
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- AI 경진대회
- SW Expert Academy
- 금융문자분석경진대회
- Kaggle
- programmers
- 코로나19
- 캐치카페
- 편스토랑
- hackerrank
- ChatGPT
- 우분투
- 편스토랑 우승상품
- PYTHON
- ubuntu
- 프로그래머스 파이썬
- leetcode
- 백준
- github
- Docker
- 파이썬
- 더현대서울 맛집
- gs25
- 자연어처리
- Baekjoon
- 데이콘
- Real or Not? NLP with Disaster Tweets
- Git
- 프로그래머스
- dacon
- 맥북
- Today
- Total
솜씨좋은장씨
프로그래머스 2020 Dev-Matching : 머신러닝(자연어 처리) 개발자 과제 도전기! 본문
프로그래머스 2020 Dev-Matching : 머신러닝(자연어 처리) 개발자 과제 도전기!
솜씨좋은장씨 2020. 3. 5. 17:49

2020년! 프로그래머스에서 자연어처리 여러 회사들과 연계하여 자연어처리 개발자를 채용하는
Dev-Matching 챌린지가 열렸습니다.
마침 멀티캠퍼스 자연어처리 과정을 마치고 쿠팡 상차 아르바이트를 하며 취업을 준비하고 있던
저에게 열정을 불태울 만한 기회가 생겼습니다.
이 Dev-Matching은
11개 회사 중에서 5개 회사 서류 접수 -> 사전 과제 -> 코딩테스트 ( 과제 통과 인원들 ) -> 지원한 회사 중 합격한 회사 면접
순으로 일정이 진행되었습니다.
먼저 서류를 제출하고 과제를 열심히 기다렸습니다.
2월 1일! 드디어 과제가 오픈되었습니다.

과제의 내용은 해시코드라는 개발 관련 질문과 답변이 올라오는 홈페이지의 질문 글을
자동으로 분류할 수 있는 모델을 만드는 것이었습니다.
이 글이 5개의 언어 중에서 어떤 언어에 관련된 질문인지를 분류하면 되는 문제였습니다.
그동안 금융문자분석경진대회도 도전해봤고 기사내용을 긍정인지 중립인지 부정인지 분류하는 것도 해보아
처음에는 자신이있으면서도 한글과 프로그래밍 코드가 공존하는 데이터로 결과가 잘 나올까라는 걱정도 있었습니다.
도전해 본 방법 들
형태소분석기 - Mecab, Okt, nltk
데이터전처리 - 한국어를 영어로 번역
모델 - BERT, LSTM, Bi-LSTM, CNN, CNN-LSTM,
가장 성능이 좋았던 방법
형태소 분석 Okt + CNN-LSTM 모델
결과
공개 리더보드 공동 34위

파이널 리더보드 공동 14위

진행환경은 Google Colab - GPU 환경에서 진행하였습니다.
먼저 Konlpy와 Mecab을 설치해주었습니다.
! git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.gitcd Mecab-ko-for-Google-Colab/!bash install_mecab-ko_on_colab190912.sh
그 다음 내 구글 드라이브에 있는 데이터 파일에 접근하기 위해서 드라이브에 마운트 시키고 파일이 있는 디렉토리로 이동해 주었습니다.
import os, sys
from google.colab import drive
drive.mount('/content/mnt')
nb_path = '/content/notebooks'
os.symlink('/content/mnt/My Drive/Colab Notebooks', nb_path)
sys.path.insert(0, nb_path)cd /content/mnt/My Drive/Colab Notebooks/devmatcing
pandas의 read_csv 메소드를 활용하여 데이터를 load 해주었습니다.
import pandas as pd
train = pd.read_csv("2020_train.csv")
test = pd.read_csv("2020_test.csv")
불러온 데이터를 Konlpy의 Okt 형태소 분석기를 활용하여 토큰화 시켜주었습니다.
from konlpy.tag import Okt
okt = Okt()stopwords = ['의', '가', '이', '은', '들', '는', '좀', '잘', '걍', '과', '도', '를', '으로', '자', '에', '와', '한', '하다']from tqdm import tqdm
X_train = []
for i in tqdm(range(len(train['content']))):
temp_X = []
temp_X = okt.morphs(str(train['content'].iloc[i]).replace("/", '')) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
temp_X = [word for word in temp_X if len(word) > 1]
X_train.append(temp_X)X_test = []
for i in tqdm(range(len(test['content']))):
temp_X = []
temp_X = okt.morphs(test['content'].iloc[i]) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
temp_X = [word for word in temp_X if len(word) > 1]
X_test.append(temp_X)
라벨은 5가지 종류로 분류하기위해서 0,0,0,0, 1 부터 1, 0, 0, 0, 0까지 One-Hot Encoding을 실시해 주었습니다.
from keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(train['label'])):
if train['label'].iloc[i] == 1:
y_train.append([1, 0, 0, 0, 0])
elif train['label'].iloc[i] == 2:
y_train.append([0, 1, 0, 0, 0])
elif train['label'].iloc[i] == 3:
y_train.append([0, 0, 1, 0, 0])
elif train['label'].iloc[i] == 4:
y_train.append([0, 0, 0, 1, 0])
elif train['label'].iloc[i] == 5:
y_train.append([0, 0, 0, 0, 1])
y_train = np.array(y_train)
빈도수 상위 35,000개의 단어를 유지하며 정수인코딩을 실시합니다.
from keras.preprocessing.text import Tokenizer
max_words = 35000
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)
데이터의 각 문자의 최대길이와 평균 길이를 구해보았습니다.
import matplotlib.pyplot as plt
print("문자의 최대 길이 :" , max(len(l) for l in X_train_vec))
print("문자의 평균 길이 : ", sum(map(len, X_train))/ len(X_train_vec))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()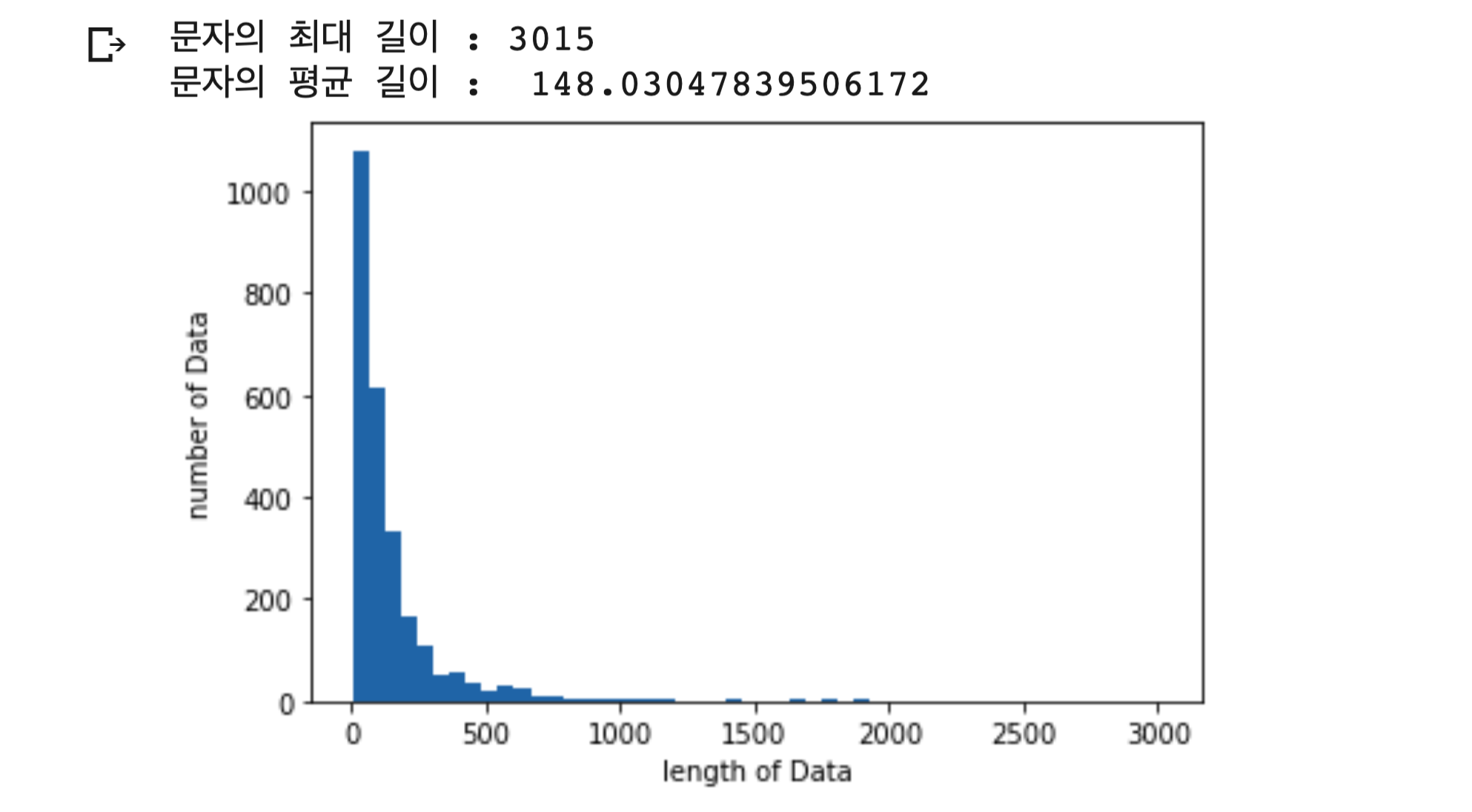
문자의 최대길이는 3,015 평균길이는 148임을 알 수 있습니다.
필요한 레이어와 모델을 import 해주었습니다.
from keras.layers import Embedding, Dense, LSTM, Bidirectional, Dropout, Conv1D, GlobalMaxPooling1D, MaxPooling1D
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
각각의 데이터가 다 다른길이를 가지고 있으므로 pad_sequences를 활용하여 모두 같은 길이로 통일시켜 주었습니다.
max_len = 148 # 전체 데이터의 길이를 380로 맞춘다
X_train_vec = pad_sequences(X_train_vec, maxlen=max_len)
X_test_vec = pad_sequences(X_test_vec, maxlen=max_len)
CNN-LSTM 모델을 사용했습니다.
model31 = Sequential()
model31.add(Embedding(max_words, 128, input_length=148))
model31.add(Dropout(0.2))
model31.add(Conv1D(256, 3, padding='valid', activation='relu', strides=1))
model31.add(MaxPooling1D(pool_size=4))
model31.add(LSTM(128))
model31.add(Dense(5, activation='softmax'))
model31.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history31 = model31.fit(X_train_vec, y_train, epochs=10, batch_size=32, validation_split=0.1)
예측결과를 만들어 제출하였습니다.
predict = model31.predict(X_test_vec)
predict_labels = np.argmax(predict, axis=1)
for i in range(len(predict_labels)):
predict_labels[i] = predict_labels[i] + 1
submission_dic = {"label":predict_labels}
submission_df = pd.DataFrame(submission_dic)
submission_df.to_csv("dev_matching_51.csv", index=False)
위의 방법이 가장 좋았습니다.
위의 방법으로 다행히도 첫번째 과제를 통과하였고 코딩테스트에 참가할 수 있었습니다.

그외 도전했던 방법들
1. 훈련데이터와 학습데이터를 네이버 파파고 번역 api를 활용하여 영어로 번역하고 okt를 통해 토큰화 한 뒤 학습
import os
import sys
import urllib.request
import json
from tqdm import tqdm
client_id = "client_id"
client_secret = "client_secret"
text_list = list(train['content'])
translatedText = []
error_index = []
for i in tqdm(range(len(text_list))):
try:
encText = urllib.parse.quote(str(text_list[i]).replace("/", '').replace('\n', ''))
data = "source=ko&target=en&text=" + encText
url = "https://naveropenapi.apigw.ntruss.com/nmt/v1/translation"
request = urllib.request.Request(url)
request.add_header("X-NCP-APIGW-API-KEY-ID",client_id)
request.add_header("X-NCP-APIGW-API-KEY",client_secret)
response = urllib.request.urlopen(request, data=data.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
# print(response_body.decode('utf-8'))
transText = json.loads(response_body.decode('utf-8'))['message']['result']['translatedText']
translatedText.append(transText)
else:
print("Error Code:" + rescode)
except:
translatedText.append(str(text_list[i]).replace("/", '').replace('\n', ''))
print("Error so append raw data")
error_index.append(i)
print(len(translatedText), len(error_index))
번역에 약 1시간 30분의 소요시간이 걸렸습니다.

이렇게 번역한 데이터를 가지고 Okt를 활용해 토큰화한뒤 워드클라우드를 그려주면 위의 그림과 같았습니다.
하지만 이방법에는 문제점이 있었습니다.
네이버 클라우드 플랫폼의 토큰을 6만개나 사용하였고 시간도 오래걸렸으나 중간중간 api가 처리하지 못하는 문자들이 들어가 있었고
이로 인하여 제대로 번역이 되지 않는 경우들이 존재했습니다.
처음에는 영어라면 조금 더 좋은 성능을 낼 수 있지 않을까 기대를 하였으나 위와 같은 이유로 성능이 잘 나오지 않았던 것으로 사료됩니다.
2. 김웅곤님께서 공유해주신 Keras Bert를 활용한 방법
한국인공지능 아카데미 실용교육 BERT 편에서 김웅곤 강사님께서 공유해주신 Keras Bert를 활용해서도 도전해보았습니다.
kimwoonggon/publicservant_AI
Contribute to kimwoonggon/publicservant_AI development by creating an account on GitHub.
github.com
이진 분류를 하게끔 되어있는 코드를 5개의 카테고리로 분류하도록 바꾸어 도전해보았습니다.
def get_bert_finetuning_model(model):
inputs = model.inputs[:2]
dense = model.layers[-3].output
outputs = keras.layers.Dense(5, activation='softmax',kernel_initializer=keras.initializers.TruncatedNormal(stddev=0.02),
name = 'real_output')(dense)
bert_model = keras.models.Model(inputs, outputs)
bert_model.compile(
optimizer=RAdam(learning_rate=0.00001, weight_decay=0.0025),
loss='categorical_crossentropy',
metrics=['accuracy'])
return bert_modelfrom keras.utils import np_utils
import numpy as np
y_train = []
for i in range(len(train['label'])):
if train['label'].iloc[i] == 1:
y_train.append([1, 0, 0, 0, 0])
elif train['label'].iloc[i] == 2:
y_train.append([0, 1, 0, 0, 0])
elif train['label'].iloc[i] == 3:
y_train.append([0, 0, 1, 0, 0])
elif train['label'].iloc[i] == 4:
y_train.append([0, 0, 0, 1, 0])
elif train['label'].iloc[i] == 5:
y_train.append([0, 0, 0, 0, 1])
y_train = np.array(y_train)sess = K.get_session()
uninitialized_variables = set([i.decode('ascii') for i in sess.run(tf.report_uninitialized_variables())])
init = tf.variables_initializer([v for v in tf.global_variables() if v.name.split(':')[0] in uninitialized_variables])
sess.run(init)
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=0, mode='auto')
bert_model2 = get_bert_finetuning_model(model)
history = bert_model2.fit(train_x, y_train, epochs=1000, batch_size=32, verbose = 1, validation_split=0.1, shuffle=True, callbacks=[early_stopping])
validation accuracy 기준 70%대에서 머무는 것을 볼 수 있었습니다.
공개 리더보드 결과도 최고 75점이상 올라가지 못했습니다.
파이널 리더보드 결과 14위!

여기서는 데이터 양이 너무 적고 정제가 되지 않은 데이터를 사용하여 기대한 만큼은 정확도가 좋지 못했던 것 같습니다.
프로그래머스에서 정말 좋은 기회를 만들어주셔서 면접도 보고 좋은 경험을 할 수 있었던 것 같습니다.
앞으로도 이런 재밌고 좋은 챌린지들이 많이 생겼으면 좋겠습니다.
읽어주셔서 감사합니다!