: 0.6216
Epoch 2/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.8071 - acc: 0.7015
Epoch 00002: val_loss improved from 0.98054 to 0.80968, saving model to ./model12_1/02-0.8097.hdf5
43903/43903 [==============================] - 13s 303us/sample - loss: 0.8066 - acc: 0.7018 - val_loss: 0.8097 - val_acc: 0.6966
Epoch 3/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.6282 - acc: 0.7733
Epoch 00003: val_loss did not improve from 0.80968
43903/43903 [==============================] - 13s 298us/sample - loss: 0.6280 - acc: 0.7734 - val_loss: 0.8127 - val_acc: 0.7295
...
43776/43903 [============================>.] - ETA: 0s - loss: 0.3469 - acc: 0.8783
Epoch 00007: val_loss improved from 0.65865 to 0.62468, saving model to ./model12_1/07-0.6247.hdf5
43903/43903 [==============================] - 13s 300us/sample - loss: 0.3471 - acc: 0.8783 - val_loss: 0.6247 - val_acc: 0.7809
Epoch 8/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.3173 - acc: 0.8878
Epoch 00008: val_loss did not improve from 0.62468
43903/43903 [==============================] - 13s 299us/sample - loss: 0.3175 - acc: 0.8878 - val_loss: 0.6402 - val_acc: 0.7801
Epoch 9/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.2909 - acc: 0.8970
Epoch 00009: val_loss did not improve from 0.62468
43903/43903 [==============================] - 13s 295us/sample - loss: 0.2909 - acc: 0.8970 - val_loss: 0.6777 - val_acc: 0.7822
Epoch 10/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.2713 - acc: 0.9040
Epoch 00010: val_loss did not improve from 0.62468
43903/43903 [==============================] - 13s 296us/sample - loss: 0.2713 - acc: 0.9040 - val_loss: 0.6559 - val_acc: 0.7833
Epoch 11/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.2561 - acc: 0.9101
Epoch 00011: val_loss did not improve from 0.62468
43903/43903 [==============================] - 13s 298us/sample - loss: 0.2560 - acc: 0.9102 - val_loss: 0.7596 - val_acc: 0.7748
Epoch 00011: early stopping
여러 체크포인트 중 가장 validation loss 가 작은 7번째 epoch의 체크포인트를 활용하여
결과를 도출하고 제출해 보았습니다.
결과 도출
from tensorflow.keras.models import load_model
best_model_path = "./model12_1/07-0.6247.hdf5"
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(X_test)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_34.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

Validation loss의 값이 역대급으로 작아 기대했지만! 0.4605008145 로 최고 점수는 얻지 못하였습니다.
이번엔 optimizer 만 rmsprop에서 adam으로 바꾸어 시도해보았습니다.
model2 = Sequential()
model2.add(Embedding(vocab_size, 100))
model2.add(Bidirectional(LSTM(100)))
model2.add(Dense(5, activation='softmax'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
MODEL_SAVE_FOLDER_PATH = './model12_2/'
if not os.path.exists(MODEL_SAVE_FOLDER_PATH):
os.mkdir(MODEL_SAVE_FOLDER_PATH)
model_path = MODEL_SAVE_FOLDER_PATH + '{epoch:02d}-{val_loss:.4f}.hdf5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss',
verbose=1, save_best_only=True)
model2.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
history = model2.fit(X_train, y_train, epochs=15, callbacks=[es, cb_checkpoint], batch_size=256, validation_split=0.2)Train on 43903 samples, validate on 10976 samples
Epoch 1/15
43776/43903 [============================>.] - ETA: 0s - loss: 1.2474 - acc: 0.4925
Epoch 00001: val_loss improved from inf to 0.90998, saving model to ./model12_2/01-0.9100.hdf5
43903/43903 [==============================] - 17s 382us/sample - loss: 1.2464 - acc: 0.4930 - val_loss: 0.9100 - val_acc: 0.6569
Epoch 2/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.7308 - acc: 0.7294
Epoch 00002: val_loss improved from 0.90998 to 0.71131, saving model to ./model12_2/02-0.7113.hdf5
43903/43903 [==============================] - 13s 306us/sample - loss: 0.7303 - acc: 0.7297 - val_loss: 0.7113 - val_acc: 0.7405
Epoch 3/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.4936 - acc: 0.8278
Epoch 00003: val_loss improved from 0.71131 to 0.65170, saving model to ./model12_2/03-0.6517.hdf5
43903/43903 [==============================] - 13s 304us/sample - loss: 0.4934 - acc: 0.8278 - val_loss: 0.6517 - val_acc: 0.7674
Epoch 4/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.3631 - acc: 0.8763
Epoch 00004: val_loss did not improve from 0.65170
43903/43903 [==============================] - 14s 308us/sample - loss: 0.3632 - acc: 0.8762 - val_loss: 0.6528 - val_acc: 0.7730
Epoch 5/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.3039 - acc: 0.8958
Epoch 00005: val_loss did not improve from 0.65170
43903/43903 [==============================] - 13s 306us/sample - loss: 0.3038 - acc: 0.8958 - val_loss: 0.6841 - val_acc: 0.7707
Epoch 6/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.2524 - acc: 0.9130
Epoch 00006: val_loss did not improve from 0.65170
43903/43903 [==============================] - 13s 307us/sample - loss: 0.2523 - acc: 0.9130 - val_loss: 0.7364 - val_acc: 0.7652
Epoch 7/15
43776/43903 [============================>.] - ETA: 0s - loss: 0.2353 - acc: 0.9193
Epoch 00007: val_loss did not improve from 0.65170
43903/43903 [==============================] - 14s 308us/sample - loss: 0.2351 - acc: 0.9194 - val_loss: 0.7754 - val_acc: 0.7685
Epoch 00007: early stopping여기서 세번째 epoch의 checkpoint를 불러와 결과를 도출하고 제출해보았습니다.
결과 도출
from tensorflow.keras.models import load_model
best_model_path = "./model12_2/03-0.6517.hdf5"
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(X_test)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_35.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

음.... 일부 데이터를 활용하여 채점을 하여 그런것인지 아니면 학습이 덜되었거나
오버피팅이 되었는지 잘 모르겠지만 일단 더 좋지 않은 결과가 나왔습니다.
12일차의 시간이 얼마 남지 않아 이번에는 새롭게 바꾼 전처리 방식은 기존 베이스라인 코드에서 얼마나 성능이
좋아질까? 라는 생각이 들어 시도해보았습니다.
( 사실 데이터를 원본을 사용하여 불용어 처리 방식이 바뀌었다는 것 이외에는 거의 의미가 없었지만... )
import tensorflow as tf
model5 = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 100, input_length=max_len),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(5, activation='softmax')
])
model5.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
MODEL_SAVE_FOLDER_PATH = './model12_5/'
if not os.path.exists(MODEL_SAVE_FOLDER_PATH):
os.mkdir(MODEL_SAVE_FOLDER_PATH)
model_path = MODEL_SAVE_FOLDER_PATH + '{epoch:02d}-{val_loss:.4f}.hdf5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss',
verbose=1, save_best_only=True)
model5.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
history = model5.fit(X_train, y_train, epochs=30, callbacks=[es, cb_checkpoint], batch_size=256, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/30
49152/49391 [============================>.] - ETA: 0s - loss: 1.5590 - acc: 0.2782
Epoch 00001: val_loss improved from inf to 1.53372, saving model to ./model12_5/01-1.5337.hdf5
49391/49391 [==============================] - 6s 117us/sample - loss: 1.5588 - acc: 0.2787 - val_loss: 1.5337 - val_acc: 0.3253
Epoch 2/30
48896/49391 [============================>.] - ETA: 0s - loss: 1.4217 - acc: 0.4329
Epoch 00002: val_loss improved from 1.53372 to 1.30431, saving model to ./model12_5/02-1.3043.hdf5
49391/49391 [==============================] - 5s 110us/sample - loss: 1.4204 - acc: 0.4338 - val_loss: 1.3043 - val_acc: 0.5058
...
Epoch 25/30
49152/49391 [============================>.] - ETA: 0s - loss: 0.3197 - acc: 0.8934
Epoch 00025: val_loss did not improve from 0.62758
49391/49391 [==============================] - 6s 119us/sample - loss: 0.3200 - acc: 0.8932 - val_loss: 0.6430 - val_acc: 0.7777
Epoch 26/30
48896/49391 [============================>.] - ETA: 0s - loss: 0.3074 - acc: 0.8966
Epoch 00026: val_loss did not improve from 0.62758
49391/49391 [==============================] - 5s 106us/sample - loss: 0.3076 - acc: 0.8965 - val_loss: 0.6567 - val_acc: 0.7702
Epoch 00026: early stopping이번엔 5번째 epoch의 checkpoint를 활용하여 결과를 도출하고 제출해보았습니다.
결과 도출
from tensorflow.keras.models import load_model
best_model_path = "./model12_5/19-0.6340.hdf5"
best_model = load_model(best_model_path)
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = best_model.predict_proba(X_test)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_36.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

마지막도 아쉬운 점수로 마무리 했습니다.
이제 13일차는 아까 열심히 전처리한 데이터를 활용하여 결과를 도출해보고 비교해보며
애플 11월 이벤트를 기다려보고자 합니다.
읽어주셔서 감사합니다~
'DACON > 소설 작가 분류 AI 경진대회' 카테고리의 다른 글
| [DACON] 소설 작가 분류 AI 경진대회 16일차! (0) | 2020.11.15 |
|---|---|
| [DACON] 소설 작가 분류 AI 경진대회 13일차! (0) | 2020.11.11 |
| [DACON] 소설 작가 분류 AI 경진대회 9일차! (0) | 2020.11.07 |
| [DACON] 소설 작가 분류 AI 경진대회 8일차! (0) | 2020.11.06 |
| [DACON] 소설 작가 분류 AI 경진대회 7일차! (0) | 2020.11.05 |



