
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Docker
- 코로나19
- 프로그래머스
- ChatGPT
- 금융문자분석경진대회
- 자연어처리
- PYTHON
- 맥북
- dacon
- gs25
- 우분투
- AI 경진대회
- hackerrank
- 더현대서울 맛집
- github
- 프로그래머스 파이썬
- Kaggle
- 데이콘
- Real or Not? NLP with Disaster Tweets
- Git
- leetcode
- Baekjoon
- 편스토랑 우승상품
- 편스토랑
- SW Expert Academy
- programmers
- ubuntu
- 캐치카페
- 파이썬
- 백준
- Today
- Total
솜씨좋은장씨
한국인공지능아카데미 인공지능 실용교육 BERT 수강 후기! - 1 (1일차부터 3일차까지!) 본문

평소와 같이 쉬면서 평화롭게 페이스북을 하던 중 한국인공지능아카데미에서 BERT에 관련된 교육을 한다고하여
평소에 말로만 이야기하고 한번도 사용해보지는 못한 BERT에 대해서 배울 수 있는 좋은 기회라고 생각하여 신청해보았습니다.
그리고 제가 지난 한 달 동안 도전해보았던 DACON 금융문자분석 경진대회에서 7위로 장려상을 수상하신
통계청의 김웅곤님이 교육을 하신다고 하여 노하우도 들어보고 싶고 현재 도전하고 있는
프로그래머스의 Dev-Matching 도전에도 도움이 될 만한 정보를 얻을 수 있을까 하여 더더욱 수강하고싶었습니다.

신청 후! 교육대상 확정 메일이 오게되었고 교육을 들을 수 있었습니다.
교육은 공덕에 있는 서울창업허브 9층에 있는 세미나실에서 진행되었습니다.

서울 창업허브는 말로만 듣고 처음 가보는 곳이었는데 신종 코로나 바이러스에도 불구하고
정말 많은 사람들이 공부도하고 정보도 공유하는 활발한 곳이었습니다.
강의자료는 아래의 김웅곤님의 GitHub에서 다운 받거나 Google Colab으로 이동하여 바로 사용할 수 있게 준비해주셨습니다.
kimwoonggon/publicservant_AI
Contribute to kimwoonggon/publicservant_AI development by creating an account on GitHub.
github.com
교육 1일차
첫 날은 기본적인 자연어처리에 대한 기본적인 내용에 대해서 이론적으로 배우고
실제 IMDB DATASET과 뉴스 기사 데이터를 가지고 분류 실습을 해보았습니다.
IMDB 데이터를 가지고서는 dictionary 기반 토큰화 -> 임베딩 -> GRU 모델을 활용한 긍정/부정 이진분류를
뉴스 기사 데이터를 가지고서는 nltk를 활용한 토큰화 -> Glove 임베딩 -> 어텐션 모델을 활용한 다중분류를 실시해보았습니다.
첫날에는 평소 분류모델에 사용해보지 않았던 GRU모델과 어텐션 모델을 사용해 볼 수 있어 좋았습니다.
교육 2일차
두번째날은 강의의 메인주제였던 BERT를 Colab에서 케라스를 활용하여 쉽게 돌려보는 시간을 가졌습니다.
이 또한 김웅곤 강사님께서 사전에 GitHub에 실습코드와 설명이 담겨있는 유튜브 영상을 미리 준비해 두셨습니다.
먼저 Keras를 활용하여 구현한 BERT를 가지고 네이버 영화리뷰 감성분석을 실시해보았습니다.
google-research/bert
TensorFlow code and pre-trained models for BERT. Contribute to google-research/bert development by creating an account on GitHub.
github.com
google-research의 github에서 사전 학습된 bert를 다운로드 받아 구글드라이브에 업로드하여 사용하였습니다.
네이버 영화 리뷰 데이터 전처리를 하지않아도 감성분석 결과가 86% 이상이 나온다고 하였습니다.
저는 이 모델을 가지고 프로그래머스의 Dev-Matching에도 적용을 해보았습니다.
결과는 75%의 결과를 얻을 수 있었습니다.
약 2,000개의 학습데이터에 데이터의 특성이 한글과 프로그래밍 언어가 섞여 있는 질문의 형태여서
더 정확도를 높이는데 어려움이 있지않았나 생각이 들었습니다.
잠시 쉬었다가 그 뒤에는 위키백과의 내용과 답이 있는 데이터를 가지고 특정 질문에 대한 답을 구하는 SQuAD와
이를 한국어로 해보는 KorQuAD를 해보았습니다.
학습하지 않은 새로운 내용을 가지고 질문을해도 답변을 해주는 점이 정말 신기했습니다.
교육 3일차
세번째날은 2일차까지 배웠던 BERT를 활용하여 팀단위로 과제를 풀어보는 시간이었습니다.
시작 전 각자 본인의 전공, IT 개발경험, 본인의 관심분야에 대해서 자기소개를 하는 시간을 가지고 팀을 구성하는 시간을 가졌습니다.
대학교 컴퓨터공학과 학부생이면서 연구실에서 같이 공부하는 분들이 같이 신청해서 오신분,
현역 개발자로 근무하시다가 인공지능 분야 쪽으로도 자기계발을 하기 위해서 오신분들,
지속적으로 공부를 하시기위해서 한글과 컴퓨터 부사장 직에서 내려와 공부를 하고계신 분
그리고 멀티캠퍼스에서 자연어처리 C반을 같이 수료했던 분들과 같이
정말 다양한 분들이 BERT에 대해서 공부를 하기 위해서 모였다는 것을 알 수 있었습니다.
자기소개 내용과 희망하는 인원들로 팀을 구성하였고
Kaggle의
독설찾기대회
Toxic Comment Classification Challenge
Identify and classify toxic online comments
www.kaggle.com
SMS 스팸 분류 대회
SMS Spam Collection Dataset
Collection of SMS messages tagged as spam or legitimate
www.kaggle.com
이 두가지 중에 한가지를 2일차까지 배웠던 BERT를 활용하여 데이터를 가지고 한번 도전해보고 팀별로 간단하게 발표를 하는 시간을 가졌습니다.
이 중에 SMS 스팸 분류대회의 데이터를 가지고 BERT를 사용하여 테스트 해보았습니다.
또 기존에 기사분류모델, 금융문자분석경진대회에서 잘 사용했던 LSTM모델로도 테스트해보고 비교해보았습니다.
중간에 data_load하는 부분에서 오류가 났었는데 같은 팀이었던 팀원이 해결법을 찾았고
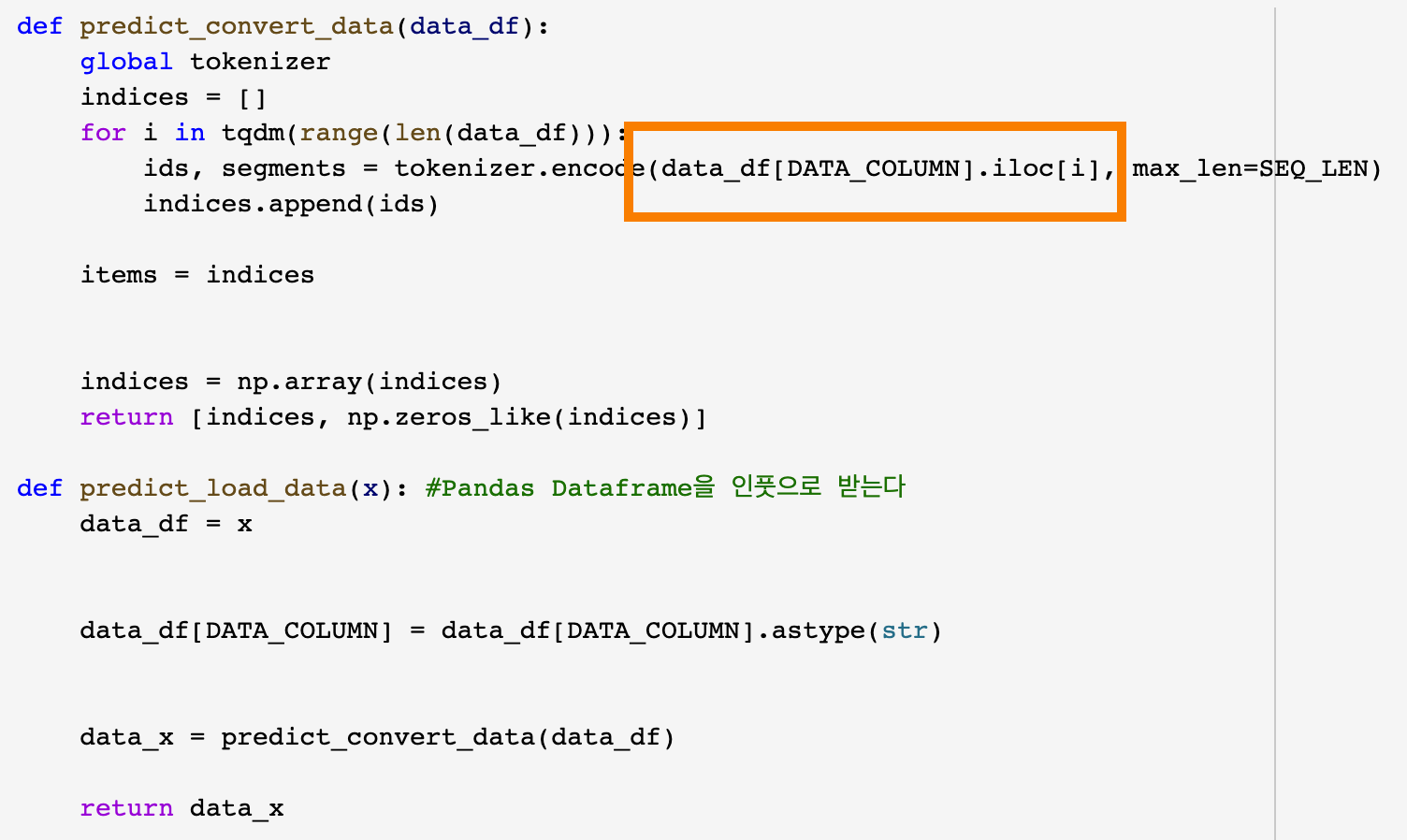
기존의 코드
data_df[DATA_COLUMN][i]에서 .iloc메소드를 활용하여
data_df[DATA_COLUMN].iloc[i]로 바꾸니 해결되었습니다.
SOMJANG/AI_Acadamy_BERT
Contribute to SOMJANG/AI_Acadamy_BERT development by creating an account on GitHub.
github.com
두 모델 모두 98%에 가까운 정확도를 보였습니다.
아직 BERT의 내부가 어떻게 구성되어있는지에 transformer가 어떻게 구성되어있는지 등에 대해서는 자세하게 모르지만
매번 말로만 듣던 BERT를 Keras를 활용하여 한번 실행해봤다는 것에 정말 큰 의미가 있었던 것 같습니다.
같이 스터디를 하고 있는 idEANS의 팀원들과 함께 논문을 읽어보며 더 공부해보고자 합니다.
내일부터 4일차, 5일차 2일간에는 각 팀의 아이디어를 가지고 팀프로젝트를 한다고하였습니다.
각 팀에서 가진 아이디어가 어떻게 구현되어 나올지 기대가 됩니다.
3일차 까지는 Dev-Matching 과제에 더 신경을 많이 썼지만 내일부터는 최대한 노력해서 좋은 결과를 내보고자 합니다.
읽어주셔서 감사합니다.
'일상 > 교육' 카테고리의 다른 글
| [캐치카페] 현직자와 함께하는 프로그래밍 2회차 후기 (0) | 2020.02.24 |
|---|---|
| 한국인공지능아카데미 인공지능 실용교육 오디오처리편 후기! (0) | 2020.02.21 |
| [캐치카페] 현직자와 함께하는 프로그래밍 1회차 후기 (2) | 2020.02.18 |
| 한국인공지능아카데미 인공지능 실용교육 BERT 수강 후기! - 2 (4일차/5일차!) (0) | 2020.02.07 |
| 멀티캠퍼스 혁신성장 청년인재양성 수료하다!(수료후기) - 신청/면접/교육/수료까지! (인공지능 자연어처리 기업데이터분석 C반) (52) | 2019.12.04 |



