
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 맥북
- AI 경진대회
- ChatGPT
- Git
- 자연어처리
- Baekjoon
- 파이썬
- 프로그래머스 파이썬
- 백준
- 프로그래머스
- Kaggle
- gs25
- 코로나19
- 캐치카페
- programmers
- 데이콘
- leetcode
- 우분투
- dacon
- ubuntu
- hackerrank
- 편스토랑
- Docker
- SW Expert Academy
- Real or Not? NLP with Disaster Tweets
- 금융문자분석경진대회
- 더현대서울 맛집
- github
- 편스토랑 우승상품
- PYTHON
- Today
- Total
솜씨좋은장씨
[Python] Selenium과 BeautifulSoup을 활용하여 네이버 뉴스 기사 크롤링하는 방법! 본문
[Python] Selenium과 BeautifulSoup을 활용하여 네이버 뉴스 기사 크롤링하는 방법!
솜씨좋은장씨 2022. 1. 15. 19:08

👨🏻💻 네이버 뉴스 기사 수집을 부탁해!
마케팅 / 홍보 대행 회사에서 인턴을 하는 친구가 업무를 받았는데 특정 기업에 대한 O월 O일 ~ O월 O일 까지의
네이버 뉴스 기사를 수집하고 각각의 기사가 기획 기사인지, 부정 기사인지 분류를 해야하는데
수집해야 할 뉴스기사가 너무 많다며 혹시 프로그래밍으로 수집 할 수 있는 방법이 있는지! 물어보았습니다.
🤩 기사 수집이라면 당근!
크롤링이라면 또 제 전문 분야 이기에 시간이 될 때 도와 주기로 하였고
간단하게 기사 제목, 기사의 url, 언론사, 기사가 올라온 날짜 이렇게 4가지를 크롤링하는 코드를 작성하여
12월 1달 간의 기사를 크롤링해서 전달해 주었습니다.
이번 글에서는 그때 작성했던 코드에서 조금 개선하여 공유해보려 합니다.
요구사항
특정 회사를 네이버 뉴스에 검색했을때 나오는 O월 O일 ~ O월 O일 사이의 모든 기사를 수집해달라
수집내용은 기사 제목, 언론사, 기사 날짜, 기사 제목
🤔 사람이 이걸 직접 한다면?
만약 사람이 직접 토스라는 기업의 2022년 1월 1일 ~ 1월 4일 사이의 모든 기사라고 한다면
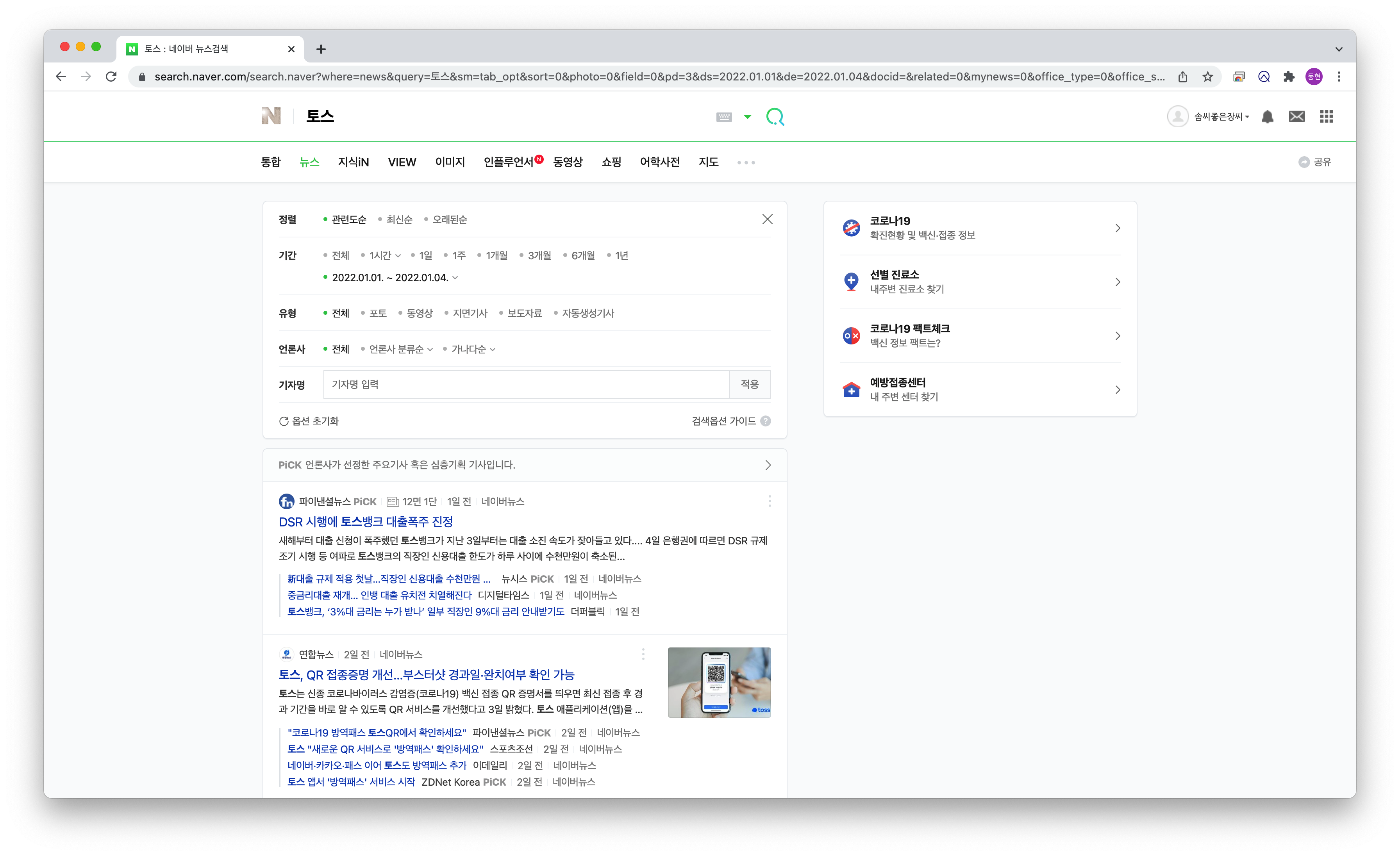
네이버에서 토스를 검색하고 뉴스 탭으로 이동한 다음
검색 옵션을 펼쳐 기간을 2022년 1월 1일 ~ 1월 4일로 설정하여 검색을 한 뒤에
첫 기사부터 하나씩 제목 복사하고, 언론사 보고 적고 기사 url 복사해서 수집할겁니다.
🤔 그럼 개발은 어떤 방식으로 하지?
크롤링을 통한 기사수집도 사람이 하는 것과 동일하게 2022년 1월 1일 ~ 1월 4일로 날짜를 설정하고
첫 기사부터 하나씩 제목, 언론사, 기사 url을 수집 하면됩니다.
여기서 하나 생각을 한 것이 1월 1일 ~ 1월 4일을 한번에 설정하여 기사를 크롤링하는데
1월 1일 부터 3일까지 잘 수집해오다가 4일 중반에 갑자기 인터넷이 끊긴다거나 하는 이유로 크롤링이 멈추게 되면
그사이 수집한 1월 1일 ~ 1월 3일 사이의 데이터는 모두 날아가게 되므로
만약 기사를 수집하고 저장해야하는 날짜가 1월 1일 ~ 1월 31일 이라면
1월 1일 ~ 1월 1일 ( 1월 1일 하루 기사 ) 크롤링 -> 엑셀 파일로 저장
1월 2일 ~ 1월 2일 ( 1월 2일 하루 기사 ) 크롤링 -> 엑셀 파일로 저장
...
1월 31일 ~ 1월 31일 ( 1월 31일 하루 기사 ) 크롤링 -> 엑셀 파일로 저장
=> 1월 1일 ~ 1월 31일 크롤링 데이터 합병위와 같이 하루 단위로 수집 -> 저장 하는 방식으로 개발 해야겠다고 생각했습니다.
👏 개발 환경 설정
👨🏻💻 필자 개발 환경
- 맥북 프로 2017 13인치 or 펜티엄 데스크탑
- 언어 : Python 3.7.3 / 사용 라이브러리 : Selenium / BeautifulSoup / Pandas
- 코드 작성 : Jupyter Notebook
- 브라우저 : Chrome ( 크롬 )
👨🏻💻 개발 환경 설정 - Python 과 필요 라이브러리 설치
본격적인 개발을 위해서는 Python과 각종 필요 라이브러리 등을 설치해주어야 합니다.
아래의 글을 참고하셔도 좋고 다른 개발 글을 참고하셔도 좋습니다.
저는 코드 작성을 Jupyter notebook 에서 진행하였는데 다른
1. Python 설치 - ( Windows 의 경우 환경 변수 설정 )
2019.09.07 - [Programming/Python] - [Python]Ubuntu에 Python 3.7 설치하기!
[Python]Ubuntu에 Python 3.7 설치하기!
1. Python 설치 전 라이브러리 설치하기 Ubuntu(또는 Putty)에서 터미널을 열어 아래의 코드를 입력합니다. 설치 중간 중간에 [ y | n ] 중에 고르라고 나오면 y를 타이핑하고 엔터를 해주시면 됩니다! $ s
somjang.tistory.com
2. Selenium과 BeautifulSoup 라이브러리 설치
$ pip install selenium$ pip install bs4$ pip install lxml3. Selenium 크롬 드라이버 다운로드
2019.09.14 - [유용한 정보/Windows] - [Windows]Windows10에 Selenium설치하기(20.2.13 업데이트)
[Windows]Windows10에 Selenium설치하기(20.2.13 업데이트)
1. 구글 크롬 최신으로 업데이트하기 먼저 크롬의 맨 우측 상단의 세 개의 점을 클릭하여 크롬의 설정페이지로 들어갑니다. 왼쪽 메뉴에서 Chrome 정보를 클릭하여 업데이트를 실시합니다. 다시시
somjang.tistory.com
라이브러리를 모두 설치하였다면 Selenium 크롬 드라이버를 다운로드 받습니다.
다운로드 받은 후 해당 파일의 경로를 잘 확인해둡니다.
4. 그 외 필요 라이브러리 설치
Pandas : 크롤링한 결과를 엑셀로 만들때 사용할 라이브러리
$ pip install pandastqdm : 진행상황을 보기 위해 사용할 라이브러리
$ pip install tqdm📻네이버 뉴스 페이지 분석하기
👨🏻💻 URL 분석
먼저 크롤링을 희망하는 페이지의 URL을 분석했습니다.
https://search.naver.com/search.naver?where=news&query=%ED%86%A0%EC%8A%A4&sm=tab_opt&sort=0&photo=0&field=0&pd=3&ds=2022.01.13&de=2022.01.13&docid=&related=0&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so%3Ar%2Cp%3Afrom20220113to20220113&is_sug_officeid=0
위와 같이 토스 키워드에 대해서 관련도순으로 정렬한 페이지의 url을 하나하나 뜯어보면
https://search.naver.com/search.naver?
where=news
&query=%ED%86%A0%EC%8A%A4 # 검색어 : 토스
&sm=tab_opt
&sort=0 # 관련도순 정렬 # 최신순 1 # 오래된 순 2
&photo=0
&field=0
&pd=3
&ds=2022.01.13 # 시작일
&de=2022.01.13 # 종료일
&docid=&related=0
&mynews=0
&office_type=0
&office_section_code=0
&news_office_checked=&nso=so%3Ar%2Cp%3Afrom20220113to20220113
&is_sug_officeid=0query 에 내가 검색을 희망하는 검색어 - ( 인코딩 된 값이 필요함 )
sort에 내가 희망하는 정렬 방식 - ( 관련도순 0 / 최신순 1 / 오랜된순 2 )
ds는 검색 희망 기간 시작일
de는 검색 희망 기간 종료일
이 URL 속에 포함되어있는 것을 알 수 있습니다.
👨🏻💻 네이버 뉴스 페이지 구성 요소 파악하기 - 크롬 개발자도구 활용
URL 만 알고 있어서는 원하는 값들만 크롤링으로 추출하기 어렵습니다.
코드를 작성하는 것 보다
내가 필요로하는 내용이 들어있는 항목들이 어떤 값들로 이루어져있는지 파악하는 것이 중요합니다.
이는 크롬의 개발자도구를 활용하면 쉽게 파악할 수 있습니다.
먼저 원하는 페이지에서 F12를 누르면 크롬의 개발자 도구가 열립니다.
만약 F12로 열리지 않는 다면 아래의 방법으로도 개발자 도구를 열 수 있습니다.
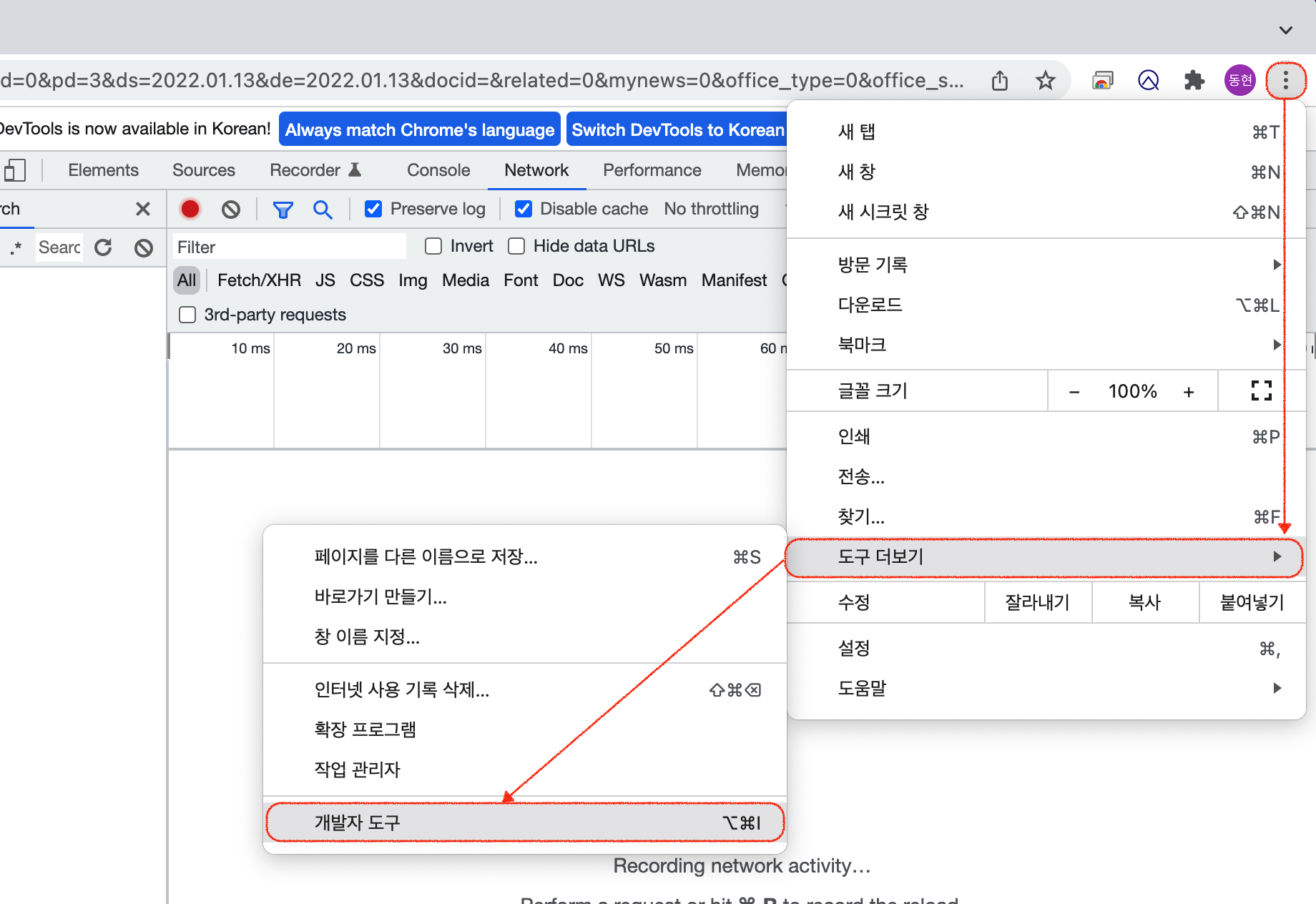
크롬 개발자 도구에서 화살표 모양의 버튼을 클릭하여 진행합니다.
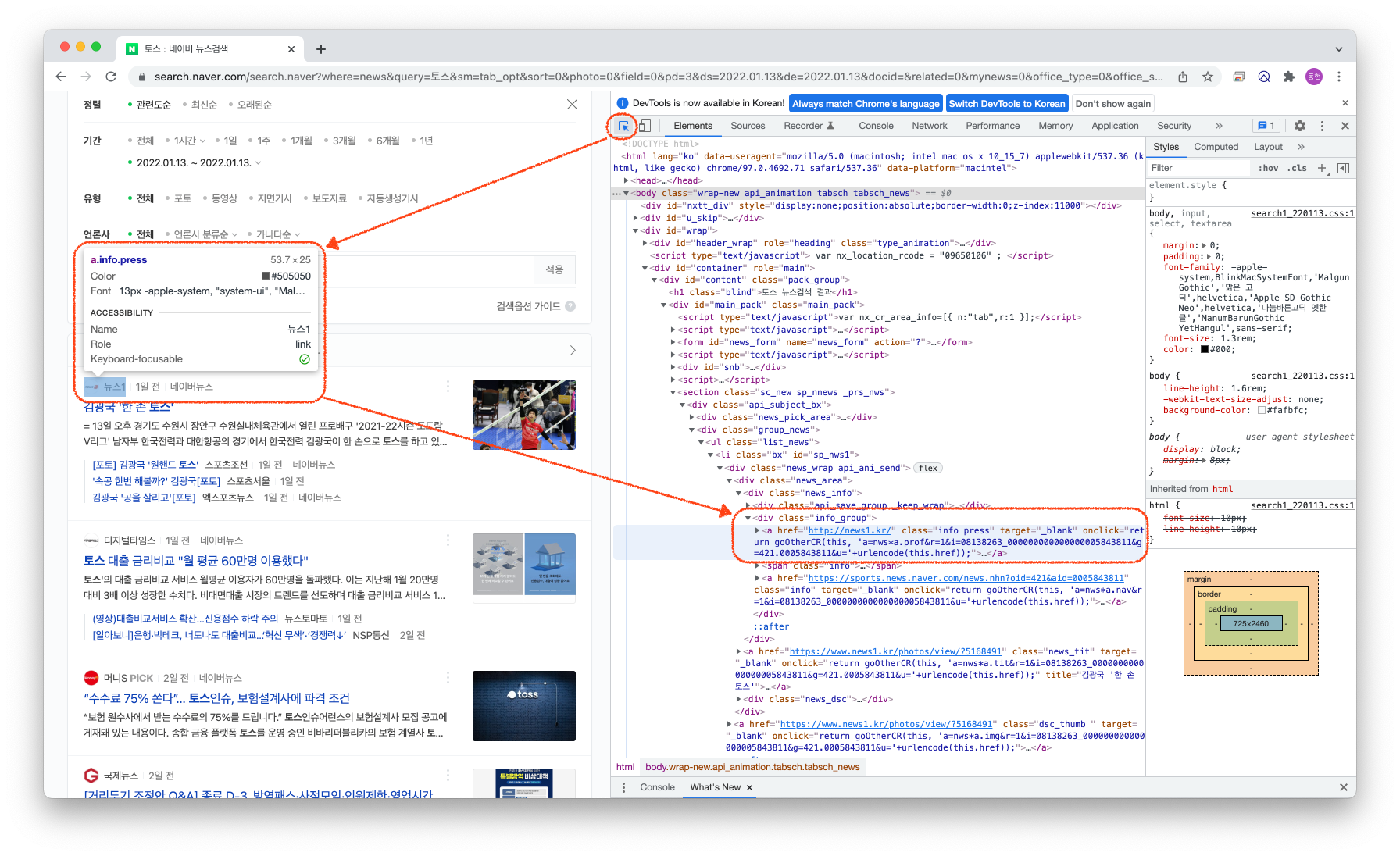
화살표 도구를 눌러 기능을 활성화하면 왼쪽의 내가 원하는 부분에 마우스를 가져다 댔을 때
해당 항목이 가지고 있는 클래스명이나 id 값 등을 확인할 수 있습니다.
저는 내용 추출을 위한 언론사, 기사 제목, 기사 URL 을 가져오는 부분과
다음 페이지로 이동하기 위한 화살표 부분을 확인하였습니다.
👨🏻💻 위의 방법으로 확인한 값
기사 정보 영역 부분 - div.news_area
제목 부분 - title
링크 부분 - href
언론사 부분 - div.info_group > a.info.press
또는 - div.info_group > span.info_press
다음 페이지 이동 버튼 - a.btn_next
- area-disabled 가 true 인 경우 더이상 클릭 불가😎Selenium과 BeautifulSoup를 활용하여 코드 작성하기
개발환경도 모두 설정했고
크롤링을 하려는 페이지의 구성요소 분석도 끝났다면 이제는 코드를 작성하는 것만 남았습니다.
from selenium import webdriver as wd
from bs4 import BeautifulSoup
import pandas as pd
import time
import urllib
def get_article_info(driver, crawl_date, press_list, title_list, link_list, date_list, more_news_base_url=None, more_news=False):
more_news_url_list = []
while True:
page_html_source = driver.page_source
url_soup = BeautifulSoup(page_html_source, 'lxml')
more_news_infos = url_soup.select('a.news_more')
if more_news:
for more_news_info in more_news_infos:
more_news_url = f"{more_news_base_url}{more_news_info.get('href')}"
more_news_url_list.append(more_news_url)
article_infos = url_soup.select("div.news_area")
if not article_infos:
break
for article_info in article_infos:
press_info = article_info.select_one("div.info_group > a.info.press")
if press_info is None:
press_info = article_info.select_one("div.info_group > span.info.press")
article = article_info.select_one("a.news_tit")
press = press_info.text.replace("언론사 선정", "")
title = article.get('title')
link = article.get('href')
# print(f"press - {press} / title - {title} / link - {link}")
press_list.append(press)
title_list.append(title)
link_list.append(link)
date_list.append(crawl_date)
time.sleep(2.0)
next_button_status = url_soup.select_one("a.btn_next").get("aria-disabled")
if next_button_status == 'true':
break
time.sleep(1.0)
next_page_btn = driver.find_element_by_css_selector("a.btn_next").click()
return press_list, title_list, link_list, more_news_url_list
def get_naver_news_info_from_selenium(keyword, save_path, target_date, ds_de, sort=0, remove_duplicate=False):
crawl_date = f"{target_date[:4]}.{target_date[4:6]}.{target_date[6:]}"
driver = wd.Chrome("./chromedriver") # chromedriver 파일 경로
encoded_keyword = urllib.parse.quote(keyword)
url = f"https://search.naver.com/search.naver?where=news&query={encoded_keyword}&sm=tab_opt&sort={sort}&photo=0&field=0&pd=3&ds={ds_de}&de={ds_de}&docid=&related=0&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so%3Ar%2Cp%3Afrom{target_date}to{target_date}&is_sug_officeid=0"
more_news_base_url = "https://search.naver.com/search.naver"
driver.get(url)
press_list, title_list, link_list, date_list, more_news_url_list = [], [], [], [], []
press_list, title_list, link_list, more_news_url_list = get_article_info(driver=driver,
crawl_date=crawl_date,
press_list=press_list,
title_list=title_list,
link_list=link_list,
date_list=date_list,
more_news_base_url=more_news_base_url,
more_news=True)
driver.close()
if len(more_news_url_list) > 0:
print(len(more_news_url_list))
more_news_url_list = list(set(more_news_url_list))
print(f"->{len(more_news_url_list)}")
for more_news_url in more_news_url_list:
driver = wd.Chrome("./chromedriver")
driver.get(more_news_url)
press_list, title_list, link_list, more_news_url_list = get_article_info(driver=driver,
crawl_date=crawl_date,
press_list=press_list,
title_list=title_list,
link_list=link_list,
date_list=date_list)
driver.close()
article_df = pd.DataFrame({"날짜": date_list, "언론사": press_list, "제목": title_list, "링크": link_list})
print(f"extract article num : {len(article_df)}")
if remove_duplicate:
article_df = article_df.drop_duplicates(['링크'], keep='first')
print(f"after remove duplicate -> {len(article_df)}")
article_df.to_excel(save_path, index=False)먼저 selenium을 활용하여 페이지의 html 소스를 가져온 뒤
beautifulsoup의 select, select_one, find_element_by_css_selector를 활용해서 값을 가져오고
selenium을 활용하여 계속 다음 페이지로 넘어가도록 했습니다.
from datetime import datetime
from tqdm import tqdm
def crawl_news_data(keyword, year, month, start_day, end_day, save_path):
for day in tqdm(range(start_day, end_day+1)):
date_time_obj = datetime(year=year, month=month, day=day)
target_date = date_time_obj.strftime("%Y%m%d")
ds_de = date_time_obj.strftime("%Y.%m.%d")
get_naver_news_info_from_selenium(keyword=keyword, save_path=f"{save_path}/{keyword}/{target_date}_{keyword}_.xlsx", target_date=target_date, ds_de=ds_de, remove_duplicate=False)그렇게 만든 코드로 키워드, 날짜를 입력하면 그만큼 크롤링을 해주는 코드를 작성했습니다.
keywords = ['틴더', '토스', '야놀자', '당근마켓', '아프리카tv', '온플법', '매치그룹']
save_path = "./naver_news_article_2022
for keyword in keywords:
os.makedirs(f"{save_path}/{keyword}")그리고 원하는 키워드와 결과를 저장할 경로를 설정한 다음 경로/키워드 로 디렉토리를 생성합니다.
for keyword in keywords:
print(f"start keyword - {keyword} crawling ...")
crawl_news_data(keyword=keyword, year=2022, month=1, start_day=1, end_day=13, save_path=save_path)그 다음 원하는 기간과 저장 경로를 입력하여 크롤링을 시작합니다.
위의 경우에는 2022년 1월 1일 부터 13일까지의 값을 크롤링하는 경우입니다.
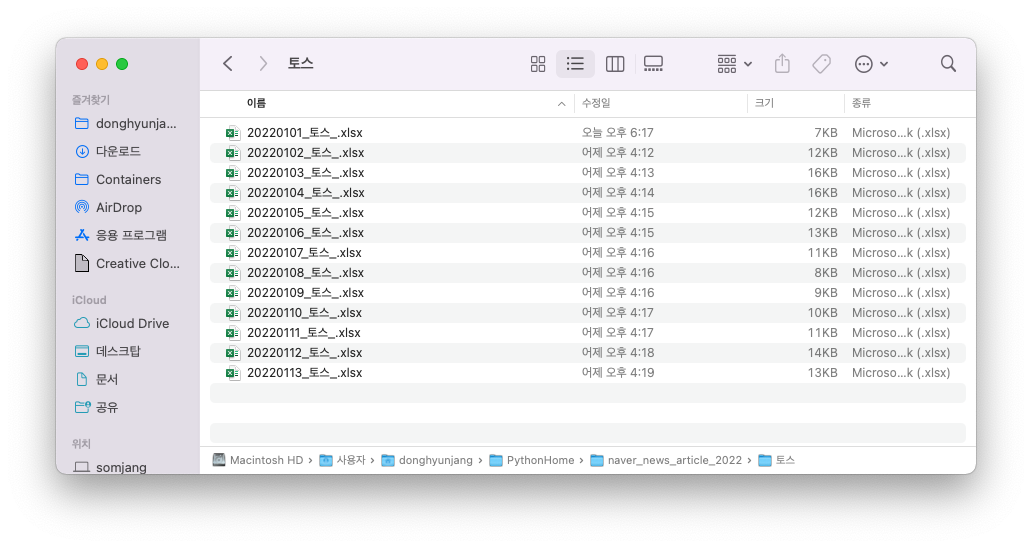
크롤링을 하면 위와 같이 날짜별로 크롤링이 되는 것을 볼 수 있습니다.
나는 한번에 합쳐진 값을 보고싶다! 한다면
import pandas as pd
import glob
import os
def merge_excel_files(file_path, file_format, save_path, save_format, columns=None):
merge_df = pd.DataFrame()
file_list = file_list = [f"{file_path}/{file}" for file in os.listdir(file_path) if file_format in file]
for file in file_list:
if file_format == ".xlsx":
file_df = pd.read_excel(file)
else:
file_df = pd.read_csv(file)
if columns is None:
columns = file_df.columns
temp_df = pd.DataFrame(file_df, columns=columns)
merge_df = merge_df.append(temp_df)
if save_format == ".xlsx":
merge_df.to_excel(save_path, index=False)
else:
merge_df.to_csv(save_path, index=False)
if __name__ == "__main__":
for keyword in keywords:
merge_excel_files(file_path=f"/Users/donghyunjang/PythonHome/naver_news_article_2022/{keyword}", file_format=".xlsx",
save_path=f"/Users/donghyunjang/PythonHome/naver_news_article_2022/{keyword}/20220101~20220113_{keyword}_네이버_기사.xlsx", save_format=".xlsx")위의 코드로 합병을 시켜주면 됩니다.
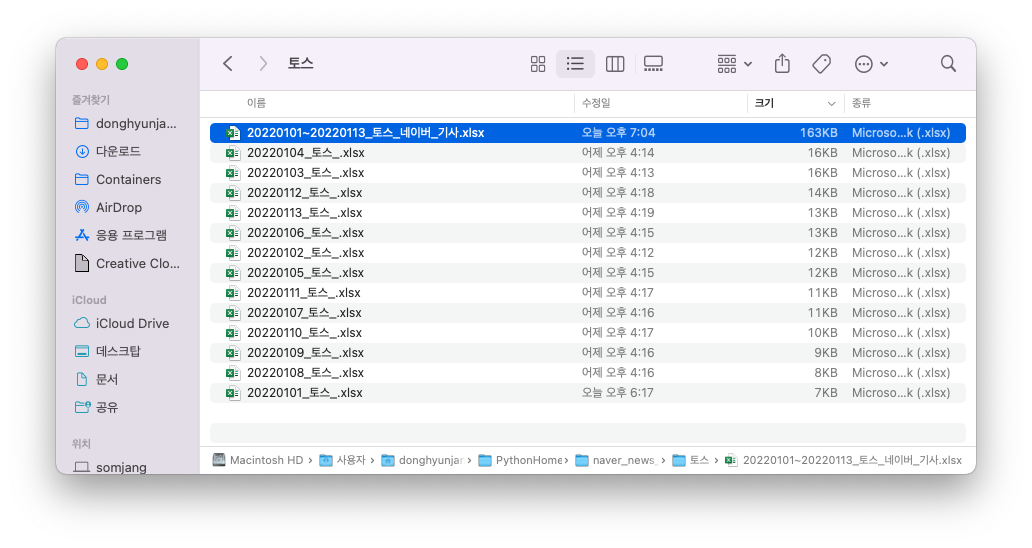
그럼 위와 같이 합병되는 것을 볼 수 있습니다.
🙂 최종 결과
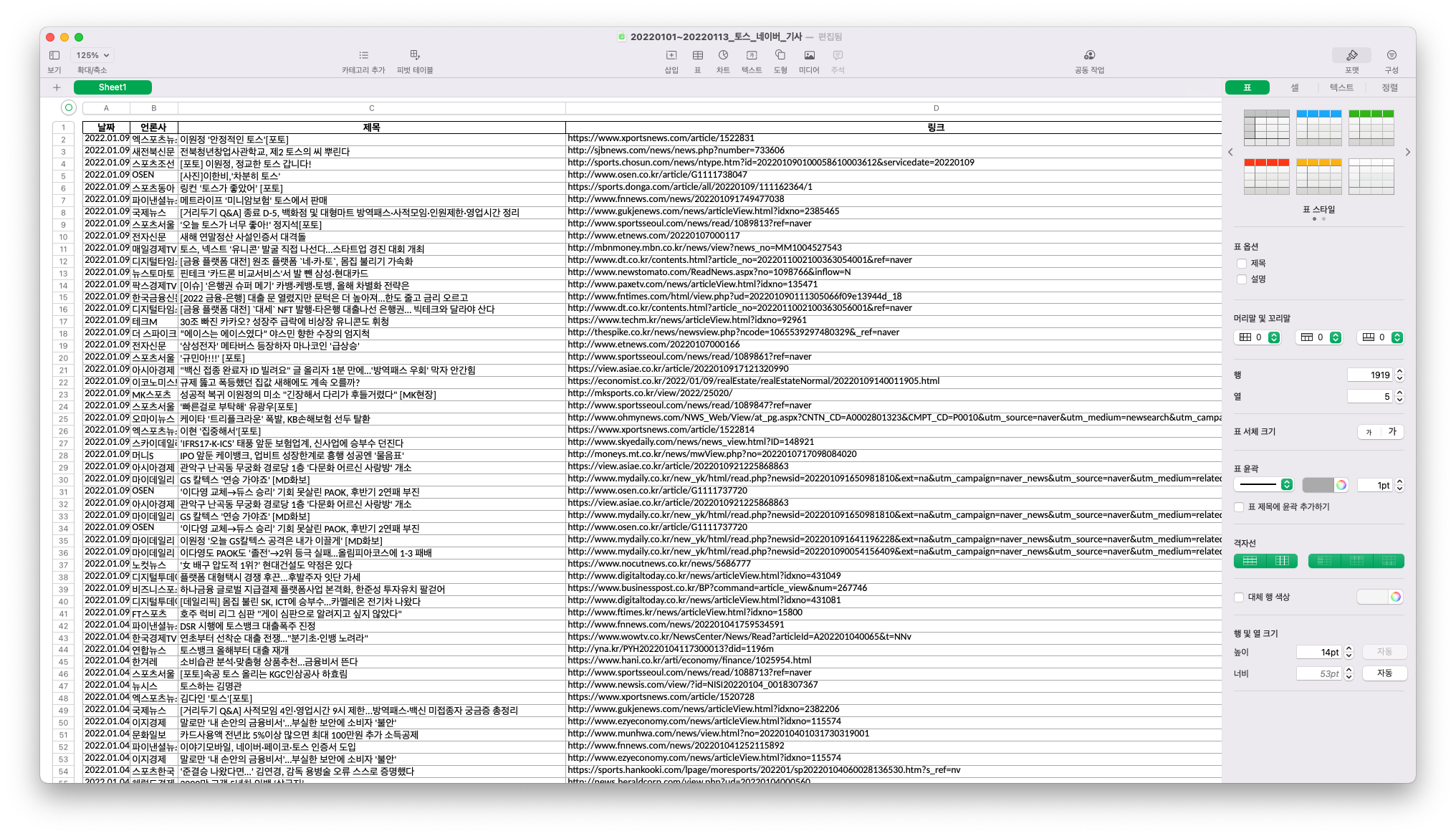
읽어주셔서 감사합니다.



