
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- PYTHON
- 프로그래머스
- 백준
- leetcode
- SW Expert Academy
- 편스토랑 우승상품
- gs25
- 맥북
- dacon
- 금융문자분석경진대회
- 편스토랑
- AI 경진대회
- Baekjoon
- Git
- github
- Kaggle
- Docker
- programmers
- 더현대서울 맛집
- 캐치카페
- 프로그래머스 파이썬
- ChatGPT
- 자연어처리
- hackerrank
- 코로나19
- 우분투
- ubuntu
- 파이썬
- 데이콘
- Real or Not? NLP with Disaster Tweets
- Today
- Total
솜씨좋은장씨
[Keras]영화 평점, 줄거리를 가지고 평점 예측 모델 만들어보기 본문

1. 이 주제를 선정하게 된 계기
개인프로젝트로 어떤 것을 해볼까 고민하면서 처음에는 영화를 추천해주는 챗봇을 만들어 보려고 했다가 더 공부를하고 만들기로 하고 하루라는 짧은 시간안에 구현해볼 수 있는 다른 주제가 무엇이 있나 찾던 중, 제가 평소에 자주 이용하는 왓챠라는 페이지에서 제가 봤던 영화들 목록과 평점과 같은 데이터를 가지고 새로운 영화가 나왔을 때 내가 시청하고 나서 어떤 점수를 부여할 것인지 예측해주는 시스템이 떠올랐습니다.

제가 왓챠에 제공하는 데이터는 제가 봤던 영화의 목록과 그 영화에 부여하는 평점 정보 뿐인데 어떻게 아직 개봉하지 않은 영화들의 평점을 예측해서 보여주는가 고민을 해보았습니다. 고민하다가 떠올랐던 것이 제가 봤다고 한 영화의 줄거리와 그 영화에 부여된 평점, 그리고 장르 이 세 가지를 가지고 학습을하여 새로운 영화 데이터가 들어왔을때 학습되어있던 모델을 적용하여 예측을 해주는 것이 아닐까 하는 생각이 들었습니다.
직접 한 번 구현해보기로 생각했고 네이버 영화에서 영화 제목, 줄거리, 영화에 사람들이 부여한 평점들의 평균 평점, 장르 데이터를 먼저 크롤링해와야겠다는 생각을 했습니다.
2. 데이터 수집하기
데이터는 네이버 시리즈에서
카테고리 > 최신영화 > 판매순 항목으로 들어가 나오는 영화목록 속의 영화 줄거리, 장르, 제목 정보를 가져왔습니다.
가져왔던 과정은 아래에서 자세하게 볼 수 있습니다.
[Python]네이버 영화 데이터 크롤링하기
과거의 영화 줄거리, 평점, 장르 데이터를 가지고 새로운 영화의 평점을 예측하는 모델을 만들 때 학습데이터로 사용하기 위한 데이터들을 크롤링해오기 위한 코드를 짜 보았습니다. 데이터를 수집하기 위한 크롤..
somjang.tistory.com
3. 데이터 가공하기
먼저 크롤링해서 모은 csv 파일을 터미널에서 cat명령어를 통해서 하나로 합쳤습니다.
$ cat movie_data* >> movie_infomations.csv 그럼 movie_data가 들어간 파일 모두가 movie_infomations.csv로 합쳐지게 됩니다.
파일을 열어 하나로 잘 합쳐졌는지 확인해봅니다.

쭉 아래로 내리면서 확인을 해보니 크롤링 과정에서 잘못받아오거나 파일을 합치는 과정에서 생긴 필요없는 데이터들이 포함되어있었습니다.
먼저 줄거리를 기준으로 중복되는 내용이 있다면 앞의 row를 남기고 후에 같은 내용을 담고있는 row들을 제거해줍니다.
movie_df = movieDataFrame.drop_duplicates("plot", keep='first')
movie_df.info()
파일을 하나로 합치는 과정에서 column값이 여러 번 들어가있는 경우

이 경우는 DataFrame으로 csv내의 정보를 받아온 후
DataFrame의 평점 정보가 담겨있는 column에서 값을 확인하여
'평점'이라는 값이 들어가있는 row를 제외하고 나머지는 유지하도록 하였습니다.
movieDataFrame = movieDataFrame[movieDataFrame.score != "평점"]
movieDataFrame[31:40]
크롤링을 하면서 장르 데이터를 가져와야하는데
nth-child(여러 태그 중 데이터가 담겨있는 태그의 순서) 방식을 사용하다 보니 장르가 아닌 다른 것이 들어가 있는 경우

이 경우를 보니 장르대신에 잘못 들어가 있는 값들이 감독에 대한 정보였고
저장되어있는 형태가 '감독~~~' 이러한 형태인 것을 확인할 수 있었습니다.
이 경우는 장르데이터 중에 '감독' 이라는 단어를 포함한 row를 제외한 나머지를 유지하도록 하였습니다.
indexs = []
for idx in movie_df.index:
if movie_df.loc[idx]['gerne'].find('감독') != -1:
indexs.append(idx)
movie_df2 = movie_df.drop(indexs, axis=0)
동일한 방법으로 ['']값이 들어가 있는 경우도 제거해 주었습니다.

indexs = []
for idx in movie_df2.index:
if len(movie_df2.loc[idx]['gerne']) == 0 or movie_df2.loc[idx]['gerne'] == "['']":
indexs.append(idx)
print(indexs)
movie_df2 = movie_df2.drop(indexs, axis=0)
줄거리 데이터가 없는 경우

크롤링을 하는 과정에서 웹사이트에 줄거리가 올라와있지 않은 경우 예외처리를 통해 줄거리 오류라는 단어를 넣기로 했습니다.
그러한 데이터를 찾아 제거하였습니다.
movieDataFrame = movieDataFrame[movieDataFrame['plot'] != '줄거리 오류']
장르의 ['액션'] 이라고 저장되어있는 값에서 액션 만 추출하기
for idx in movie_df2.index:
temp = movie_df2.loc[idx]['gerne']
temp = temp.split(',')
temp = temp[0]
temp = temp.replace('[', '')
temp = temp.replace(']', '')
temp = temp.replace("\'", '')
movie_df2.loc[idx]['gerne'] = temp
이것 저것 처리하고 나니 9278개의 데이터에서 5132개의 데이터로 줄어들었습니다.
조금 더 나은 형태소 분석을 위해서 줄거리에서 정규식을 통해 특수문자를 제거한 후 pandas의 Series로 만들어주고
'clean_plot'이라는 이름으로 새로운 column을 만들고 넣어줍니다.

4. 모델 만들고 학습, 평가해보기
처음에는 장르, 줄거리를 바탕으로 평점을 예측하고 싶었으나
아직 공부가 더 필요하여 줄거리 데이터를 가지고 평점을 예측하는 방향으로 변경하였습니다.
모델은 Wikidocs의 로이터 뉴스 분류하기의 모델에서 하이퍼 파라미터를 바꾸어 진행해보았습니다.
추후 공부를 통해서 직접 만들어서 진행해보고자 합니다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
x_data = movie_df3['clean_plot']
y_data = movie_df3['score']먼저
x_data로는 특수문자를 제거한 줄거리를 넣어주고
y_data로는 그 줄거리를 가진 영화의 평점을 넣어주었습니다.
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_data)
sequences = tokenizer.texts_to_sequences(x_data)위의 코드를 활용하여 줄거리를 토큰화하고 각각의 토큰을 숫자로 변경하였습니다.

어떤 숫자가 어떤 단어인지는 tokenizer.word_index로 확인이 가능합니다.

print('줄거리의 최대 길이 : {}'.format(max(len(l) for l in x_data)))
print('줄거리의 평균 길이 : {}'.format(sum(map(len, x_data)) / len(x_data)))
plt.hist([len(s) for s in x_data], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()위의 코드를 활용하여 줄거리의 최대 길이, 평균길이를 확인해보고
내가 가진 줄거리 데이터들이 어느정도의 길이분포를 가지고 있는지 그래프로 확인해보았습니다.

from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.preprocessing import sequence
from keras.utils import np_utils
max_len = 250
x_data = pad_sequences(x_data, maxlen=max_len)
y_data = np_utils.to_categorical(y_data)x_data의 길이를 모두 통일시키고
y_data는 원-핫 인코딩해줍니다.

모델을 만들고 학습을 시켰습니다.
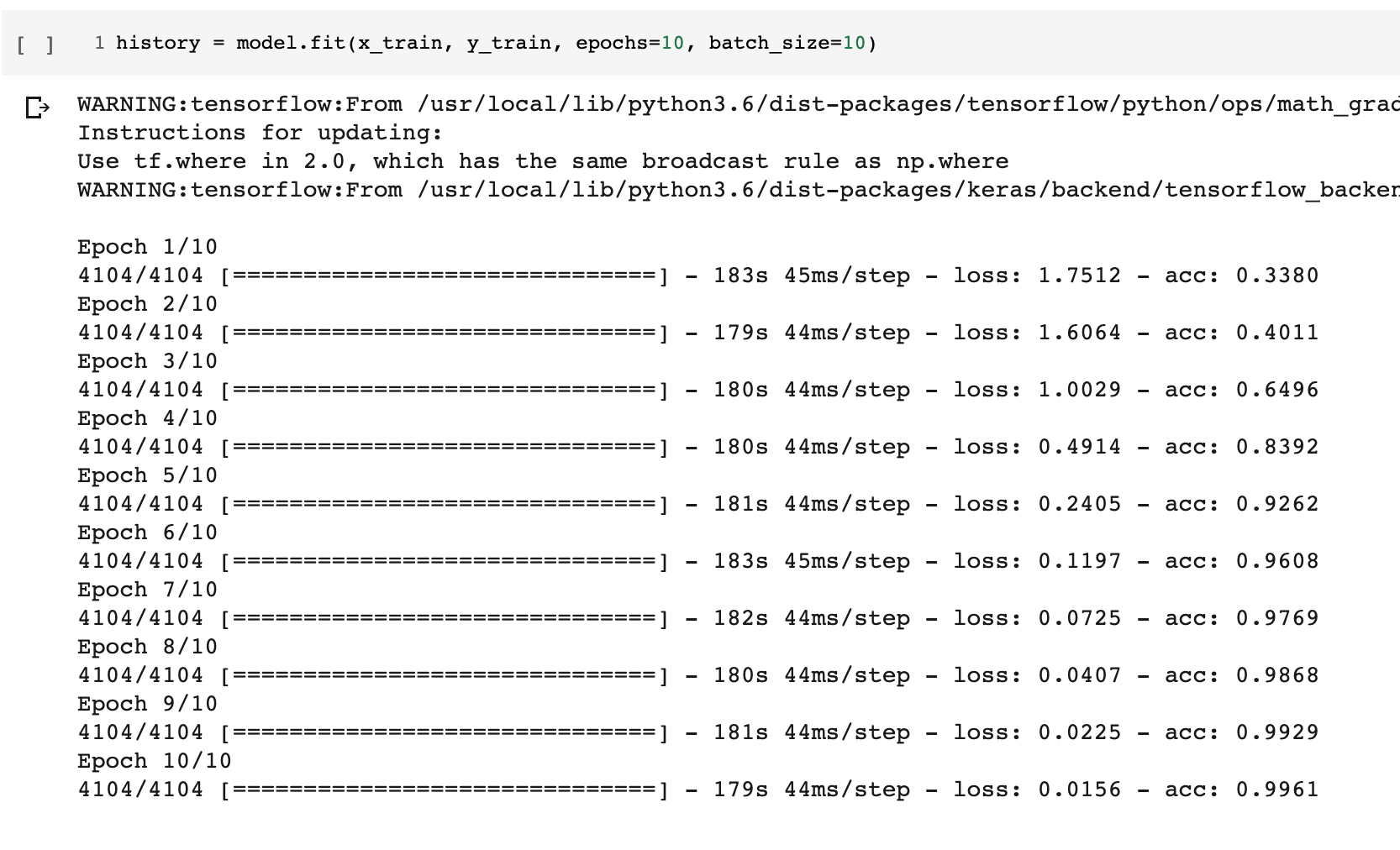
처음에는 학습결과가 99.61퍼센트가 나오기에 어 뭐지 왜이렇게 결과가 좋게 나오는 거지?
생각하고 평가를해보니 결과는?
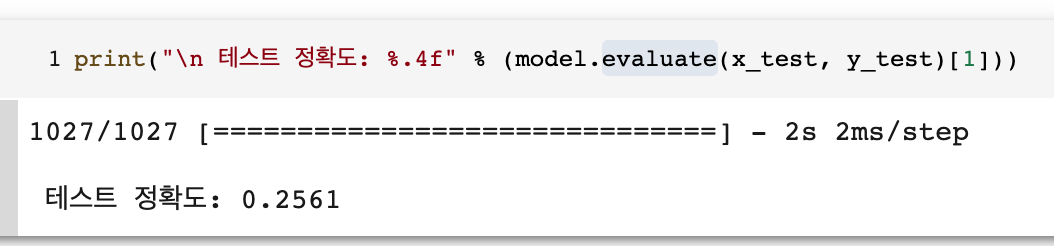
25.6퍼센트라는 처참한 결과가......
왜 그런지 알아보기 위해서 제가 가지고 있는 데이터를 평점별로 몇 개씩 있는지 그래프로 그려보니

데이터가 6~9사이에 몰려있는 것을 볼 수 있었습니다.
여기서 떠오른 점은 데이터가 6~9사이에 편향되어있는 데이터를 학습시켜 후에 0~5, 10 데이터들을 보았을때 제대로 예측하지 못하는 것 같았습니다.
5. 느낀점 & 앞으로의 계획
크롤러를 만들면서는 에러가 나는 상황, 예외적인 상황들에 대한 예외처리가 정말 중요함을 느꼈습니다. 처음에 완벽하게 구현했다고 생각하고 400페이지 정도의 데이터를 한번에 받아오고자 실행을 눌렀습니다. 그러나 줄거리가 없는 경우 데이터를 받아오지 않았고 데이터 프레임으로 만들 딕셔너리를 만들때 각 평점 리스트, 제목 리스트, 줄거리 리스트의 길이가 달라 오류가 났습니다. 결국 2시간이 기다렸다가 결과를 보았을땐 오류만을 볼 수 있었습니다.....
그리고 데이터를 학습시킬 때 너무 편향되어있는 데이터를 가지고 학습을 시키게되면 학습을 시키지 못한 데이터는 정확성이 떨어지는 것을 보았습니다. 데이터를 수집할때 조금 고르게 분포될 수 있도록 해야할 것도 같습니다.
여러가지를 해보긴 했는데 아직 책에 있는 내용을 배껴서 해보는 수준밖에 되지 않았습니다. 앞으로 자연어처리, 케라스에 대해서 더 공부해보고 많은 것들을 해보고 싶습니다.
'머신러닝 | 딥러닝 > TensorFlow | Keras' 카테고리의 다른 글
| [TF2.0] Tensorflow 2.0 GPU 사용 가능 여부 확인하기 (0) | 2020.10.06 |
|---|---|
| [TensorFlow] ImportError: libcusolver.so.8.0: cannot open shared object file: No such file or directory 해결 방법 (0) | 2020.07.20 |
| [TF2.0] MNIST - ValueError: Shapes (32, 10) and (32, 1) are incompatible 해결 방법 (10) | 2020.06.28 |
| [Keras]기사 제목을 가지고 긍정 / 부정 / 중립으로 분류하는 모델 만들어보기 (56) | 2019.10.07 |
| [Keras]Keras에서 Model이란(feat, 레고블럭) (0) | 2019.09.13 |



