
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- leetcode
- ChatGPT
- Docker
- 프로그래머스 파이썬
- PYTHON
- ubuntu
- hackerrank
- 편스토랑 우승상품
- github
- 데이콘
- 우분투
- 더현대서울 맛집
- 파이썬
- 프로그래머스
- Git
- 캐치카페
- 맥북
- Baekjoon
- gs25
- Kaggle
- programmers
- 금융문자분석경진대회
- dacon
- SW Expert Academy
- 코로나19
- 편스토랑
- Real or Not? NLP with Disaster Tweets
- 백준
- AI 경진대회
- 자연어처리
- Today
- Total
솜씨좋은장씨
음성합성 프로젝트 도전! - 01 새로운 시작! 본문
시작하게 된 계기
지난 10월 28일 네이버 DEVIEW를 다녀온 이후 음성 합성에 대해서 관심을 가지게 되었고
같이 발표를 들었던 누나 형들과 함께 우리도 음성합성을 한번 해보자! 라는 목표가 생겨 프로젝트를 시작하게 되었습니다.
제가 군 생활을 할 당시에는 필요한 안내방송이 있을경우 제가 직접 녹음을 하고 그 녹음 파일을 재생하는 방식으로 했었습니다.
제 개인적인 최종 목표는 가능하다면 언젠가
오픈소스를 활용하여 학습시킨 음성합성 모델을 가지고
제가 안내방송을 녹음하고 그 안내방송 음성을 재생하는 것으로 안내방송을 했던, 제가 근무했던 부대에 찾아가
그 모델을 활용하여 부대에서 필요한 안내방송을 만들어 직접 방송해보고 싶습니다.
네이버 DEVIEW 2019 - 1일차를 다녀와서!
10월 28일 코엑스에서 진행되었던 DEVIEW 2019를 다녀왔습니다. 1일차에 요즘 관심을 가지고 있는 자연어처리 분야와 음성합성관련 세션, 그리고 요즘 모델링을 하며 궁금했던 부분을 알려줄 것만 같은 세션이 있..
somjang.tistory.com
감정연기와 외국어가 가능한 인공지능 성우
발표자 : 이영근
deview.kr
데이터 전처리
현재는 학습을 시키기위한 데이터를 만들기위해 열심히 전처리를 하고 있습니다.
팀원 중 누나 한 분이 JTBC 손석희 앵커브리핑 음원을 쉬어가는 시간단위로 자른 음원파일을 만들었고
그 음성 하나하나를 Google API 중 Speech-To-Text를 해주는 API를 활용하여 각각의 음성파일마다 스크립트를 만들었습니다.
약 10만개의 파일이 만들어졌습니다.
Google API가 꽤 정확하게 음성을 텍스트로 변환해주었지만 자세히 들여다보면
"아버지는 딸을 볼 수 있지만"
이라고 말한 음성파일을 텍스트로 변환해 놓은 파일을 열어보면 딸을 달이라고 적어 둔 것을 볼 수 있습니다.

이러한 오류들을 수정하여 정제된 데이터를 만들기위해서
약 10만개의 데이터를 6명의 팀원들이 각각 16,000개 ~ 17,000개 씩 맡아서 수정을 시작했습니다.
이 글을 작성하고있는 현재까지 제가 완료한 양은 1,030개
남은 데이터는 15,882개!
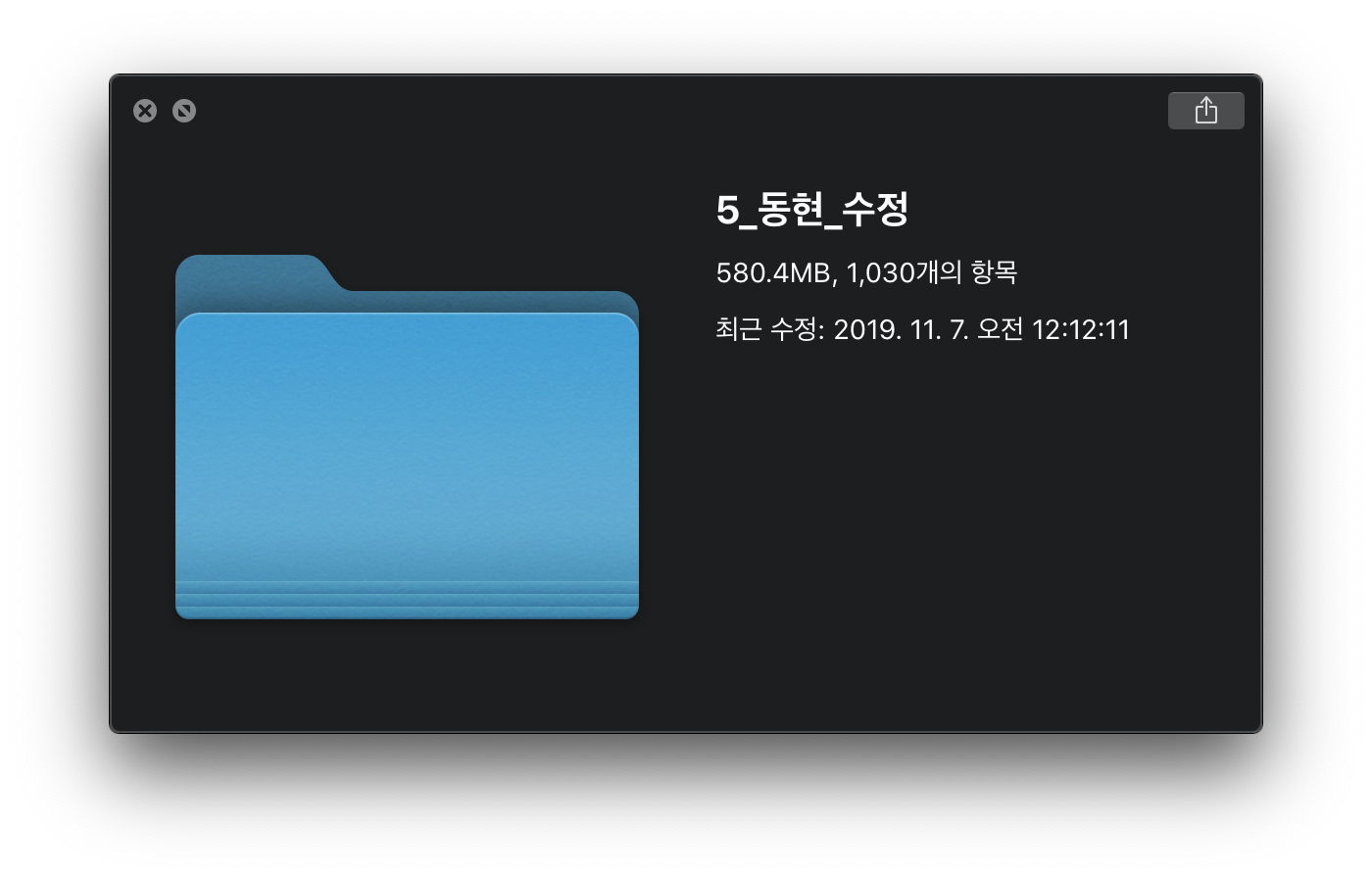
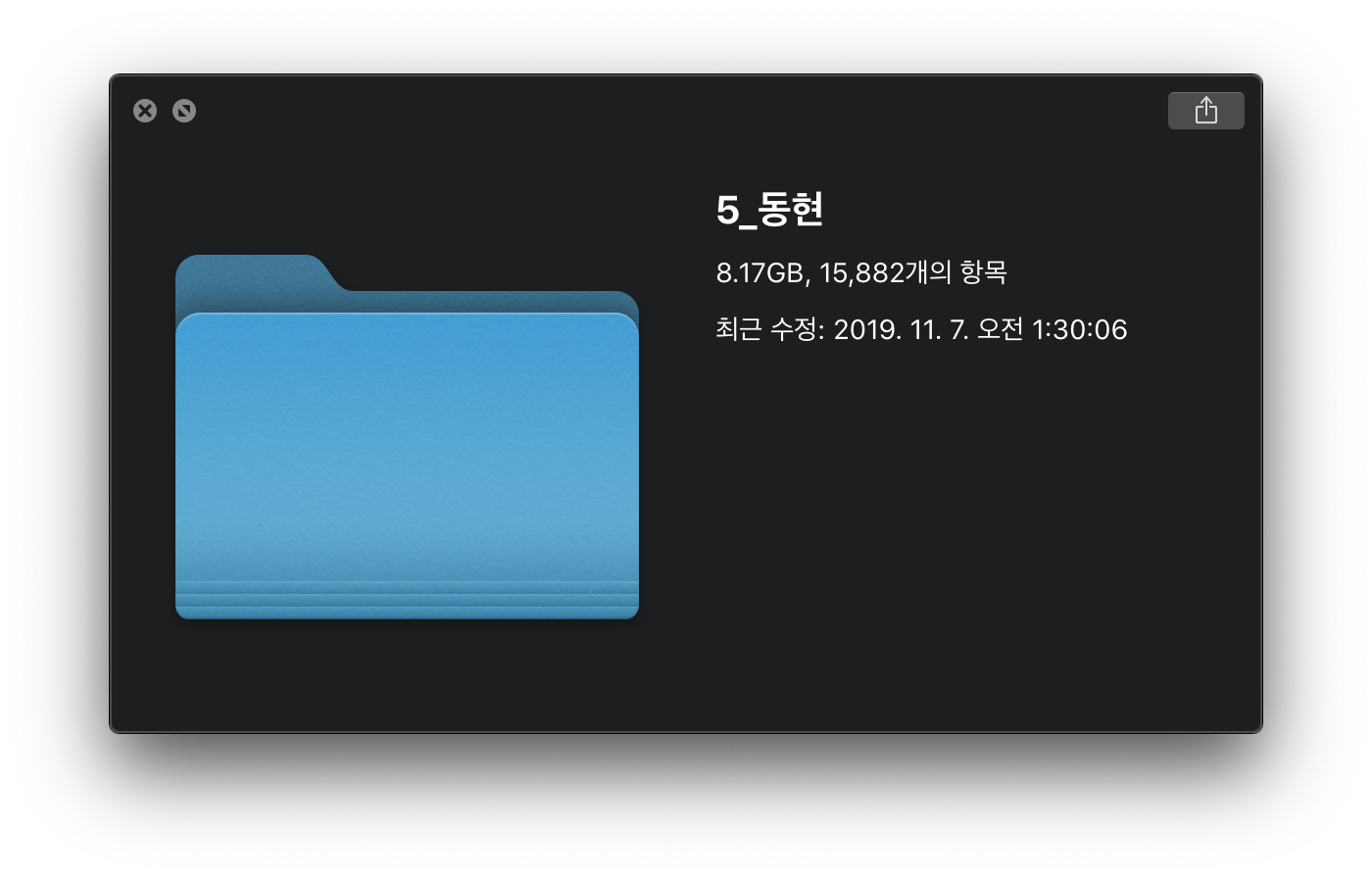
까마득 하지만 최선을 다해보려합니다.
그래도 수정을 하며 상식이 쌓여가는 느낌이라 재미있습니다.
앞으로 공부를 하며 알게된 내용이나 진행상황을 계속 올리려고 합니다.
목표달성을 위해 화이팅!
2019년 11월 14일 목요일! 9시 30분!!!!!!!!
드디어 완료!
휴먼팩토링이라고 불리며 했던 작업이 끝났습니다.
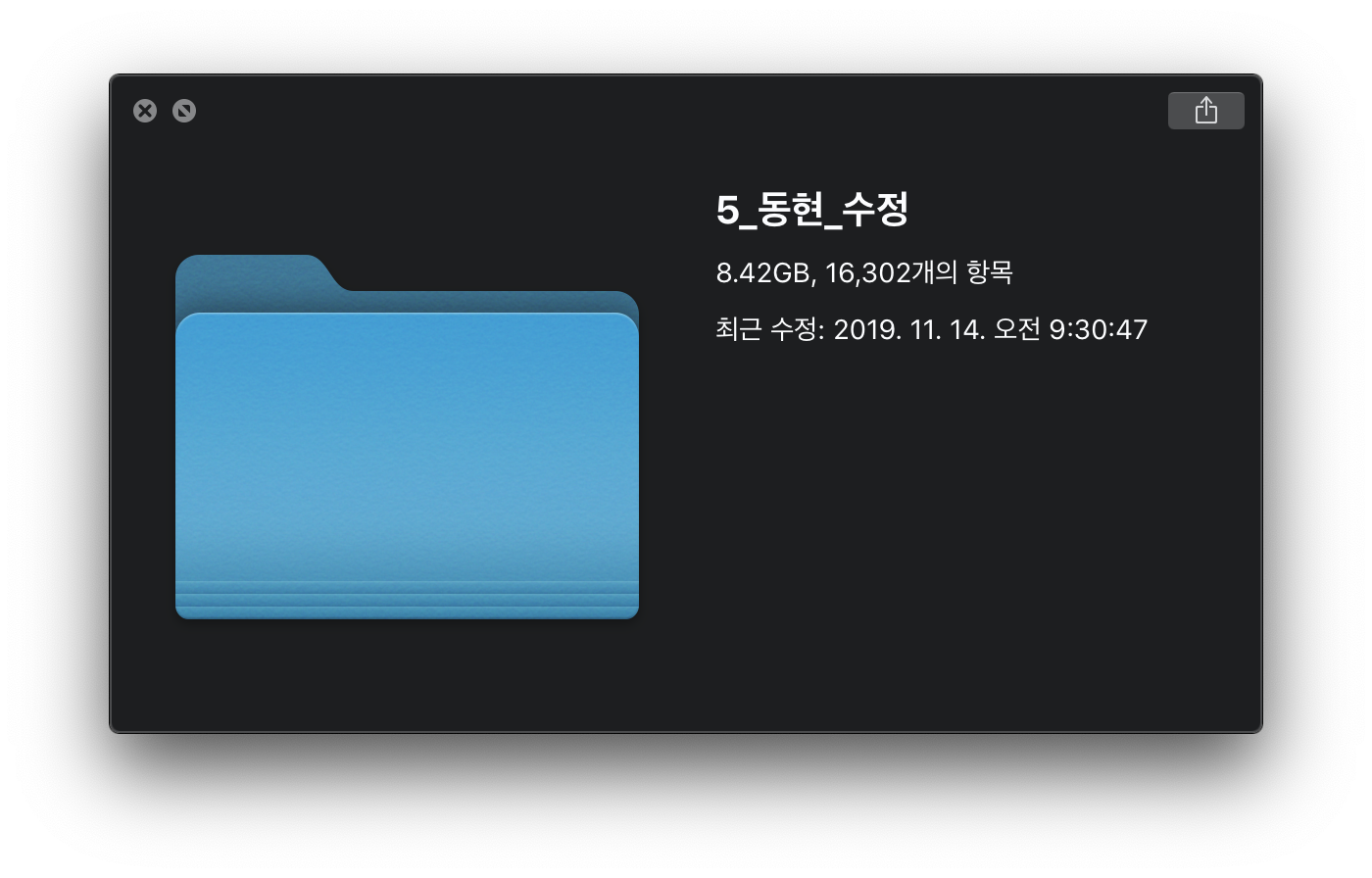

이제 아래의 오픈소스를 활용하여 한번 해보고자 합니다!
사용할 오픈소스
carpedm20/multi-speaker-tacotron-tensorflow
Multi-speaker Tacotron in TensorFlow. Contribute to carpedm20/multi-speaker-tacotron-tensorflow development by creating an account on GitHub.
github.com
sokcuri/multi-speaker-tacotron-tensorflow
Multi-speaker Tacotron in TensorFlow. 오픈소스 딥러닝 다중 화자 음성 합성 엔진. - sokcuri/multi-speaker-tacotron-tensorflow
github.com
참고할 링크들
고등학생이 해석한 Tacotron2
Tacotron2
medium.com
Siri를 아이유 목소리로 바꾸기 (1)
딥러닝을 이용한 모바일에서의 실시간 TTS 구현 - 1. 학습 데이터 준비
blog.crux.cx
'머신러닝 | 딥러닝' 카테고리의 다른 글
| [음성합성] multi-speaker-tacotron-tensorflow 실행 시 발생 이슈 해결 방법 모음 (4) | 2020.07.20 |
|---|---|
| Google Colab에서 Google Drive와 연동하기 (4) | 2019.09.10 |

