
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 백준
- ubuntu
- programmers
- gs25
- dacon
- 더현대서울 맛집
- 데이콘
- Kaggle
- 자연어처리
- github
- leetcode
- 파이썬
- Real or Not? NLP with Disaster Tweets
- 캐치카페
- 우분투
- 금융문자분석경진대회
- hackerrank
- 맥북
- SW Expert Academy
- 코로나19
- PYTHON
- 프로그래머스 파이썬
- 프로그래머스
- 편스토랑 우승상품
- AI 경진대회
- Baekjoon
- Git
- 편스토랑
- ChatGPT
- Docker
- Today
- Total
솜씨좋은장씨
[DACON] 한국어 문장 관계 분류 경진대회 - kakaobrain pororo 라이브러리를 활용하여 5분만에 결과 만들고 제출해보기! 본문
[DACON] 한국어 문장 관계 분류 경진대회 - kakaobrain pororo 라이브러리를 활용하여 5분만에 결과 만들고 제출해보기!
솜씨좋은장씨 2022. 2. 7. 21:00
한국어 문장 관계 분류 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
# 데이콘 ( DACON ) # 한국어 문장 관계 분류 경진대회 # pororo # 자연어처리 경진대회
아직 한창 진행중인 한국어 문장 관계 분류 경진대회를 예전 부터 관심을 가지고 있던 kakaobrain의 pororo 라이브러리를
활용하여 결과를 만들고 제출해본 내용을 공유해보고자 합니다.
기존에 대회에 참가한다고 하면
데이터를 구축하고 -> 모델을 만들고 -> 학습시키고 -> 결과를 도출하고 -> 이걸 제출 형식으로 만들어 제출
이렇게 진행하였다면
이 pororo 라이브러리를 활용하는 방식은
pororo 라이브러리를 설치하고 -> 결과를 도출하고 -> 제출
하는 방식으로 정말 간단하게 별도의 학습을 진행하는 과정 없이 약 5분의 시간만 투자하면
public score 기준 0.817 점을 낼 수 있는 방법입니다.
자세한 방법은 아래를 참고해주세요.
👨🏻💻 개발 환경 - Google Colab ( 기본 )
현재 이 방법은 Google Colab 에서 진행하였습니다.
👨🏻💻 pip version 업그레이드
$ pip install --upgrade pip👨🏻💻 pororo 라이브러리 설치
$ !git clone https://github.com/kakaobrain/pororo.git먼저 kakaobrain 의 github repo 중에서 pororo repository를 clone 해옵니다.
$ lspororo/ sample_data/ls 명령어를 활용하여 clone으로 생성된 pororo 디렉토리가 존재하는지 확인하고
$ cd pororopororo 디렉토리로 이동합니다.
$ !pip install -e .그리고 위의 명령어로 설치를 진행합니다.
Obtaining file:///content/pororo
Preparing metadata (setup.py) ... done
Collecting torch==1.6.0
Downloading torch-1.6.0-cp37-cp37m-manylinux1_x86_64.whl (748.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 748.8/748.8 MB 953.8 kB/s eta 0:00:00
Collecting torchvision==0.7.0
Downloading torchvision-0.7.0-cp37-cp37m-manylinux1_x86_64.whl (5.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.9/5.9 MB 57.4 MB/s eta 0:00:00
Requirement already satisfied: pillow>=4.1.1 in /usr/local/lib/python3.7/dist-packages (from pororo==0.4.1) (7.1.2)
Collecting fairseq>=0.10.2
Downloading fairseq-0.10.2-cp37-cp37m-manylinux1_x86_64.whl (1.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.7/1.7 MB 37.4 MB/s eta 0:00:00
Collecting transformers>=4.0.0
Downloading transformers-4.16.2-py3-none-any.whl (3.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.5/3.5 MB 50.9 MB/s eta 0:00:00
Collecting sentence_transformers>=0.4.1.2
Downloading sentence-transformers-2.1.0.tar.gz (78 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 78.5/78.5 KB 8.0 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
---------------------------------------- 이하 생략 ----------------------------------------설치중에
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchtext 0.11.0 requires torch==1.10.0, but you have torch 1.6.0 which is incompatible.
torchaudio 0.10.0+cu111 requires torch==1.10.0, but you have torch 1.6.0 which is incompatible.설치중에 위와 같은 에러 메세지가 나오는데 현재 이 과정에서는 문제가 되지 않으므로 일단 패스합니다.
👨🏻💻 런타임 다시 시작하기
위의 방법으로 pororo 라이브러리를 설치하였다면 Colab의 런타임을 다시 시작해주어야 제대로 사용이 가능합니다.
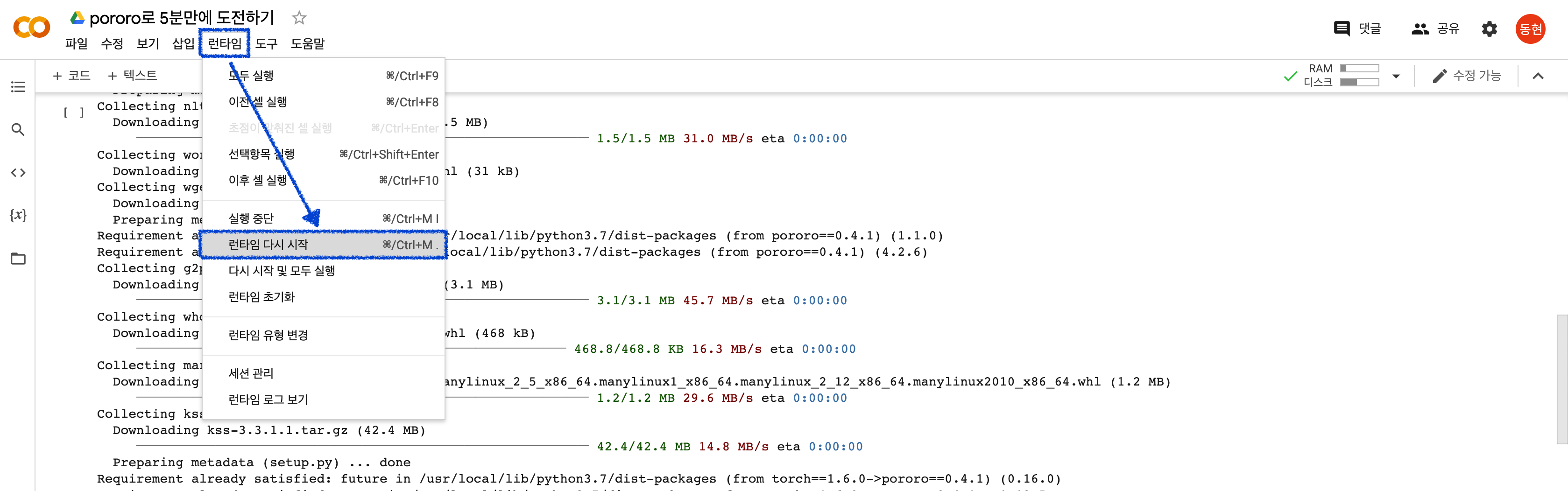
위의 메뉴 중에서 런타임 > 런타임 다시 시작을 선택합니다.
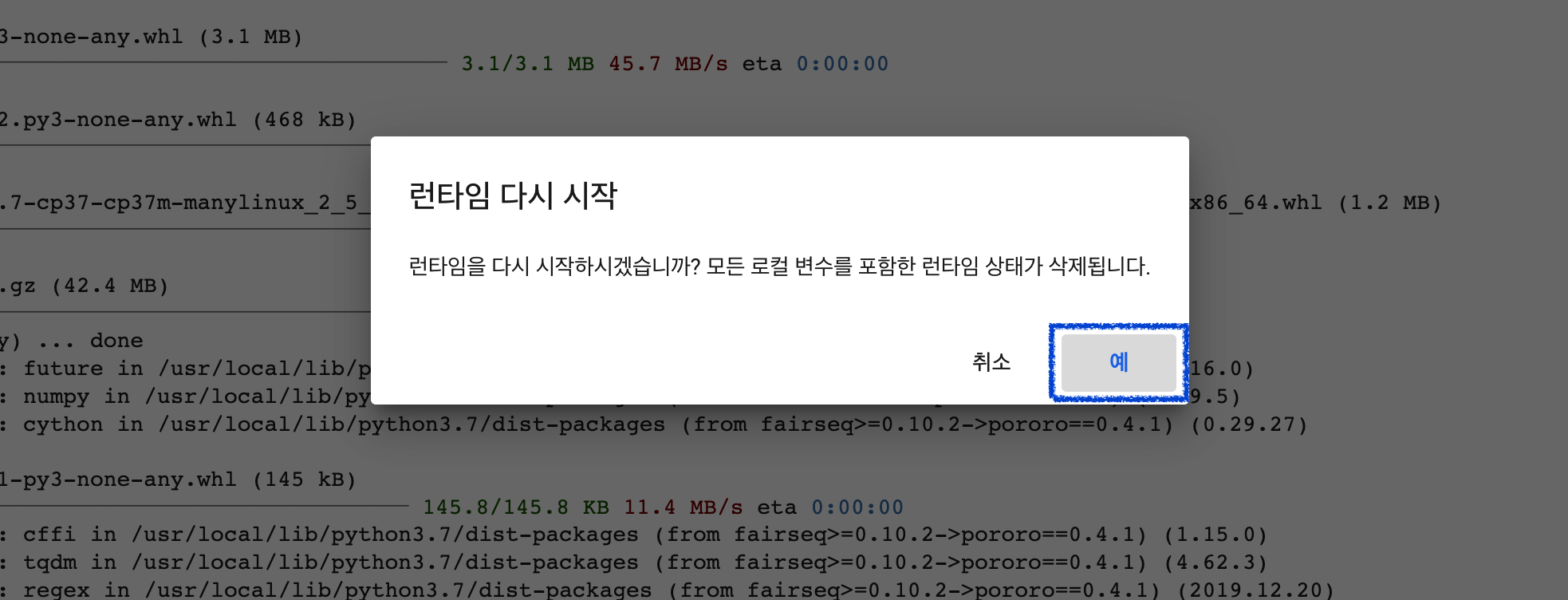
런타임을 다시 시작하시겠습니까? 모든 로컬 변수를 포함한 런타임 상태가 삭제됩니다. 라고 물어보면 예를 클릭합니다.
👨🏻💻 필요한 파일 업로드 하기
한국어 문장 관계 분류 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
위의 링크에서 다운받은 파일 중 test_data.csv와 sample_submission.csv 파일을 Colab에 업로드 시켜줍니다.
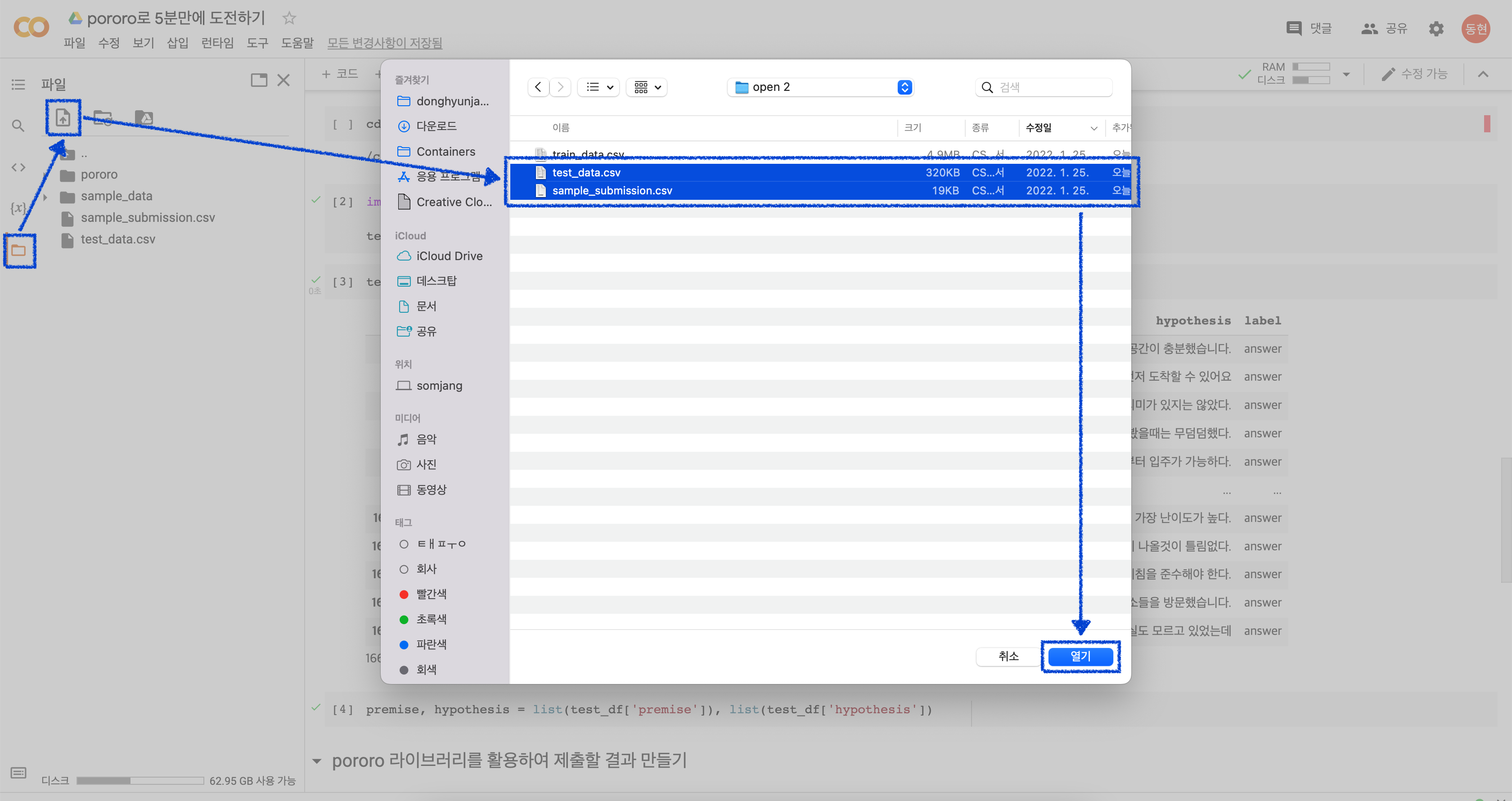
업로드는 위와 같이 진행합니다.
👨🏻💻 데이터 읽어와서 pororo로 결과 만들기
import pandas as pd
test_df = pd.read_csv("./test_data.csv")
sub_df = pd.read_csv("./sample_submission.csv")먼저 조금 전 업로드한 test_data.csv와 sample_submission.csv 를 pandas를 활용하여 읽어옵니다.

test_data.csv는 필요한 값이 premise와 hypothesis column으로 데이터가 나뉘어져 있으므로
premise, hypothesis = list(test_df['premise']), list(test_df['hypothesis'])각각의 열을 꺼내와 리스트로 만들어줍니다.
from pororo import Pororo
nli_module = Pororo(task="nli", lang="ko")본격적으로 pororo 라이브러리를 import 해주고 task는 nli 언어는 ko로 설정하여 nli 모듈을 하나 만들어줍니다.
nli_module(premise[0], hypothesis[0])이렇게 값을 하나씩 넣어주면
참(Entailment) 또는 거짓(Contradiction) 또는 중립(Neutral)중에 하나의 결과가 나오게 됩니다.
from tqdm import tqdm_notebook
nli_results = []
for pre, hypo in tqdm_notebook(zip(premise, hypothesis)):
result = nli_module(pre, hypo)
nli_results.append(result)이를 모든 row에 적용하여 나온 결과를 nli_results 리스트에 모아줍니다.
sub_df['label'] = nli_results
sub_df.to_csv("./pororo_result_sub.csv", index=False)나온 결과를 아까 읽어두었던 sample_submission.csv의 label column에 넣고 이를 csv로 만들어 줍니다.
그리고 데이콘에 제출하면 끝!
여기까지 약 5~7분 정도의 시간이 걸렸습니다.
👨🏻💻 제출 결과는?
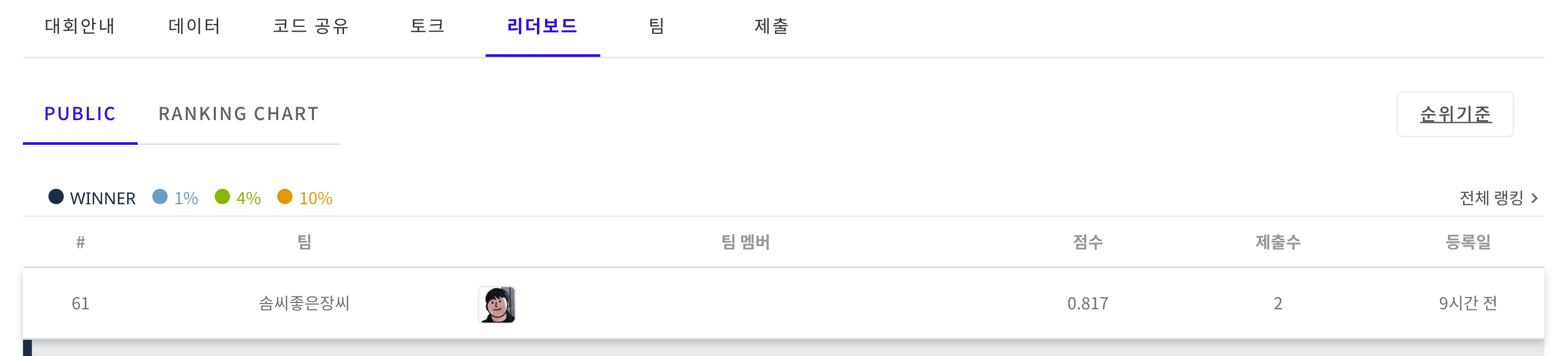
Public Score 가 0.817로 나왔습니다.
아무것도 학습을 시키지 않았는데 0.817이라는 점수로 생각보다 높은 점수라 조금 놀랐습니다.
읽어주셔서 감사합니다.