
Notice
Recent Posts
Recent Comments
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 프로그래머스
- Docker
- Baekjoon
- 자연어처리
- 파이썬
- 편스토랑 우승상품
- 코로나19
- Real or Not? NLP with Disaster Tweets
- SW Expert Academy
- AI 경진대회
- 캐치카페
- Git
- 금융문자분석경진대회
- ubuntu
- github
- gs25
- dacon
- 더현대서울 맛집
- ChatGPT
- 맥북
- Kaggle
- 프로그래머스 파이썬
- 편스토랑
- PYTHON
- programmers
- 우분투
- 백준
- 데이콘
- leetcode
- hackerrank
Archives
- Today
- Total
솜씨좋은장씨
[캐치카페] 현직자와 함께하는 프로그래밍 3회차 과제 도전기 - 1 (API 데이터 자동으로 추가하기) 본문
728x90
반응형


먼저 영화 데이터를 추가하기위해서
실제 네이버 영화에서 데이터를 크롤링해서 추가해주었습니다.
현재상영작 : 네이버 영화
상영 중 영화의 예매율/평점/좋아요 순 정보 제공.
movie.naver.com
크롤링 해와야하는 데이터는 다음과 같습니다.

import requests
from bs4 import BeautifulSoup
url = "https://movie.naver.com/movie/running/current.nhn"
url_req = requests.get(url)
url_soup = BeautifulSoup(url_req.text)
movie_link_list = []
link_soup = url_soup.select("div.thumb > a")
for link in link_soup:
link = link.get('href')
movie_link_list.append('https://movie.naver.com' + link)
movie_link_list
soup = url_soup.select("div.star_t1.b_star > span")
advanceRate = []
for i in range(len(soup)):
if i % 2 == 0:
advanceRate.append(float(soup[i].text))
for i in range(6):
advanceRate.append(0.00)import pandas as pd
import random
from tqdm import tqdm
def getMovieDataFromNaverMovie(movie_link_list):
titles = []
posterUrls = []
screeningStatuss = []
advanceRates = []
advancdRateRank = []
visitorRatings = []
expertRatings = []
plots = []
movie_genres = []
runtimes = []
casts = []
releaseds = []
mv_directors = []
mv_actors = []
for i in tqdm(range(len(movie_link_list))):
try:
url_req = requests.get(movie_link_list[i])
url_soup = BeautifulSoup(url_req.text)
title = url_soup.select('div.mv_info > h3.h_movie > a')[0].text
genres = []
genre_soup = url_soup.select('dl.info_spec > dd > p > span:nth-child(1)> a')
for genre in genre_soup:
genres.append(genre.text)
runtime = int(re.sub("[^0-9]", '' , url_soup.select('dl.info_spec > dd > p > span:nth-child(3)')[0].text))
try:
release_date = url_soup.select('dl.info_spec > dd > p > span:nth-child(4) > a')[0].text + url_soup.select('dl.info_spec > dd > p > span:nth-child(4) > a')[1].text.replace(".", "-")
except:
release_date = '2020-01-30'
director = url_soup.select('dl.info_spec > dd:nth-child(4) > p > a')
directors = []
for direct in director:
directors.append(direct.text)
actors = []
actor_soup = url_soup.select('dl.info_spec > dd:nth-child(6) > p > a')
for actor in actor_soup:
actors.append(actor.text)
plot_soup = url_soup.select('p.con_tx')
plot = plot_soup[0].text.replace("\r", "").replace("\xa0", "").replace('"', '').replace("'", "")
plot = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]', '', plot)
star_score = url_soup.select('div.star_score > em')
if len(star_score) == 15:
star_score_1 = float(star_score[8].text)
star_score_2 = float(star_score[9].text)
elif len(star_score) == 22:
star_score_1 = float(star_score[16].text)
star_score_2 = float(star_score[17].text)
else:
star_score_1 = float(random.randint(5, 10))
star_score_2 = float(random.randint(5, 10))
movie_id = re.sub("[^0-9]", '', movie_link_list[i])
poster_url = "https://movie.naver.com/movie/bi/mi/photoViewPopup.nhn?movieCode="+ movie_id
poster_req = requests.get(poster_url)
poster_soup = BeautifulSoup(poster_req.text)
poster_link = poster_soup.select("img#targetImage")[0].get('src')
titles.append(title)
posterUrls.append(poster_link)
screeningStatuss.append("open")
advanceRates.append(advanceRate[i])
advancdRateRank.append(i+1)
visitorRatings.append(star_score_1)
expertRatings.append(star_score_2)
plots.append(plot)
movie_genres.append(genres)
runtimes.append(runtime)
casts.append(actors)
releaseds.append(release_date)
mv_directors.append(directors[0])
except:
print("error : ", i)
my_dict = {"title":titles, "posterUrl":posterUrls, "screeningStatus":screeningStatuss, "advanceRate":advanceRates, "advanceRateRank":advancdRateRank, "visitorRating":visitorRatings, "expertRatings":expertRatings, "plot":plots, "genres":movie_genres, "runtime":runtimes, "cast":casts, "release":releaseds, "director":mv_directors}
my_dataFrame = pd.DataFrame(my_dict)
return my_dataFramegetMovieDataFromNaverMovie(movie_link_list).to_csv("movie_data5.csv", index=False)
총 73개의 데이터만 크롤링 해왔습니다.
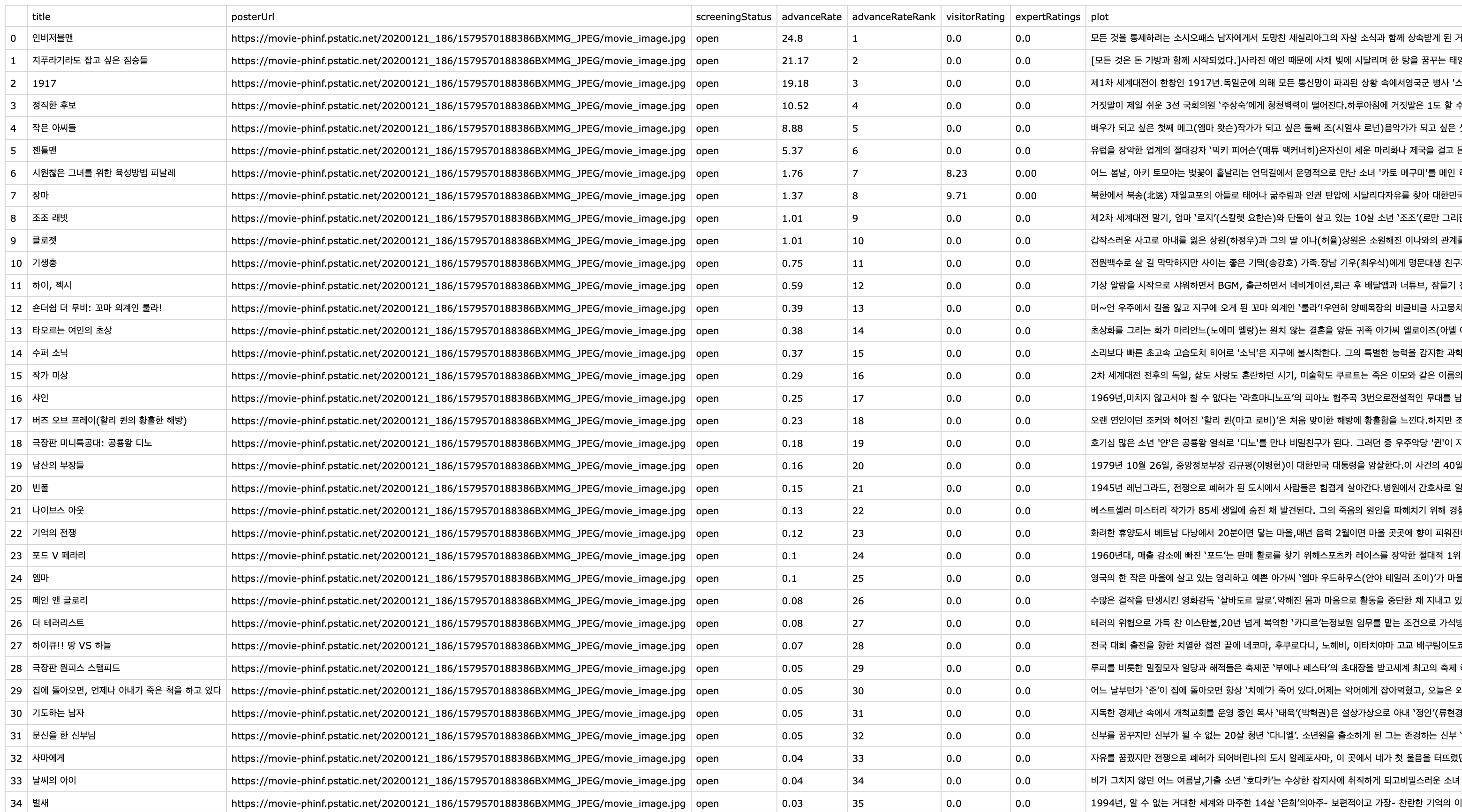
이제 이 데이터를 API 에 추가해야하는데 73개의 데이터를 일일이 손으로 추가하기에는 시간도 부족하고 힘도 많이 들어갑니다.
Selenium을 통해 자동화시켜 추가시켜줍니다.
movie_data = pd.read_csv("movie_data5.csv")import json
def makeJsonList(movie_data):
json_list = []
for i in tqdm(range(len(movie_data['title']))):
json_template = {
"title": list(movie_data['title'])[i],
"posterUrl": list(movie_data['posterUrl'])[i],
"screeningStatus": "open",
"advanceRate": list(movie_data['advanceRate'])[i],
"advanceRateRank": list(movie_data['advanceRateRank'])[i],
"visitorRating": list(movie_data['visitorRating'])[i],
"expertRating": list(movie_data['expertRatings'])[i],
"plot": list(movie_data['plot'])[i],
"genres": list(movie_data['genres'])[i],
"runtime": list(movie_data['runtime'])[i],
"cast": list(movie_data['cast'])[i],
"released": list(movie_data['release'])[i],
"director": list(movie_data['director'])[i]
}
json_data = str(json_template)
json_list.append(json_data.replace("'", '"').replace('"[', '[').replace(']"', "]"))
return json_listfrom selenium import webdriver as wd
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
for i in range(len(json_list)):
api_site_url = "http://54.180.149.147:8080/docs"
driver = wd.Chrome("./chromedriver")
driver.get(api_site_url)
time.sleep(2.0)
driver.execute_script("window.scrollTo(0, 1000);")
driver.find_element_by_css_selector("div#operations-movie_2팀-post_team_2_movie").click()
driver.find_element_by_css_selector(".btn.try-out__btn").click()
json_area = driver.find_element_by_css_selector(".body-param__text")
json_area.clear()
json_area.send_keys(json_list[i])
driver.find_element_by_css_selector(".btn.execute.opblock-control__btn").click()
json_area.clear()
driver.close()
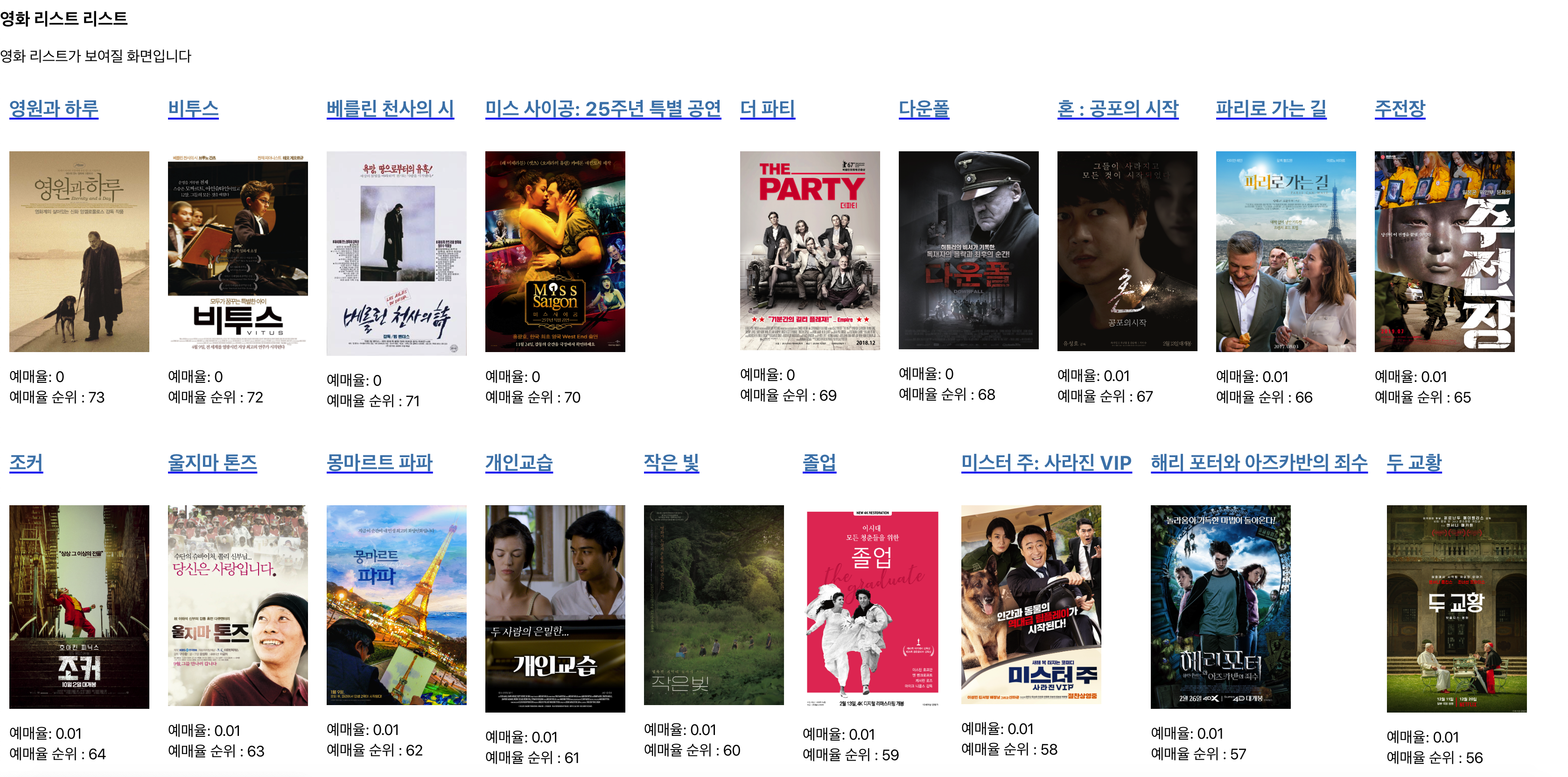
이상없이 잘 추가되어있는 것을 볼 수 있습니다.
오늘은 여기까지!
내일은 과제 1번을 해보고자 합니다.
'일상 > 교육' 카테고리의 다른 글
| [캐치카페] 현직자와 함께하는 프로그래밍 4회차 후기 (0) | 2020.03.04 |
|---|---|
| [캐치카페] 현직자와 함께하는 프로그래밍 3회차 과제 도전기 - 2 (영화 상세정보 페이지 꾸미기) (2) | 2020.03.03 |
| [캐치카페] 현직자와 함께하는 프로그래밍 3회차 후기 (0) | 2020.02.28 |
| [캐치카페] 현직자와 함께하는 프로그래밍 2회차 과제 도전기 (2) | 2020.02.28 |
| [캐치카페] 현직자와 함께하는 프로그래밍 2회차 후기 (0) | 2020.02.24 |
'일상/교육' Related Articles
more




Comments