
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 우분투
- Kaggle
- 프로그래머스
- 편스토랑
- ChatGPT
- 데이콘
- github
- Baekjoon
- 더현대서울 맛집
- Git
- ubuntu
- 프로그래머스 파이썬
- PYTHON
- leetcode
- 맥북
- Real or Not? NLP with Disaster Tweets
- programmers
- 코로나19
- AI 경진대회
- gs25
- SW Expert Academy
- 파이썬
- 편스토랑 우승상품
- hackerrank
- 캐치카페
- Docker
- 백준
- 자연어처리
- 금융문자분석경진대회
- dacon
- Today
- Total
솜씨좋은장씨
[Python] pandas 0으로 시작하는 값에서 0을 살려서 read 하는 방법! ( feat. pandas dtype ) 본문
[Python] pandas 0으로 시작하는 값에서 0을 살려서 read 하는 방법! ( feat. pandas dtype )
솜씨좋은장씨 2022. 10. 29. 19:57
🧑🏻💻 겪었던 일
최근 회사에서 기존 고객사의 DB에 있는 정보를 기존 솔루션에 반영하는 작업을 진행하면서
csv 형식의 덤프파일로 만들어진 기존 DB의 정보를 솔루션에 반영하는 과정이 있었습니다.
솔루션에 모든 데이터가 별다른 에러가 없이 잘 들어가는 것을 확인하여 에러가 없나보다 하던 차에
기존 DB 데이터의 Contents ID 와 솔루션에 반영된 같은 데이터의 Contents ID 가 다른 것을 발견하였습니다.
기존 DB 데이터의 Contents ID 가 '0132323' 이었다면
솔루션에 반영된 같은 데이터의 Contents ID가 '132323' 으로
맨 앞의 0이 제거된 채로 반영이 되어있었습니다.
🧑🏻💻 원인
원인이 무엇일까 하고 찾다보니 덤프파일로 내려진 csv 파일을 읽을때
pandas 의 read_csv 를 활용하여 csv 파일을 읽는 과정에서
0132323 같은 값이 숫자형식으로 인식하면서 앞의 0이 사라지는 것 이었습니다.
🧑🏻💻 해결 방법
해결 방법은 생각보다 간단했습니다.
pandas 의 read_csv 를 활용하여 csv 를 읽을때
dtype 옵션을 주어 각 column 들을 어떤 형식으로 읽을 것인지 설정해주면 되었습니다.
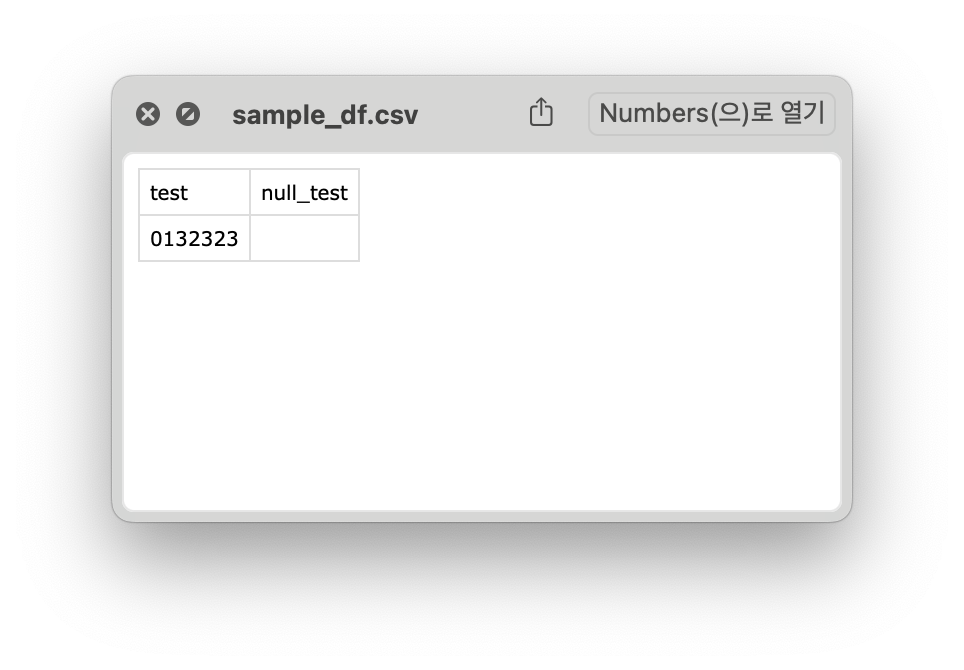
먼저 테스트 전에
0으로 시작하는 값이 들어간 column 과 NULL 값이 들어간 column 으로 구성된 파일하나를 준비했습니다.
🧑🏻💻 방법 1 - 전체 column 동일 적용
sample = pd.read_csv("sample_df.csv", dtype="object")또는
sample = pd.read_csv("sample_df.csv", dtype="string")
위와 같이 read_csv 에 dtype 을 설정해주면 됩니다.
0이 제거되지 않게 데이터를 불러오기 위해서는 dtype 에 "string" 또는 "object" 값을 넣어주면 됩니다.

🧑🏻💻 방법 2 - 특정 column 만 적용
sample = pd.read_csv("sample_df.csv", dtype={"test":'object'})특정 column 에만 형식을 지정하고 싶다!
그러면 dtype 에 dictionary 값을 넣어주면 됩니다.
샘플 파일 중에 "test" column 만 object / string type 으로 설정하고 싶다고 하면!
위와 같이 {"test": "object"} 를 dtype 에 넣어주면 됩니다.
다음부터는 사전에 데이터를 먼저 확인해보고
각 column 들의 값을 어떤 형식으로 읽을지 정한 뒤에 read_csv 를 사용해야겠다!
라는 생각이 들었습니다.
읽어주셔서 감사합니다.



