
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Kaggle
- hackerrank
- SW Expert Academy
- 캐치카페
- 파이썬
- PYTHON
- 맥북
- Git
- 프로그래머스
- Baekjoon
- 편스토랑 우승상품
- 코로나19
- programmers
- 금융문자분석경진대회
- 데이콘
- gs25
- 프로그래머스 파이썬
- 우분투
- 백준
- dacon
- 편스토랑
- Docker
- 자연어처리
- AI 경진대회
- leetcode
- Real or Not? NLP with Disaster Tweets
- github
- ubuntu
- 더현대서울 맛집
- ChatGPT
- Today
- Total
솜씨좋은장씨
[DACON] 소설 작가 분류 AI 경진대회 1, 2, 3일차! 본문

소설 작가 분류 AI 경진대회
출처 : DACON - Data Science Competition
dacon.io
DACON에서 금융문자 분석 경진대회 이후 오랜만에 NLP대회가 열렸습니다.
이 글에서는 첫날, 두번째날, 세번째날 시도해본 내용을 적어보려합니다.
이 3일간에는 별다른 EDA 없이
그저 기존에 해보던 방법과 베이스라인을 참고하고 간단한 전처리만 활용하여 시도해보았습니다.
개발환경은 NIPA에서 지원받은 GPU서버를 활용하여 진행하였습니다.
먼저 첫 날!
import pandas as pd
train_dataset = pd.read_csv("./train.csv")
test_dataset = pd.read_csv("./test_x.csv")먼저 제공받은 학습데이터를 pandas를 활용하여 불러왔습니다.
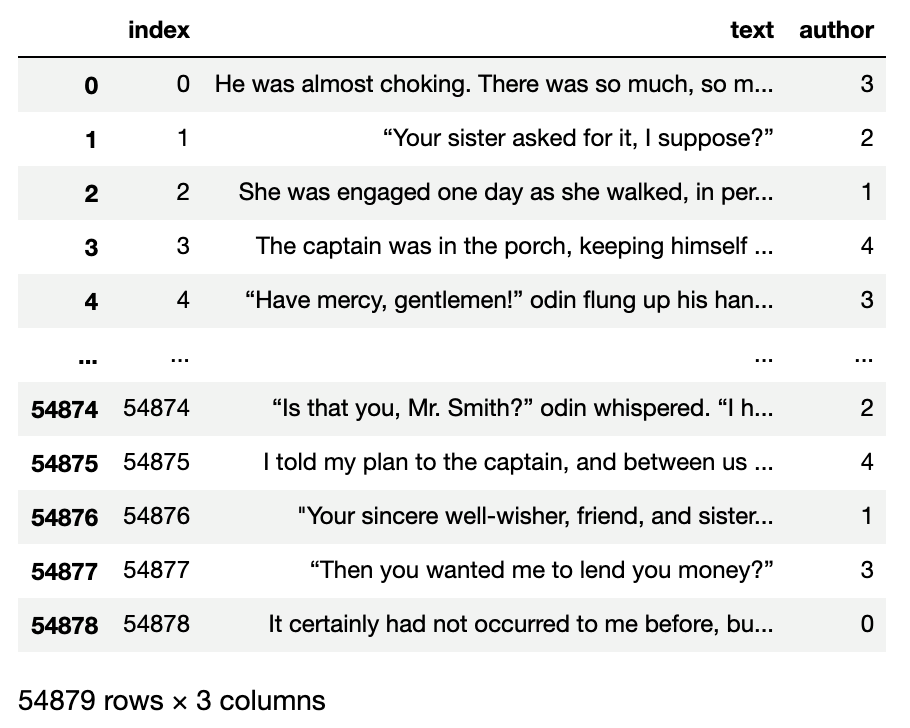

train 데이터는 각 row의 index, 본문 text, 예측해야하는 정답이라고 할 수 있는 author ( 0 ~ 4 ) 로 구성되어있습니다.
from tqdm import tqdm
import re
def get_clean_text_list(data_df):
plain_text_list = list(data_df['text'])
clear_text_list = []
for i in tqdm(range(len(plain_text_list))):
plain_text = plain_text_list[i]
clear_text = plain_text.replace("\\", "").replace("\n", "")
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'\“\”…》]', '', clear_text)
clear_text_list.append(clear_text)
return clear_text_list그 다음 각 row의 text에서 특수문자를 제거하는 함수를 하나 만들어 주었습니다.
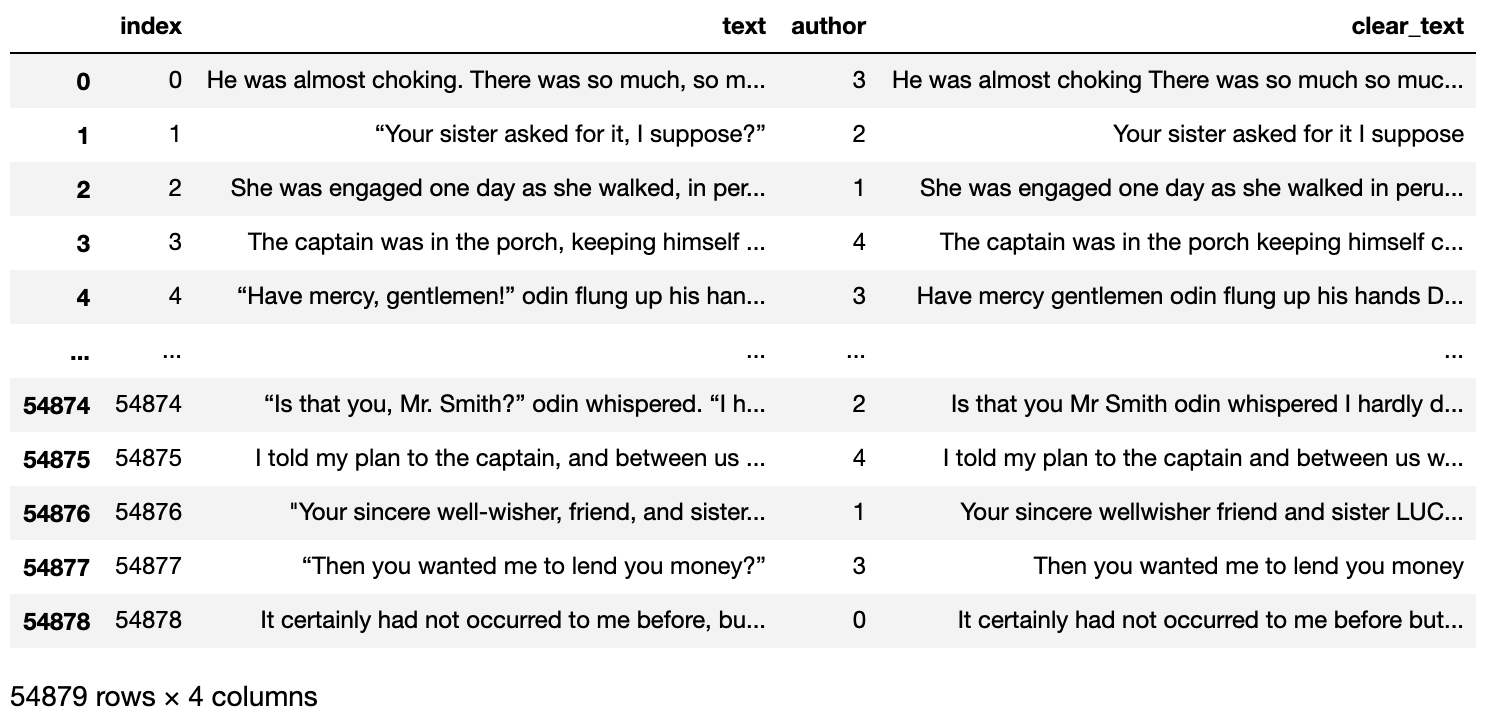
train_dataset['clear_text'] = get_clean_text_list(train_dataset)
test_dataset['clear_text'] = get_clean_text_list(test_dataset)
그 함수를 바탕으로 특수문자를 제거한 text 리스트를 만들고 train, text에 새로운 clear_text column을 만들어 넣어줍니다.

이제 주어진 영어데이터를 토크나이징하고 불용어처리를 위해 활용할 nltk 라이브러리를 import 하고 활용합니다.
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
nltk.download("punkt")
stopwords_list = stopwords.words('english')from nltk.tokenize import word_tokenize
X_train = []
train_clear_text = list(train_dataset['clear_text'])
for i in tqdm(range(len(train_clear_text))):
temp = word_tokenize(train_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)X_test = []
test_clear_text = list(test_dataset['clear_text'])
for i in tqdm(range(len(test_clear_text))):
temp = word_tokenize(test_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_test.append(temp)아까 특수문자를 제거하고 만든 clear_text에서 본문을 가져와서 nltk를 활용하여 tokenizing 한 뒤
tokenizing 한 token와 nltk에서 다운로드 받은 불용어를 활용하여 불용어 처리를 진행하였습니다.
또 불용어까지 제거된 token 중에서 길이가 2이상인 token들만 남겨 활용했습니다.
( 그런데! 나중에 제출하고 돌아보니! 불용어 리스트는 소문자로 만들어진 단어들로 되어있었고 token들은 대문자와 소문자가 섞인 단어들로 구성되어있어 제대로 불용어 처리가 안된 것을 알게되었습니다. )
from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 224
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)import numpy as np
y_train = []
labels = list(train_dataset['author'])
for i in tqdm(range(len(labels))):
if labels[i] == 0:
y_train.append([1, 0, 0, 0, 0])
elif labels[i] == 1:
y_train.append([0, 1, 0, 0, 0])
elif labels[i] == 2:
y_train.append([0, 0, 1, 0, 0])
elif labels[i] == 3:
y_train.append([0, 0, 0, 1, 0])
elif labels[i] == 4:
y_train.append([0, 0, 0, 0, 1])
y_train = np.array(y_train)그 다음 각 데이터를 tensorflow.keras.preprocessing.text의 Tokenizer를 활용하여 정수 인코딩을 하였습니다.
몇 개의 단어를 활용할 지 max_words를 활용하여 설정하여 줍니다.
( 여기서도 총 단어의 개수가 약 4만 6천개 정도 였는데 실수로 224개로 작성하였습니다. )
우리가 예측해야하는 값인 author는 One-Hot 인코딩을 진행합니다.
One-Hot 인코딩은 위의 방법으로 진행하여도 되고 to_categorical이라는 메소드를 활용하여도 됩니다.
import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train))/ len(X_train))
plt.hist([len(s) for s in X_train], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()
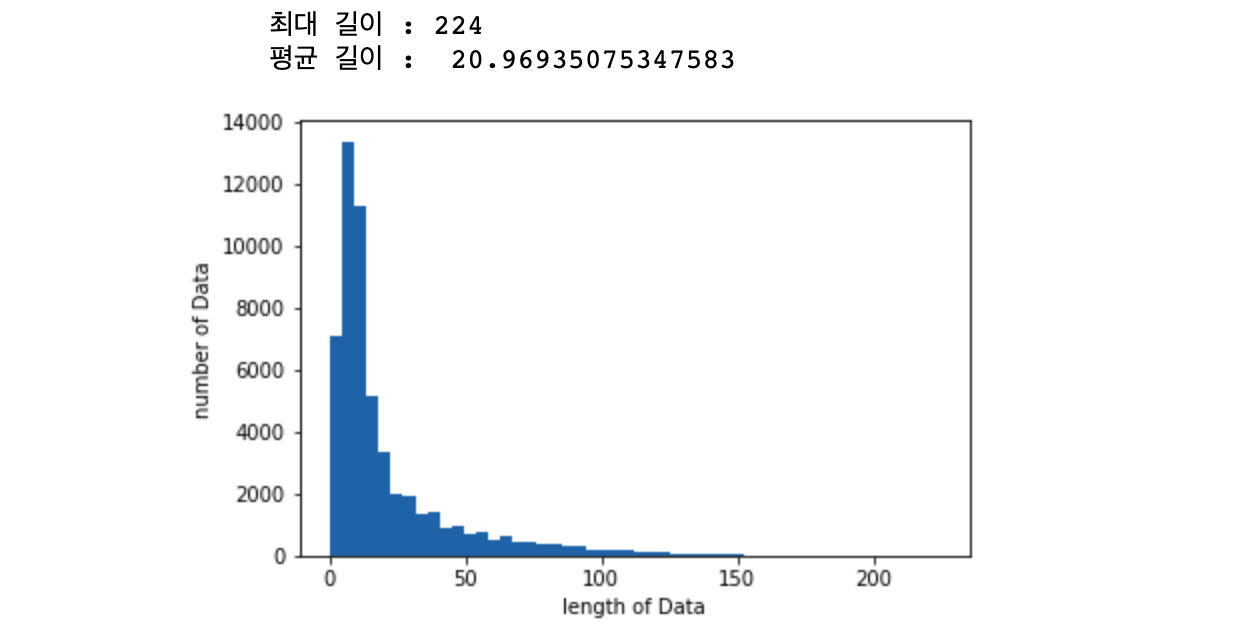
주어진 데이터 text의 최대 길이는 224, 평균길이는 20 인 것을 확인합니다.
저는 평균길이인 20.9를 반올림한 21과 tensorflow.keras.preprocessing.sequence의 pad_sequences를 가지고
모든 데이터의 길이를 21로 맞추어 주었습니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len = 21
X_train_vec = pad_sequences(X_train_vec, maxlen=max_len)
X_test_vec = pad_sequences(X_test_vec, maxlen=max_len)
그 다음 Embedding레이어, LSTM레이어, Dropout레이어를 활용하여 모델을 만들고 학습시킨 뒤
결과를 도출 해보았습니다.
Epoch 10
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dropout, Dense
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(Dense(5, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history = model.fit(X_train_vec, y_train, epochs=10, batch_size=32, validation_split=0.1)Epoch 1/10
1544/1544 [==============================] - 8s 5ms/step - loss: 1.2722 - accuracy: 0.4765 - val_loss: 1.2106 - val_accuracy: 0.5087
Epoch 2/10
1544/1544 [==============================] - 7s 5ms/step - loss: 1.2043 - accuracy: 0.5115 - val_loss: 1.1871 - val_accuracy: 0.5144
...
Epoch 9/10
1544/1544 [==============================] - 7s 5ms/step - loss: 1.1081 - accuracy: 0.5488 - val_loss: 1.1739 - val_accuracy: 0.5233
Epoch 10/10
1544/1544 [==============================] - 7s 5ms/step - loss: 1.0896 - accuracy: 0.5595 - val_loss: 1.1789 - val_accuracy: 0.5215Epoch 30
model2 = Sequential()
model2.add(Embedding(max_words, 100))
model2.add(LSTM(128))
model2.add(Dropout(0.2))
model2.add(Dense(5, activation='softmax'))
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history2 = model2.fit(X_train_vec, y_train, epochs=30, batch_size=32, validation_split=0.1)Epoch 1/30
1544/1544 [==============================] - 8s 5ms/step - loss: 1.2765 - accuracy: 0.4777 - val_loss: 1.2176 - val_accuracy: 0.5038
Epoch 2/30
1544/1544 [==============================] - 8s 5ms/step - loss: 1.2042 - accuracy: 0.5109 - val_loss: 1.1965 - val_accuracy: 0.5164
...
Epoch 29/30
1544/1544 [==============================] - 7s 5ms/step - loss: 0.6601 - accuracy: 0.7387 - val_loss: 1.6977 - val_accuracy: 0.4891
Epoch 30/30
1544/1544 [==============================] - 7s 5ms/step - loss: 0.6467 - accuracy: 0.7452 - val_loss: 1.7241 - val_accuracy: 0.4862Epoch 50
model3 = Sequential()
model3.add(Embedding(max_words, 100))
model3.add(LSTM(128))
model3.add(Dropout(0.2))
model3.add(Dense(5, activation='softmax'))
model3.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history3 = model3.fit(X_train_vec, y_train, epochs=50, batch_size=32, validation_split=0.1)Epoch 1/50
1544/1544 [==============================] - 8s 5ms/step - loss: 1.2716 - accuracy: 0.4778 - val_loss: 1.2093 - val_accuracy: 0.5029
Epoch 2/50
1544/1544 [==============================] - 7s 5ms/step - loss: 1.2043 - accuracy: 0.5102 - val_loss: 1.1950 - val_accuracy: 0.5164
...
Epoch 49/50
1544/1544 [==============================] - 7s 5ms/step - loss: 0.5075 - accuracy: 0.8025 - val_loss: 2.0920 - val_accuracy: 0.4787
Epoch 50/50
1544/1544 [==============================] - 7s 5ms/step - loss: 0.4999 - accuracy: 0.8055 - val_loss: 2.0553 - val_accuracy: 0.4891
결과 도출
model1_result = model.predict(X_test_vec)
model2_result = model2.predict(X_test_vec)
model3_result = model3.predict(X_test_vec)sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model1_result
sub_df.to_csv("submission_01.csv", index=False)
sub_df[['0','1','2','3','4']] = model2_result
sub_df.to_csv("submission_02.csv", index=False)
sub_df[['0','1','2','3','4']] = model3_result
sub_df.to_csv("submission_03.csv", index=False)
DACON 제출 결과

위에서 전처리하는 과정에서 잘못을 해서 그런지 아니면 LSTM 레이어가 맞지 않았던 것인지
아니면 너무 많은 Epoch를 진행하여 overfitting이 일어난 것인지
학습 횟수가 많아 질 수록 더 좋은 결과가 나오지 못했습니다.
첫날 최고의 결과는! 1.072109067
두번째 날!
먼저 첫날 발견한 불용어를 제거할 때 대문자 소문자가 섞여있는 데이터에서 불용어처리를 하는 실수를 수정하였습니다.
def get_clean_text_list(data_df):
plain_text_list = list(data_df['text'])
clear_text_list = []
for i in tqdm(range(len(plain_text_list))):
plain_text = plain_text_list[i].lower()
clear_text = plain_text.replace("\\", "").replace("\n", "")
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'\“\”…》]', '', clear_text)
clear_text_list.append(clear_text)
return clear_text_list그래서 특수문자를 제거하는 함수에서 특수문자를 제거하기 전에 모든 문자를 소문자로 변경해주었습니다.
train_dataset['clear_text'] = get_clean_text_list(train_dataset)
test_dataset['clear_text'] = get_clean_text_list(test_dataset)import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stopwords_list = stopwords.words('english')
X_train = []
train_clear_text = list(train_dataset['clear_text'])
for i in tqdm(range(len(train_clear_text))):
temp = word_tokenize(train_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)
X_test = []
test_clear_text = list(test_dataset['clear_text'])
for i in tqdm(range(len(test_clear_text))):
temp = word_tokenize(test_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_test.append(temp)그 뒤에 소문자 처리해준 Token들에서 불용어를 제거해줍니다.
from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 224
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train_vec))/ len(X_train_vec))
plt.hist([len(s) for s in X_train_vec], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()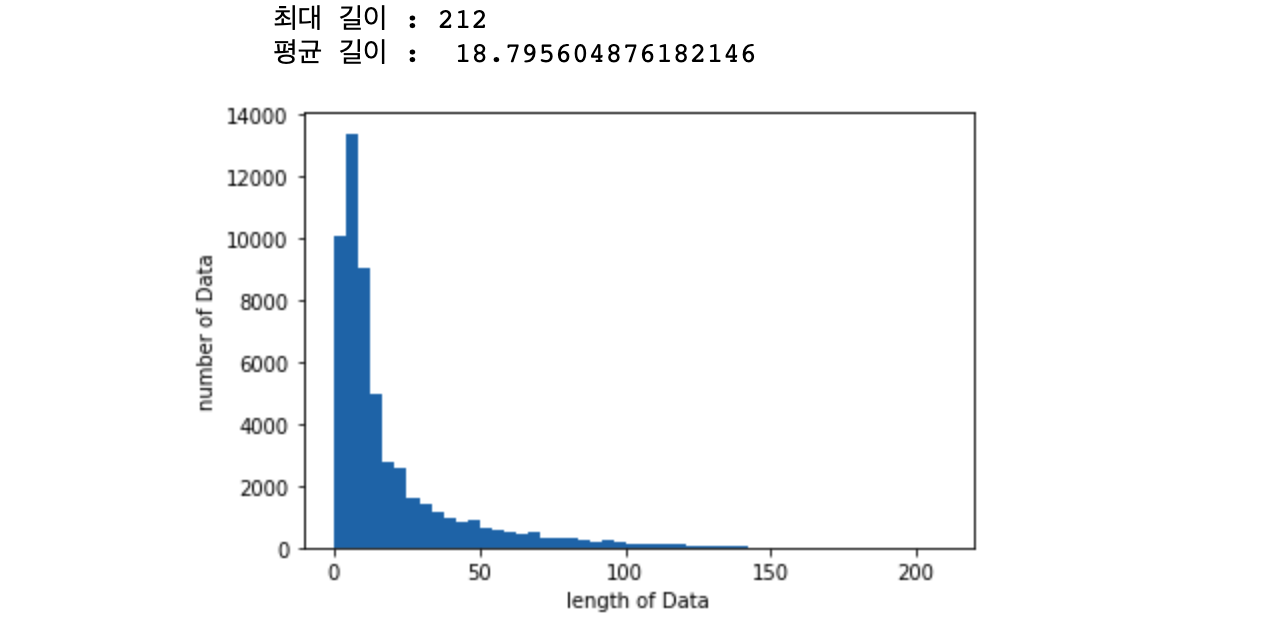
불용어 소문자 대문자는 발견하여 해결하였으나 몇개의 단어를 활용할지 정하는 max_words가 잘못된 것은
알아채지 못하고 그대로 진행하였습니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len = 19
X_train_vec = pad_sequences(X_train_vec, maxlen=max_len)
X_test_vec = pad_sequences(X_test_vec, maxlen=max_len)평균 길이는 18.79를 반올림한 19로 모든 데이터의 길이를 동일하게 바꾸어 주었습니다.
import numpy as np
y_train = []
labels = list(train_dataset['author'])
for i in tqdm(range(len(labels))):
if labels[i] == 0:
y_train.append([1, 0, 0, 0, 0])
elif labels[i] == 1:
y_train.append([0, 1, 0, 0, 0])
elif labels[i] == 2:
y_train.append([0, 0, 1, 0, 0])
elif labels[i] == 3:
y_train.append([0, 0, 0, 1, 0])
elif labels[i] == 4:
y_train.append([0, 0, 0, 0, 1])
y_train = np.array(y_train)동일하게 author 값은 One-Hot 인코딩을 시켜줍니다.
이렇게 첫날 방법에서 text를 소문자로 모두 바꿔준 뒤 불용어 처리하는 것으로 불용어 처리 방법을 바꾸어
어제의 모델에 그대로 넣어 보았습니다.
Epoch 10
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dropout, Dense
model = Sequential()
model.add(Embedding(max_words, 100))
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(Dense(5, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history = model.fit(X_train_vec, y_train, epochs=10, batch_size=32, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/10
49391/49391 [==============================] - 29s 579us/step - loss: 1.2845 - accuracy: 0.4709 - val_loss: 1.2232 - val_accuracy: 0.5004
Epoch 2/10
49391/49391 [==============================] - 26s 528us/step - loss: 1.2178 - accuracy: 0.5011 - val_loss: 1.2093 - val_accuracy: 0.5060
...
Epoch 9/10
49391/49391 [==============================] - 26s 532us/step - loss: 1.1284 - accuracy: 0.5403 - val_loss: 1.1839 - val_accuracy: 0.5190
Epoch 10/10
49391/49391 [==============================] - 26s 529us/step - loss: 1.1138 - accuracy: 0.5475 - val_loss: 1.1771 - val_accuracy: 0.5190Epoch 3
model2 = Sequential()
model2.add(Embedding(max_words, 100))
model2.add(LSTM(128))
model2.add(Dropout(0.2))
model2.add(Dense(5, activation='softmax'))
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history2 = model2.fit(X_train_vec, y_train, epochs=3, batch_size=32, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/3
49391/49391 [==============================] - 27s 547us/step - loss: 1.0092 - accuracy: 0.6030 - val_loss: 0.8149 - val_accuracy: 0.6890
Epoch 2/3
49391/49391 [==============================] - 27s 540us/step - loss: 0.6236 - accuracy: 0.7711 - val_loss: 0.8087 - val_accuracy: 0.7054
Epoch 3/3
49391/49391 [==============================] - 26s 529us/step - loss: 0.4874 - accuracy: 0.8194 - val_loss: 0.8501 - val_accuracy: 0.7024
결과 도출
model1_result = model.predict(X_test_vec)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model1_result
sub_df.to_csv("submission_04.csv", index=False)
model2_result = model2.predict(X_test_vec)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model2_result
sub_df.to_csv("submission_05.csv", index=False)
DACON 제출 결과

첫날의 결과보다 확실히 좋은 결과를 얻을 수 있었고
10번의 Epoch이 진행된 모델보다 3번의 Epoch이 진행된 모델이 더 좋은 결과가 나오는 것을 볼 수 있었습니다.
그러던 중 max_words의 값이 잘 못 되었다는 것을 알게되어 수정 후 다시 진행해보았습니다.
from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 20000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(X_train)
X_test_vec = tokenizer.texts_to_sequences(X_test)max_words 값을 기존 224에서 20,000으로 값을 변경하였습니다.
model3 = Sequential()
model3.add(Embedding(max_words, 100))
model3.add(LSTM(128))
model3.add(Dropout(0.2))
model3.add(Dense(5, activation='softmax'))
model3.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history3 = model3.fit(X_train_vec, y_train, epochs=2, batch_size=128, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/2
49391/49391 [==============================] - 8s 152us/step - loss: 1.1073 - accuracy: 0.5535 - val_loss: 0.8525 - val_accuracy: 0.6778
Epoch 2/2
49391/49391 [==============================] - 7s 138us/step - loss: 0.6450 - accuracy: 0.7631 - val_loss: 0.8064 - val_accuracy: 0.6966그리고 이번에는 2 Epoch만 학습을 진행하였습니다.
결과 도출
model3_result = model3.predict(X_test_vec)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model3_result
sub_df.to_csv("submission_06.csv", index=False)
DACON 제출 결과

둘째날 최고의 결과는! 0.723559552
첫째날에서 알게되었던 과오들을 수정하여 더 나은 결과를 낼 수 있었습니다.
하지만 아직 데이콘에서 제공해준 베이스라인 코드의 점수를 넘기지는 못하였습니다.
셋째날!
셋째날은 데이콘에서 제공해준 불용어만 가지고 와서 활용해보았습니다.
불용어 목록을 확인해보니 ' 값이 그대로 포함되어있는 리스트 였습니다.
이에 특수문자를 제거하는 함수의 정규식에서 ' 를 제거한 정규식을 사용하는 함수를 만들었습니다.
stopwords_list = [ "a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as",
"at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could",
"did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has",
"have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself",
"his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself",
"let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours",
"ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that",
"that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll",
"they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll",
"we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom",
"why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]def get_clean_text_list(data_df):
plain_text_list = list(data_df['text'])
clear_text_list = []
for i in tqdm(range(len(plain_text_list))):
plain_text = plain_text_list[i].lower()
clear_text = plain_text.replace("\\", "").replace("\n", "")
clear_text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\“\”…》]', '', clear_text)
clear_text_list.append(clear_text)
return clear_text_listtrain_dataset['clear_text'] = get_clean_text_list(train_dataset)
test_dataset['clear_text'] = get_clean_text_list(test_dataset)import nltk
from nltk.corpus import stopwords
stopwords_list = stopwords.words('english')
from nltk.tokenize import word_tokenize
import re
X_train = []
train_clear_text = list(train_dataset['clear_text'])
for i in tqdm(range(len(train_clear_text))):
temp = word_tokenize(train_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_train.append(temp)
X_test = []
test_clear_text = list(test_dataset['clear_text'])
for i in tqdm(range(len(test_clear_text))):
temp = word_tokenize(test_clear_text[i])
temp = [word for word in temp if word not in stopwords_list]
temp = [word for word in temp if len(word) > 1]
X_test.append(temp)
new_X_train = []
for i in tqdm(range(len(X_train))):
temp = []
for j in range(len(X_train[i])):
temp.append(X_train[i][j].replace("'", ""))
new_X_train.append(temp)
new_X_test = []
for i in tqdm(range(len(X_test))):
temp = []
for j in range(len(X_test[i])):
temp.append(X_test[i][j].replace("'", ""))
new_X_test.append(temp)nltk로 tokenizing 한 후 데이콘에서 가져온 불용어를 활용하여 불용어처리를 한 뒤에
각 토큰에 아직 남아있을 ' 데이터를 지워 데이터를 만들었습니다.
그리고 max_words를 설정하기위해 총 몇개의 단어가 존재하는지 확인해보았습니다.
word_list = []
for i in tqdm(range(len(X_train))):
for j in range(len(X_train[i])):
word_list.append(X_train[i][j])
len(list(set(word_list)))> 48688from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 48000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(X_train)
X_train_vec = tokenizer.texts_to_sequences(new_X_train)
X_test_vec = tokenizer.texts_to_sequences(new_X_test)( 여기서도 fit_on_texts에 new_X_train을 넣어야하는데 X_train을 잘못 넣었습니다. )
( 계속 이런 실수가 반복되는 걸 보니 앞으로 좀 시간을 더 투자하여 천천히 실수를 짚어나가며 봐야할 것 같습니다. )
import numpy as np
y_train = []
labels = list(train_dataset['author'])
for i in tqdm(range(len(labels))):
if labels[i] == 0:
y_train.append([1, 0, 0, 0, 0])
elif labels[i] == 1:
y_train.append([0, 1, 0, 0, 0])
elif labels[i] == 2:
y_train.append([0, 0, 1, 0, 0])
elif labels[i] == 3:
y_train.append([0, 0, 0, 1, 0])
elif labels[i] == 4:
y_train.append([0, 0, 0, 0, 1])
y_train = np.array(y_train)import matplotlib.pyplot as plt
print("최대 길이 :" , max(len(l) for l in X_train))
print("평균 길이 : ", sum(map(len, X_train_vec))/ len(X_train_vec))
plt.hist([len(s) for s in X_train_vec], bins=50)
plt.xlabel('length of Data')
plt.ylabel('number of Data')
plt.show()> 최대 길이 : 211
평균 길이 : 20.046174310756392from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len = 20
X_train_vec = pad_sequences(X_train_vec, maxlen=max_len)
X_test_vec = pad_sequences(X_test_vec, maxlen=max_len)Epoch 1
model3 = Sequential()
model3.add(Embedding(max_words, 100))
model3.add(LSTM(128))
model3.add(Dropout(0.2))
model3.add(Dense(5, activation='softmax'))
model3.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history3 = model3.fit(X_train_vec, y_train, epochs=1, batch_size=32, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/1
49391/49391 [==============================] - 29s 585us/step - loss: 0.9974 - accuracy: 0.6112 - val_loss: 0.8097 - val_accuracy: 0.6950Epoch 3
model2 = Sequential()
model2.add(Embedding(max_words, 100))
model2.add(LSTM(128))
model2.add(Dropout(0.2))
model2.add(Dense(5, activation='softmax'))
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history2 = model2.fit(X_train_vec, y_train, epochs=3, batch_size=32, validation_split=0.1)
결과 도출
model3_result = model.predict(X_test_vec)
model3_result = model3.predict(X_test_vec)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model3_result
sub_df.to_csv("submission_07.csv", index=False)
model2_result = model2.predict(X_test_vec)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model2_result
sub_df.to_csv("submission_08.csv", index=False)
DACON 제출 결과

위에서 fit_on_texts에서 new_X_train을 넣었어야 했지만 X_train을 넣었던 것을 바꾸어 다시 결과를 도출해보았습니다.
from tensorflow.keras.preprocessing.text import Tokenizer
max_words = 48000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(new_X_train)
X_train_vec2 = tokenizer.texts_to_sequences(new_X_train)
X_test_vec2 = tokenizer.texts_to_sequences(new_X_test)Epoch 3
model2 = Sequential()
model2.add(Embedding(max_words, 100))
model2.add(LSTM(128))
model2.add(Dropout(0.2))
model2.add(Dense(5, activation='softmax'))
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])history2 = model2.fit(X_train_vec2, y_train, epochs=3, batch_size=32, validation_split=0.1)Train on 49391 samples, validate on 5488 samples
Epoch 1/3
49391/49391 [==============================] - 30s 600us/step - loss: 0.9898 - accuracy: 0.6118 - val_loss: 0.8216 - val_accuracy: 0.6922
Epoch 2/3
49391/49391 [==============================] - 28s 572us/step - loss: 0.5709 - accuracy: 0.7925 - val_loss: 0.8016 - val_accuracy: 0.6979
Epoch 3/3
49391/49391 [==============================] - 28s 563us/step - loss: 0.4146 - accuracy: 0.8496 - val_loss: 0.8622 - val_accuracy: 0.7003
결과 도출
model2_result = model2.predict(X_test_vec2)
sub_df = pd.read_csv("./sample_submission.csv")
sub_df[['0','1','2','3','4']] = model2_result
sub_df.to_csv("submission_09.csv", index=False)
DACON 제출 결과

셋째날 최고의 결과는! 0.7002451698
첫째날 둘째날보다는 결과가 나아졌지만 자꾸 기초적인 부분들에서 실수를 하는게 조금 많이 아쉽습니다.
아직 베이스라인 점수를 뛰어넘지 못했습니다.
4일차부터는 데이터를 조금 더 뜯어보고 전처리방법과 모델을 바꾸어 도전해보려고합니다.
읽어주셔서 감사합니다!
'DACON > 소설 작가 분류 AI 경진대회' 카테고리의 다른 글
| [DACON] 소설 작가 분류 AI 경진대회 N일차! (0) | 2020.11.05 |
|---|---|
| [DACON] 소설 작가 분류 AI 경진대회 6일차! (0) | 2020.11.04 |
| [DACON] 소설 작가 분류 AI 경진대회 5일차! (0) | 2020.11.03 |
| [DACON] 소설 작가 분류 AI 경진대회 4일차! (0) | 2020.11.02 |
| [DACON] 소설 작가 분류 AI 경진대회 도전! (0) | 2020.10.31 |



