
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 프로그래머스 파이썬
- SW Expert Academy
- leetcode
- 편스토랑
- 데이콘
- 맥북
- 자연어처리
- Real or Not? NLP with Disaster Tweets
- AI 경진대회
- Baekjoon
- ChatGPT
- hackerrank
- 백준
- 더현대서울 맛집
- gs25
- github
- 프로그래머스
- ubuntu
- Docker
- 우분투
- programmers
- Kaggle
- Git
- PYTHON
- 코로나19
- dacon
- 금융문자분석경진대회
- 편스토랑 우승상품
- 파이썬
- 캐치카페
- Today
- Total
솜씨좋은장씨
[DACON] 소설 작가 분류 AI 경진대회 6일차! 본문

소설 작가 분류 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
소설 작가 분류 AI 경진대회 6일차!
오늘도 퇴근 후 즐거운 DACON 도전의 시간이 다가왔습니다.
오늘은 전처리 방법에서 Stemmer를 LancasterStemmer 에서 Porterstemmer로 바꾸고
임베딩 차원을 16 -> 128로 늘렸습니다.
import pandas as pd
import re
train_dataset = pd.read_csv("./train.csv")
test_dataset = pd.read_csv("./test_x.csv")먼저 데이터를 불러옵니다.
from nltk.corpus import stopwords
def alpha_num(text):
return re.sub(r"[^A-Za-z0-9\']", ' ', text)
stopwords_list = [ "a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as",
"at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "will",
"did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has",
"have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself",
"his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself",
"let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours",
"ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that",
"that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll",
"they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll",
"we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom",
"why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
stopwords_list = stopwords_list + stopwords.words('english')' 를 제외한 특수문자를 제거하는 함수와 불용어를 만들어줍니다.
from tqdm import tqdm
import re
def get_clean_text_list(data_df):
plain_text_list = list(data_df['text'])
clear_text_list = []
for i in tqdm(range(len(plain_text_list))):
plain_text = plain_text_list[i].lower()
plain_text = alpha_num(plain_text)
plain_split = plain_text.split()
plain_split = [word.strip() for word in plain_split if word.strip() not in stopwords_list]
clear_text = " ".join(plain_split).replace("'", "")
clear_text_list.append(clear_text)
return clear_text_listtrain_dataset['clear_text'] = get_clean_text_list(train_dataset)
test_dataset['clear_text'] = get_clean_text_list(test_dataset)이를 바탕으로 전처리를 한 번 진행합니다.
from nltk.tokenize import word_tokenize
# from nltk.stem.lancaster import LancasterStemmer
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
import re
X_train = []
train_clear_text = list(train_dataset['clear_text'])
for i in tqdm(range(len(train_clear_text))):
temp = word_tokenize(train_clear_text[i])
temp = [stemmer.stem(word) for word in temp]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)
X_test = []
test_clear_text = list(test_dataset['clear_text'])
for i in tqdm(range(len(test_clear_text))):
temp = word_tokenize(test_clear_text[i])
temp = [stemmer.stem(word) for word in temp]
temp = [word for word in temp if len(word) > 1]
X_test.append(temp)5일차에서 LancasterStemmer를 활용했던 것을 PorterStemmer로 변경하여 시도해보았습니다.
word_list = []
for i in tqdm(range(len(X_train))):
for j in range(len(X_train[i])):
word_list.append(X_train[i][j])
len(list(set(word_list)))20445이렇게 전처리를 하고보니 총 20,445개의 유니크한 단어로 구성되어있었습니다.
import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()
#파라미터 설정
vocab_size = 20445
embedding_dim = 16
max_length = 204
padding_type='post'from keras_preprocessing.text import Tokenizer
#tokenizer에 fit
tokenizer = Tokenizer(num_words = vocab_size)#, oov_token=oov_tok)
tokenizer.fit_on_texts(X_train)
word_index = tokenizer.word_indexfrom keras_preprocessing.sequence import pad_sequences
#데이터를 sequence로 변환해주고 padding 해줍니다.
train_sequences = tokenizer.texts_to_sequences(X_train)
train_padded = pad_sequences(train_sequences, padding=padding_type, maxlen=max_length)
test_sequences = tokenizer.texts_to_sequences(X_test)
test_padded = pad_sequences(test_sequences, padding=padding_type, maxlen=max_length)import tensorflow as tf
#가벼운 NLP모델 생성
model23 = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(5, activation='softmax')
])
# compile model
model23.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# model summary
print(model23.summary())
# fit model
num_epochs = 40
history23 = model23.fit(train_padded, y_train,
epochs=num_epochs, batch_size=256,
validation_split=0.2)Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, 204, 16) 327120
_________________________________________________________________
global_average_pooling1d_4 ( (None, 16) 0
_________________________________________________________________
dense_8 (Dense) (None, 24) 408
_________________________________________________________________
dropout_4 (Dropout) (None, 24) 0
_________________________________________________________________
dense_9 (Dense) (None, 5) 125
=================================================================
Total params: 327,653
Trainable params: 327,653
Non-trainable params: 0
_________________________________________________________________
None
Train on 43903 samples, validate on 10976 samples
Epoch 1/40
43903/43903 [==============================] - 2s 43us/sample - loss: 1.5755 - accuracy: 0.2769 - val_loss: 1.5629 - val_accuracy: 0.2700
Epoch 2/40
43903/43903 [==============================] - 1s 32us/sample - loss: 1.5521 - accuracy: 0.2924 - val_loss: 1.5365 - val_accuracy: 0.3098
...
Epoch 39/40
43903/43903 [==============================] - 1s 30us/sample - loss: 0.4508 - accuracy: 0.8363 - val_loss: 0.7365 - val_accuracy: 0.7362
Epoch 40/40
43903/43903 [==============================] - 1s 30us/sample - loss: 0.4475 - accuracy: 0.8374 - val_loss: 0.7387 - val_accuracy: 0.74085일차에서 가장 좋은 성적을 냈던 모델과 같은 모델에 넣고 epoch은 40으로 늘려 학습시킨 후에
결과를 도출하고 제출해보았습니다.
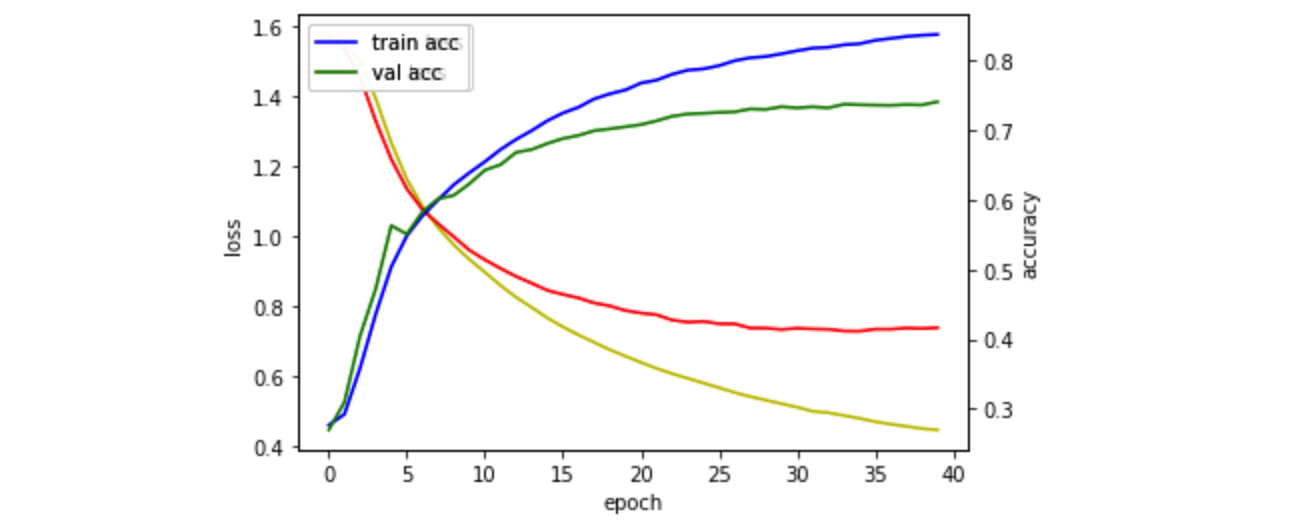
결과 도출
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = model23.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_16.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

5일차보다 좋은 결과가 나오기를 기대했지만 0.5070571629 라는 조금은 아쉬운 점수를 얻을 수 있었습니다.
임베딩 레이어에서 차원이 너무 작아서 그런가...? 라는 생각을 하게되었고 임베딩 레이어에 embedding_dim을 128로
변경하여 시도해 보았습니다.
import tensorflow as tf
#가벼운 NLP모델 생성
model24 = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 128, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(5, activation='softmax')
])
# compile model
model24.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# model summary
print(model24.summary())
# fit model
num_epochs = 15
history24 = model24.fit(train_padded, y_train,
epochs=num_epochs, batch_size=256,
validation_split=0.2)Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_10 (Embedding) (None, 204, 128) 2616960
_________________________________________________________________
global_average_pooling1d_7 ( (None, 128) 0
_________________________________________________________________
dense_15 (Dense) (None, 24) 3096
_________________________________________________________________
dropout_10 (Dropout) (None, 24) 0
_________________________________________________________________
dense_16 (Dense) (None, 5) 125
=================================================================
Total params: 2,620,181
Trainable params: 2,620,181
Non-trainable params: 0
_________________________________________________________________
None
Train on 43903 samples, validate on 10976 samples
Epoch 1/15
43903/43903 [==============================] - 5s 114us/sample - loss: 1.5650 - accuracy: 0.2796 - val_loss: 1.5434 - val_accuracy: 0.2772
Epoch 2/15
43903/43903 [==============================] - 4s 96us/sample - loss: 1.4584 - accuracy: 0.3705 - val_loss: 1.3469 - val_accuracy: 0.4257
...
Epoch 14/15
43903/43903 [==============================] - 5s 105us/sample - loss: 0.5870 - accuracy: 0.7869 - val_loss: 0.7445 - val_accuracy: 0.7261
Epoch 15/15
43903/43903 [==============================] - 4s 101us/sample - loss: 0.5620 - accuracy: 0.7966 - val_loss: 0.7366 - val_accuracy: 0.7294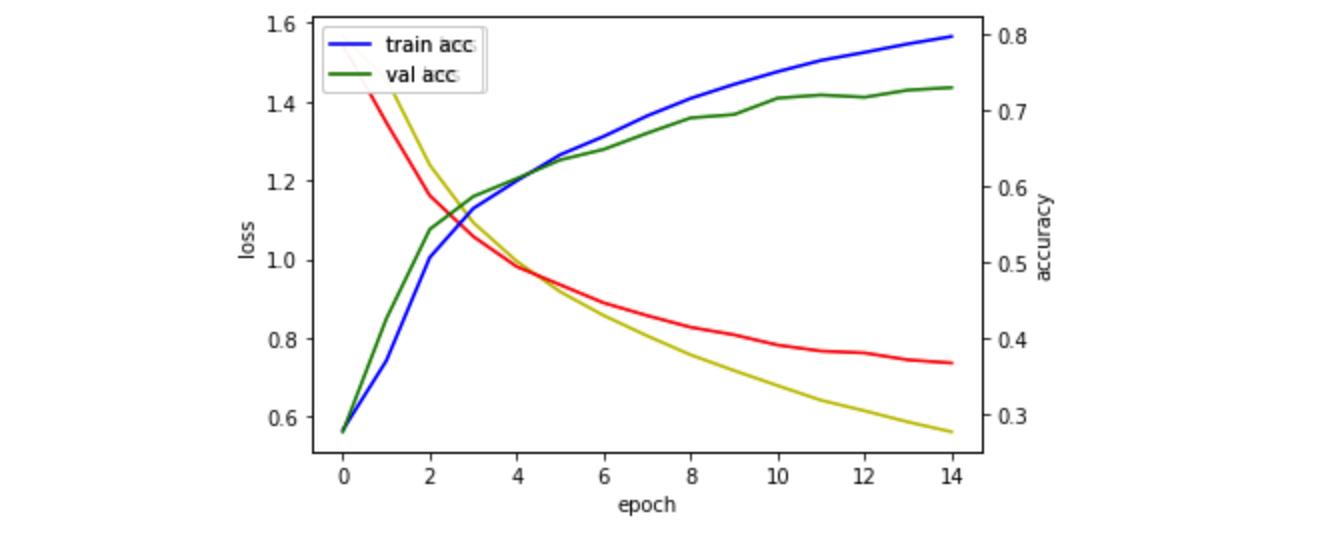
결과 도출
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = model24.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_17.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

오 이번에는 0.4829543261로 5일차의 최고 점수에 근접한 결과가 나왔습니다.
같은 방법으로 만든 모델로 여러번 재시도 해보면서 validation loss가 가장 잘 떨어지기를 확인해보면서
가장 괜챃았던 모델을 활용하여 결과를 도출하고 제출해보았습니다.
Model: "sequential_12"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_14 (Embedding) (None, 204, 128) 2616960
_________________________________________________________________
global_average_pooling1d_11 (None, 128) 0
_________________________________________________________________
dense_23 (Dense) (None, 24) 3096
_________________________________________________________________
dropout_14 (Dropout) (None, 24) 0
_________________________________________________________________
dense_24 (Dense) (None, 5) 125
=================================================================
Total params: 2,620,181
Trainable params: 2,620,181
Non-trainable params: 0
_________________________________________________________________
None
Train on 43903 samples, validate on 10976 samples
Epoch 1/15
43903/43903 [==============================] - 5s 119us/sample - loss: 1.5651 - accuracy: 0.2718 - val_loss: 1.5515 - val_accuracy: 0.2710
Epoch 2/15
43903/43903 [==============================] - 5s 103us/sample - loss: 1.4956 - accuracy: 0.3691 - val_loss: 1.3967 - val_accuracy: 0.5198
...
Epoch 14/15
43903/43903 [==============================] - 4s 101us/sample - loss: 0.5399 - accuracy: 0.8054 - val_loss: 0.7070 - val_accuracy: 0.7365
Epoch 15/15
43903/43903 [==============================] - 4s 100us/sample - loss: 0.5214 - accuracy: 0.8114 - val_loss: 0.7027 - val_accuracy: 0.7421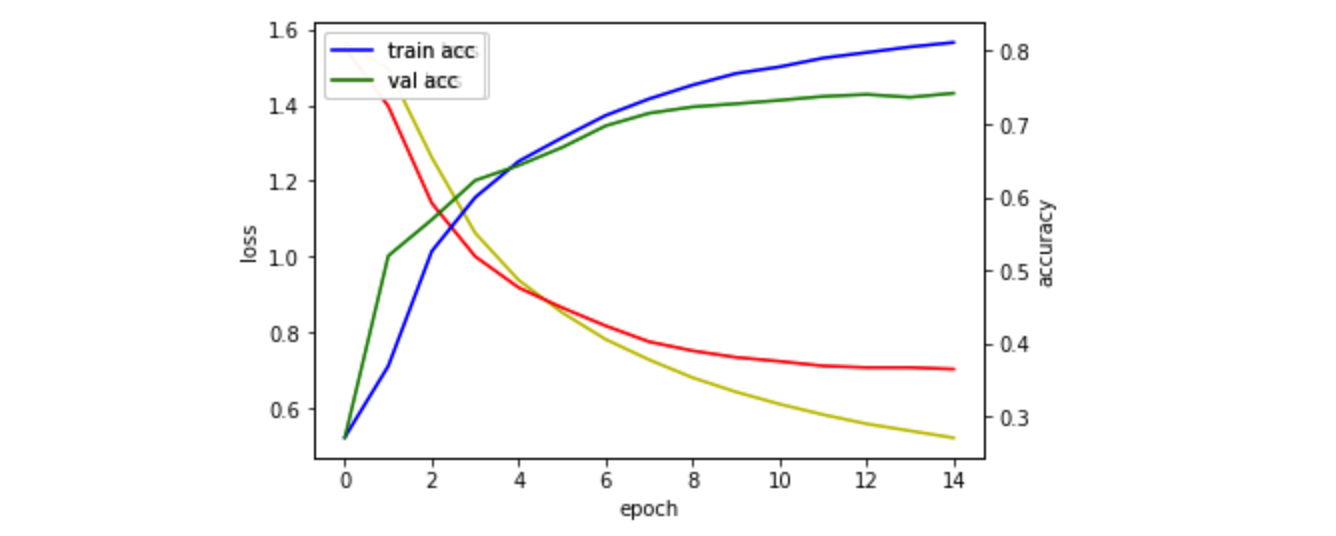
결과 도출
# predict values
sample_submission = pd.read_csv("./sample_submission.csv")
pred = model27.predict_proba(test_padded)
sample_submission[['0','1','2','3','4']] = pred
sample_submission.to_csv('submission_18.csv', index = False, encoding = 'utf-8')
DACON 제출 결과

와우! 0.4455598506 으로 오늘도 5일차의 결과보다 더 좋은 결과가 나왔습니다.
그러나 아직 데이터를 EDA 해보거나 하지 않고 이 모델 저 모델 도전을 해보고 있는 실정이라
아직 마음에 들지 않습니다.
아직 해보기로 했던 표제어 추출 전처리도 시도해보아야하고
각 라벨별로는 각각 몇 개의 데이터가 존재하는지도 확인해봐야하고
각 라벨별 그룹에는 어떤 단어들이 가장 많이 나왔는지도 확인해봐야합니다.
주말에 차차 차근차근 하나씩 해보고자 합니다.
읽어주셔서 감사합니다.
'DACON > 소설 작가 분류 AI 경진대회' 카테고리의 다른 글
| [DACON] 소설 작가 분류 AI 경진대회 7일차! (0) | 2020.11.05 |
|---|---|
| [DACON] 소설 작가 분류 AI 경진대회 N일차! (0) | 2020.11.05 |
| [DACON] 소설 작가 분류 AI 경진대회 5일차! (0) | 2020.11.03 |
| [DACON] 소설 작가 분류 AI 경진대회 4일차! (0) | 2020.11.02 |
| [DACON] 소설 작가 분류 AI 경진대회 1, 2, 3일차! (0) | 2020.11.01 |



