
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 코로나19
- Docker
- programmers
- 더현대서울 맛집
- 파이썬
- Kaggle
- hackerrank
- SW Expert Academy
- 프로그래머스
- 백준
- PYTHON
- ubuntu
- Git
- dacon
- 금융문자분석경진대회
- Real or Not? NLP with Disaster Tweets
- leetcode
- 자연어처리
- 편스토랑 우승상품
- 맥북
- ChatGPT
- Baekjoon
- 데이콘
- 우분투
- gs25
- github
- 캐치카페
- 편스토랑
- AI 경진대회
- 프로그래머스 파이썬
- Today
- Total
솜씨좋은장씨
[DACON] 심리 성향 예측 AI 경진대회 3, 4일차! 본문

심리 성향 예측 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
3일차 4일차에 시도해본 내용을 정리한 글입니다.
3일차에는 tensorflow를 활용하여 결과를 내보기로 했습니다.
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import metrics
from tensorflow.keras import optimizers
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping()
model2 = Sequential()
model2.add(Dense(32, input_dim=76, activation='relu'))
model2.add(Dense(1, activation='sigmoid'))
model2.compile(optimizer=optimizers.Adam(lr=0.001), loss='binary_crossentropy', metrics=[metrics.binary_accuracy], callbaks=[early_stopping])
hist2 = model2.fit(train_x, new_train_y_numpy, epochs=100, batch_size=64, validation_split=0.1)Epoch 1/100
641/641 [==============================] - 1s 2ms/step - loss: 186.0221 - binary_accuracy: 0.5117 - val_loss: 147.6819 - val_binary_accuracy: 0.4901
Epoch 2/100
641/641 [==============================] - 1s 2ms/step - loss: 83.5147 - binary_accuracy: 0.5290 - val_loss: 281.4259 - val_binary_accuracy: 0.5301
Epoch 3/100
641/641 [==============================] - 1s 2ms/step - loss: 3329.9207 - binary_accuracy: 0.5348 - val_loss: 328.3573 - val_binary_accuracy: 0.5430
Epoch 4/100
641/641 [==============================] - 1s 2ms/step - loss: 81.2396 - binary_accuracy: 0.5499 - val_loss: 92.3682 - val_binary_accuracy: 0.5529
Epoch 5/100
641/641 [==============================] - 1s 2ms/step - loss: 75.9786 - binary_accuracy: 0.5494 - val_loss: 317.0158 - val_binary_accuracy: 0.5246
...
Epoch 96/100
641/641 [==============================] - 1s 2ms/step - loss: 1.4184 - binary_accuracy: 0.5474 - val_loss: 3.8801 - val_binary_accuracy: 0.5448
Epoch 97/100
641/641 [==============================] - 1s 2ms/step - loss: 0.9073 - binary_accuracy: 0.5475 - val_loss: 2.9187 - val_binary_accuracy: 0.5446
Epoch 98/100
641/641 [==============================] - 1s 2ms/step - loss: 0.7945 - binary_accuracy: 0.5476 - val_loss: 3.1939 - val_binary_accuracy: 0.5448
Epoch 99/100
641/641 [==============================] - 1s 2ms/step - loss: 0.8234 - binary_accuracy: 0.5475 - val_loss: 2.9365 - val_binary_accuracy: 0.5450
Epoch 100/100
641/641 [==============================] - 1s 2ms/step - loss: 18.7670 - binary_accuracy: 0.5475 - val_loss: 6.5317 - val_binary_accuracy: 0.5444import matplotlib.pyplot as plt
history_dict = hist2.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss') # ‘bo’는 파란색 점을 의미합니다.
plt.plot(epochs, val_loss, 'b', label='Validation loss') # ‘b’는 파란색 실선을 의미합니다.
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()plt.clf() # 그래프를 초기화합니다.
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
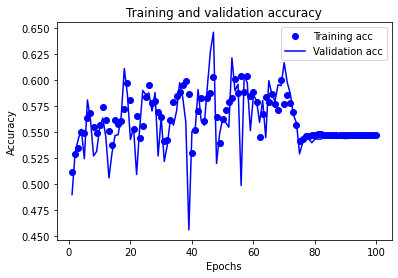
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()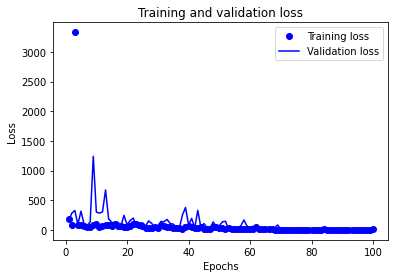
pred_y = model2.predict(test)
for i in range(len(pred_y)):
submission['voted'].iloc[i] = pred_y[i]
submission.to_csv('./data/baselinne_07.csv')뭔가 너무많이 학습시킨 것 같은 느낌이 있었지만 일단 한번 제출해보기로 했습니다.
결과는?
0.5022518838 이 나왔습니다. 50%라니!ㅋㅋㅋㅋ 랜덤으로 제출해도 나올법한 결과가 나왔습니다. 이런....
아마 과적합이 일어나지 않았을까 추측해보았습니다.
3일차는 50%의 충격에 벗어나지 못하여 더이상 진행하지 못하였습니다. 이런!
4일차는 며칠 지난 10월 10일에 진행하였습니다.
[TensorFlow] 심장질환 예측
[TensorFlow] 심장질환 예측 Start BioinformaticsAndMe [TensorFlow] 심장질환 예측 : TensorFlow 2.0 에서 만들어진 DNN(심층신경망) 모델에 근거하여, 환자데이터로부터 심장병 유무를 예측 : 심장병은 사망..
bioinformaticsandme.tistory.com
내가 모델을 만들때 무언가 놓친 것이 있는걸까? 생각하며 tensorflow를 활용하여 수치를 입력하여
심장질환에 걸리는 여부를 예측한 모델을 만들어 포스팅한 글을 찾게되었고
오늘은 이 글을 바탕으로 도전해보기로 했습니다.
f = sns.countplot(x='voted', data=train2)
f.set_title("voted")
f.set_xticklabels(['Yes', 'No'])
plt.xlabel("")plt.rcParams['figure.figsize'] = [60, 30]
heat_map = sns.heatmap(train2.corr(), vmin=0.2, annot=True, vmax=0.9)
plt.title("Correlation Heatmap")롸...?
히트맵을 그렸는데 검...정....새....ㄱ...
일단! 나머지 과정도 계속 해보겠습니다.
headers = list(train_x.columns)
feature_columns = []
for header in headers:
feature_columns.append(tf.feature_column.numeric_column(header))def create_dataset(dataframe, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop("voted")
return tf.data.Dataset.from_tensor_slices((dict(dataframe), labels)).shuffle(buffer_size=len(dataframe)).batch(batch_size)def create_dataset2(dataframe, batch_size=32):
dataframe = dataframe.copy()
return tf.data.Dataset.from_tensor_slices((dict(dataframe))).shuffle(buffer_size=len(dataframe)).batch(batch_size)train_new = create_dataset(train2)test_new = create_dataset2(test)model = tf.keras.models.Sequential([
tf.keras.layers.DenseFeatures(feature_columns=feature_columns),
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(train_new, epochs=100, use_multiprocessing=True)Epoch 1/100
1423/1423 [==============================] - 10s 7ms/step - loss: 915.2695 - accuracy: 0.5098
Epoch 2/100
1423/1423 [==============================] - 10s 7ms/step - loss: 318.7974 - accuracy: 0.4963
Epoch 3/100
1423/1423 [==============================] - 10s 7ms/step - loss: 270.1427 - accuracy: 0.5388
Epoch 4/100
1423/1423 [==============================] - 10s 7ms/step - loss: 169.0490 - accuracy: 0.5387
Epoch 5/100
1423/1423 [==============================] - 11s 7ms/step - loss: 116.1816 - accuracy: 0.5424
...
Epoch 96/100
1423/1423 [==============================] - 10s 7ms/step - loss: 0.6887 - accuracy: 0.5468
Epoch 97/100
1423/1423 [==============================] - 10s 7ms/step - loss: 0.6887 - accuracy: 0.5469
Epoch 98/100
1423/1423 [==============================] - 10s 7ms/step - loss: 0.6887 - accuracy: 0.5469
Epoch 99/100
1423/1423 [==============================] - 10s 7ms/step - loss: 0.6887 - accuracy: 0.5469
Epoch 100/100
1423/1423 [==============================] - 10s 7ms/step - loss: 0.6887 - accuracy: 0.5469import matplotlib.pyplot as plt
history_dict = history.history
print(history_dict.keys())
loss = history_dict['loss']
# val_loss = history_dict['val_loss']
# accuracy = history_dict['accuracy']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'b', label='Training loss') # ‘bo’는 파란색 점을 의미합니다.
# plt.plot(epochs, accuracy, 'b', label='accuracy') # ‘b’는 파란색 실선을 의미합니다.
plt.title('Training')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()import matplotlib.pyplot as plt
history_dict = history.history
print(history_dict.keys())
# loss = history_dict['loss']
# val_loss = history_dict['val_loss']
accuracy = history_dict['accuracy']
epochs = range(1, len(loss) + 1)
# plt.plot(epochs, loss, 'b', label='Training loss') # ‘bo’는 파란색 점을 의미합니다.
plt.plot(epochs, accuracy, 'b', label='accuracy') # ‘b’는 파란색 실선을 의미합니다.
plt.title('Training')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()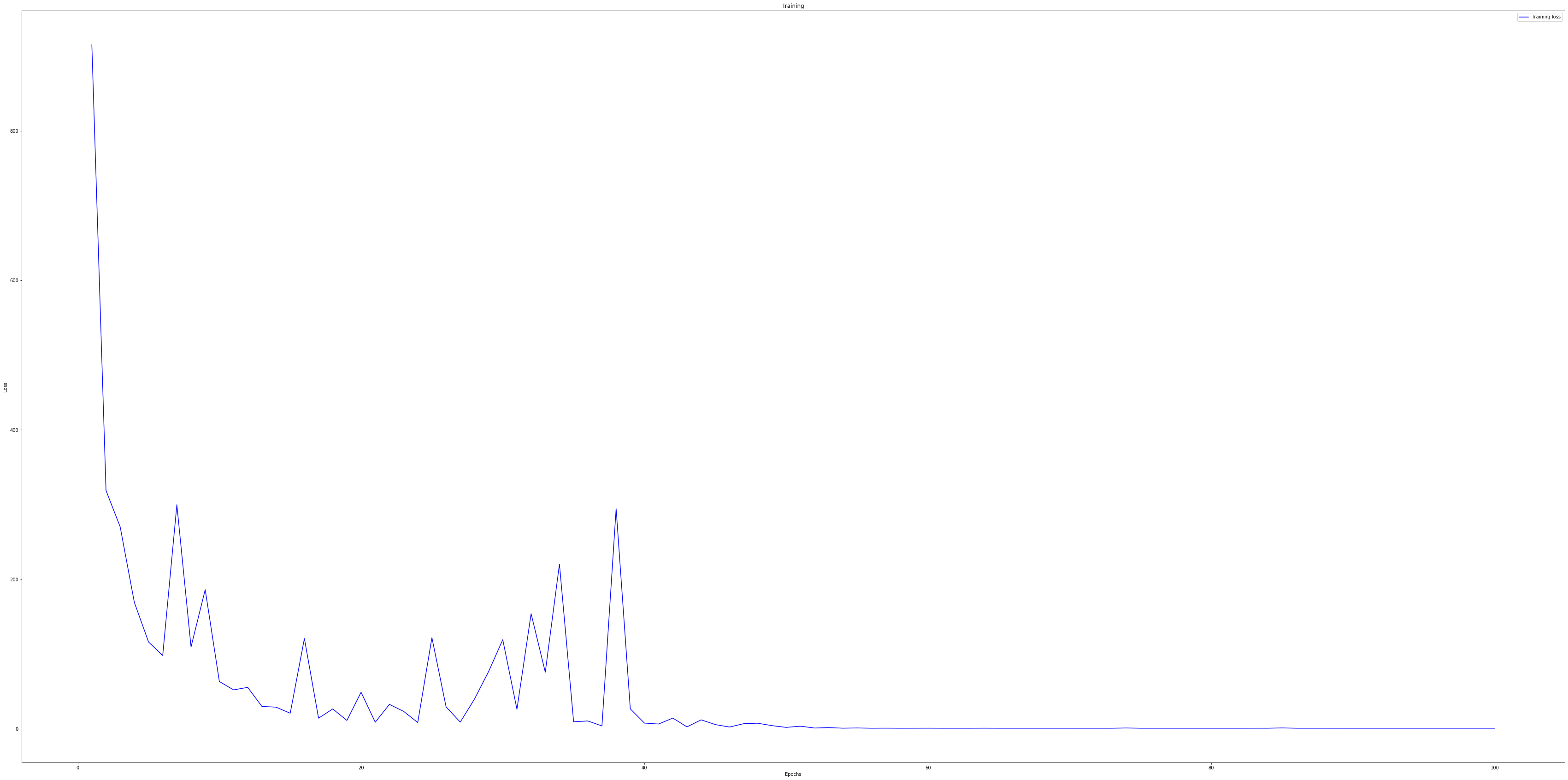

pred_y = model.predict(test_new)
new_y = []
for i in range(len(pred_y)):
new_y.append(pred_y[i][0])
submission['voted']=new_y
submission.to_csv('./data/baselinne_08.csv')와우! 뭔가 잘못해도 제대로 잘못하고 있는것 같습니다.
0.5000291126 이라니!
import random
random_answer = []
for i in range(len(test)):
random_answer.append(random.randint(1, 2))
submission['voted'] = random_answer
submission.to_csv("./data/baselinne_09.csv")랜덤으로 제출하면 어떻게 결과가 다를까 확인해봤더니...!
49.77247135...! 좀 더 공부해봐야겠습니다.
혹시 너무 많이 학습시켜서 과적합 되었나 싶어 loss가 어느정도 1 보다 작아질 시점이었던 epoch 60번대까지만
학습시켜서 결과를 도출해보겠습니다.
history = model.fit(train_new, epochs=60, use_multiprocessing=True)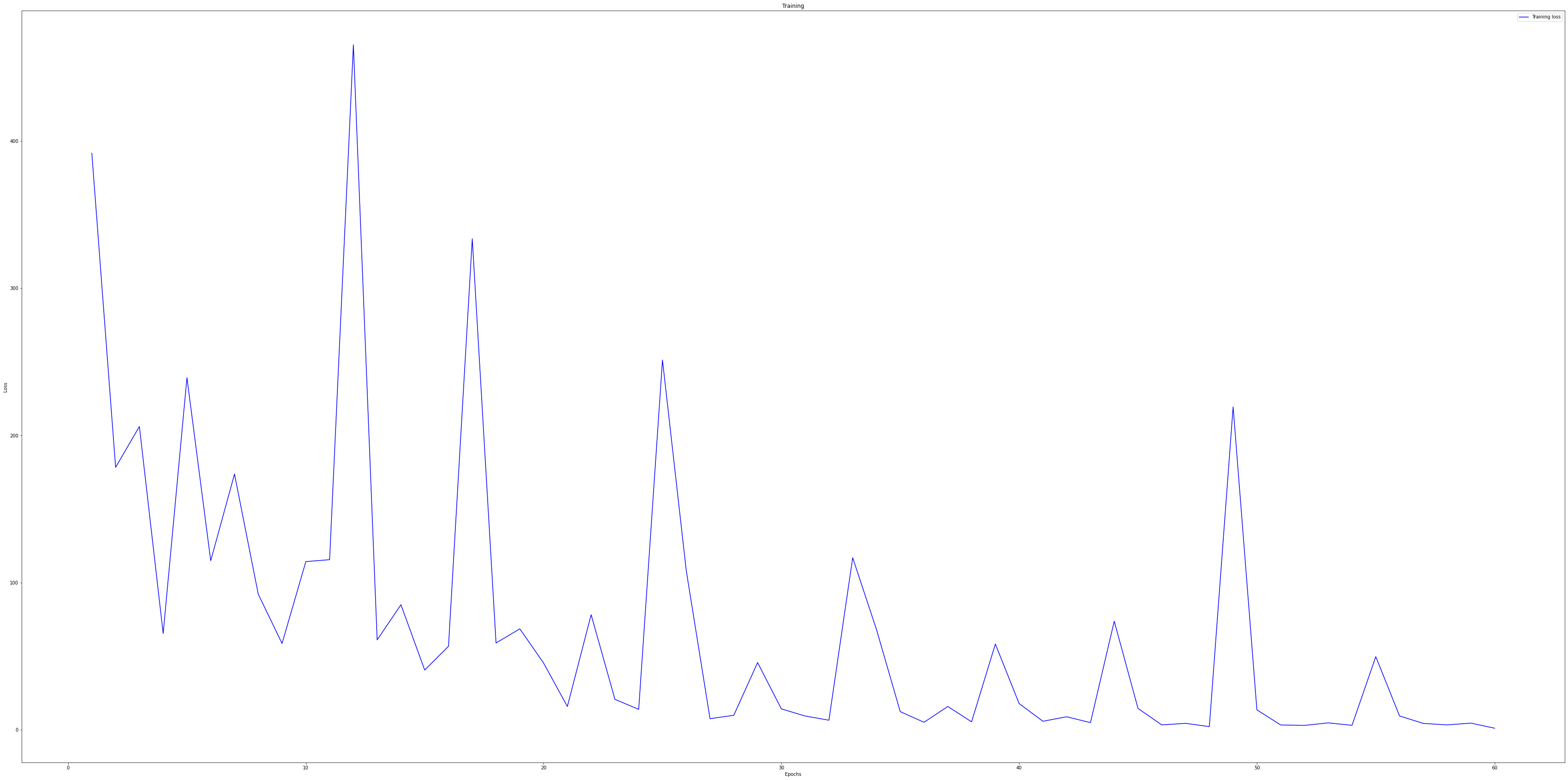
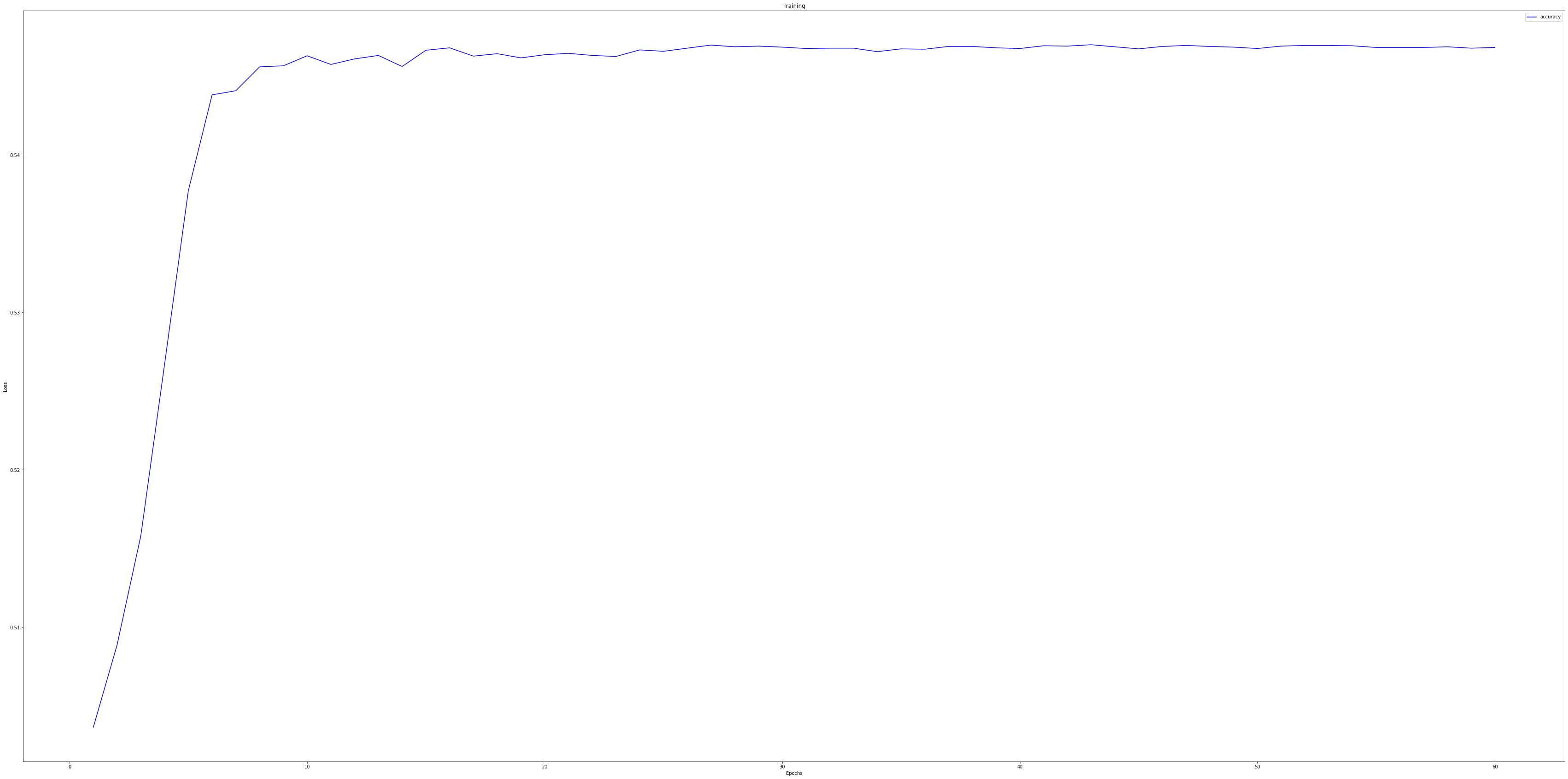
0.5001863367...?
더 공부하고 더 데이터를 뜯어보고 해봐야겠습니다.
오늘은 여기까지
실패기지만 읽어주셔서 감사합니다.
'DACON > 심리 성향 예측 AI 경진대회' 카테고리의 다른 글
| [DACON] 심리 성향 예측 AI 경진대회 2일차! (0) | 2020.10.04 |
|---|---|
| [DACON] 심리 성향 예측 AI 경진대회 1일차! (0) | 2020.10.01 |
| [DACON] 심리 성향 예측 AI 경진대회 도전! (0) | 2020.09.30 |


